







在分布式开发中,我们将每一一种服务都抽取成一个独立的模块,微服务模块在真正的上线之前,甚至是上线以后,我们都要进行压力测试,才能投入正常的使用。
压力测试是为了我们的系统在当前软硬件环境下,最大的负荷量,也就是系统瓶颈。
知道了系统瓶颈,就可以通过一些负载均衡配置,避免给系统在单位时间内发送太多的请求,导致系统被压垮,以至于宕机。
同时压测也是我们优化的一个重要手段,使用压力测试,我们有希望找到很多种用其他测试方法更难发现的错误。有两种错误类型是:内存泄漏,并发与同步。
- 内存泄漏:调用的接口在一个很多次的循环内不断的创建对象,当并发达到百万的时候,就会创建很多对象,以至于内存撑爆
性能指标
-
响应时间(Response Time: RT)
响应时间指用户从客户端发起一个请求开始,到客户端接收到从服务器端返回的响应结束,整个过程所耗费的时间。 -
HPS(Hits Per Second) :每秒点击次数,单位是次/秒。
-
TPS(Transaction per Second):系统每秒处理交易数,单位是笔/秒。
可以理解为一个事务,不仅仅是数据库的事务,例如下单需要库存、购物车、计算价格等等,全部完成,则为一个事务。 -
QPS(Query per Second):系统每秒处理查询次数,单位是次/秒。
对于互联网业务中,如果某些业务有且仅有一个请求连接,那么 TPS=QPS=HPS,一般情况下用 TPS 来衡量整个业务流程,用 QPS 来衡量接口查询次数,用 HPS 来表示对服务器单击请求。
无论 TPS、QPS、HPS,此指标是衡量系统处理能力非常重要的指标,越大越好,根据经验,一般情况下:
- 金融行业:1000TPS~50000TPS,不包括互联网化的活动(秒杀)
保险行业:100TPS~100000TPS,不包括互联网化的活动
制造行业:10TPS~5000TPS
互联网电子商务:10000TPS~1000000TPS
互联网中型网站:1000TPS~50000TPS
互联网小型网站:500TPS~10000TPS
最大响应时间(Max Response Time) 指用户发出请求或者指令到系统做出反应(响应)的最大时间。
最少响应时间(Mininum ResponseTime) 指用户发出请求或者指令到系统做出反应(响应)的最少时间。
90%响应时间(90% Response Time) 是指所有用户的响应时间进行排序,第 90%的响应时间。
从外部看,性能测试主要关注如下三个指标
- 吞吐量:每秒钟系统能够处理的请求数、任务数(QPS、TPS)。
响应时间:服务处理一个请求或一个任务的耗时。
错误率:一批请求中结果出错的请求所占比例。
jmeter
官网下载二进制文件
线程组
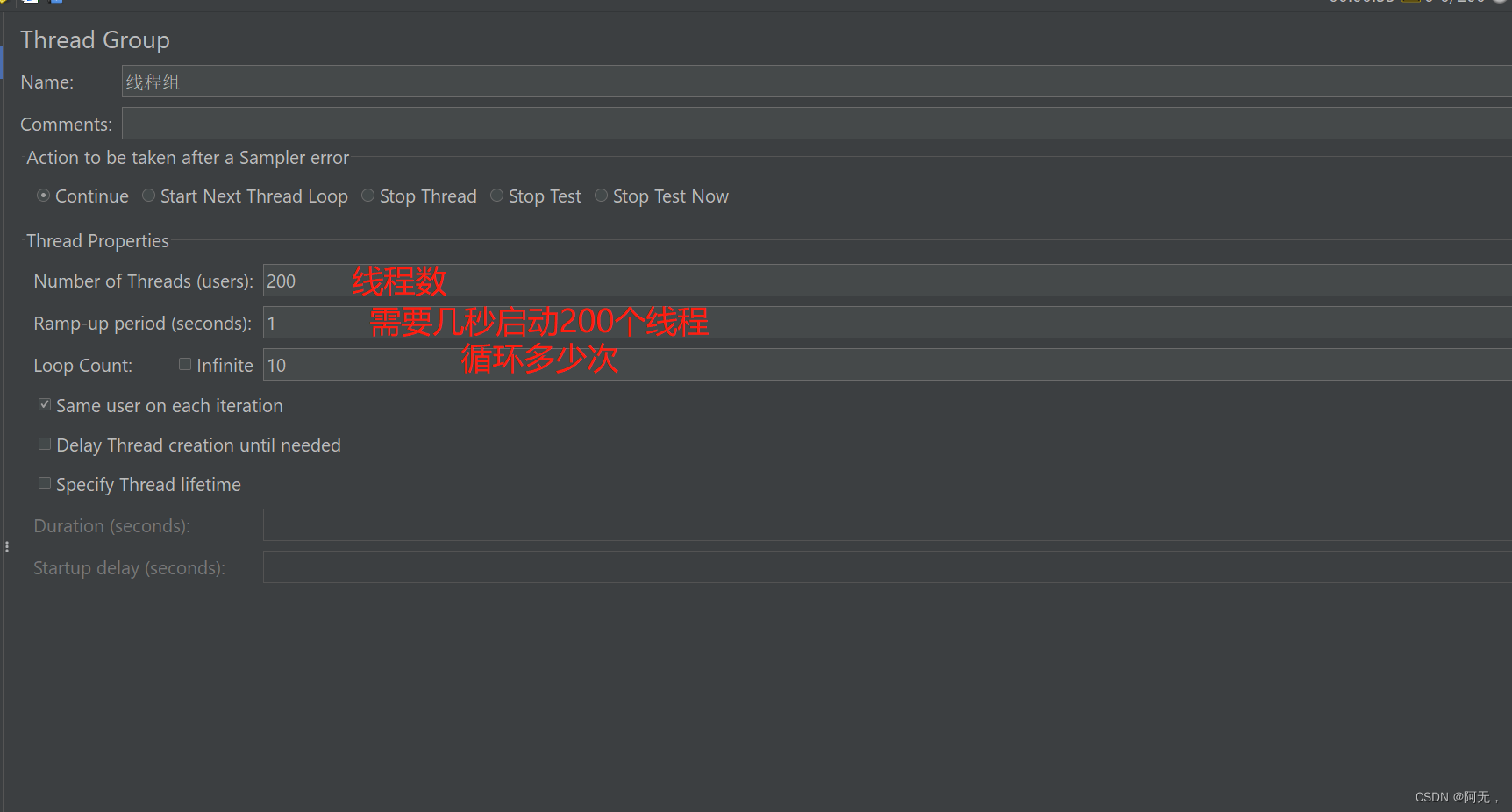
JMeter Address Already in use 错误解决
windows 本身提供的端口访问机制的问题。
Windows 提供给 TCP/IP 链接的端口为 1024-5000,并且要四分钟来循环回收他们。就导致我们在短时间内跑大量的请求时将端口占满了。
- cmd 中,用 regedit 命令打开注册表
- HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters 下,
- 右击 parameters,添加一个新的 DWORD,名字为 MaxUserPort
- 然后双击 MaxUserPort,输入数值数据为 65534,基数选择十进制(如果是分布式运行的话,控制机器和负载机器都需要这样操作哦)
- TCPTimedWaitDelay:30(操作和2一样)
- 修改配置完毕之后记得重启机器才会生效
https://support.microsoft.com/zh-cn/help/196271/when-you-try-to-connect-from-tcp-ports-greater-than-5000-you-receive-t
性能优化
我们使用jmeter对接口做了压测,可以得到这个接口的一些性能报告,我们通过衡量这些性能报告,就能知道这个接口有没有符合我们的性能要求,如果不符合,我们就要对接口进行优化。
优化需要考虑多方面:
- 数据库、应用程序(我们的项目)、中间件(tomcat、nginx)、网络和操作系统等方面
- 自己的应用属于
- cpu密集型(cpu用的多,大量的计算)
我们查到了一堆数据,需要计算、排序、过滤、整合等等 - 还是io密集型(网络io,磁盘io,数据库io,redis io)。
- cpu密集型(cpu用的多,大量的计算)
性能优化主要在应用程序方面主要是优化我们项目接口的代码编写方式和jvm的堆,可以看java虚拟机的1.1.1 堆空间内存分配(默认情况下)
jvm性能监控我们用的是jdk自带的jvisualvm(dos窗口敲jvisualvm即可启动)
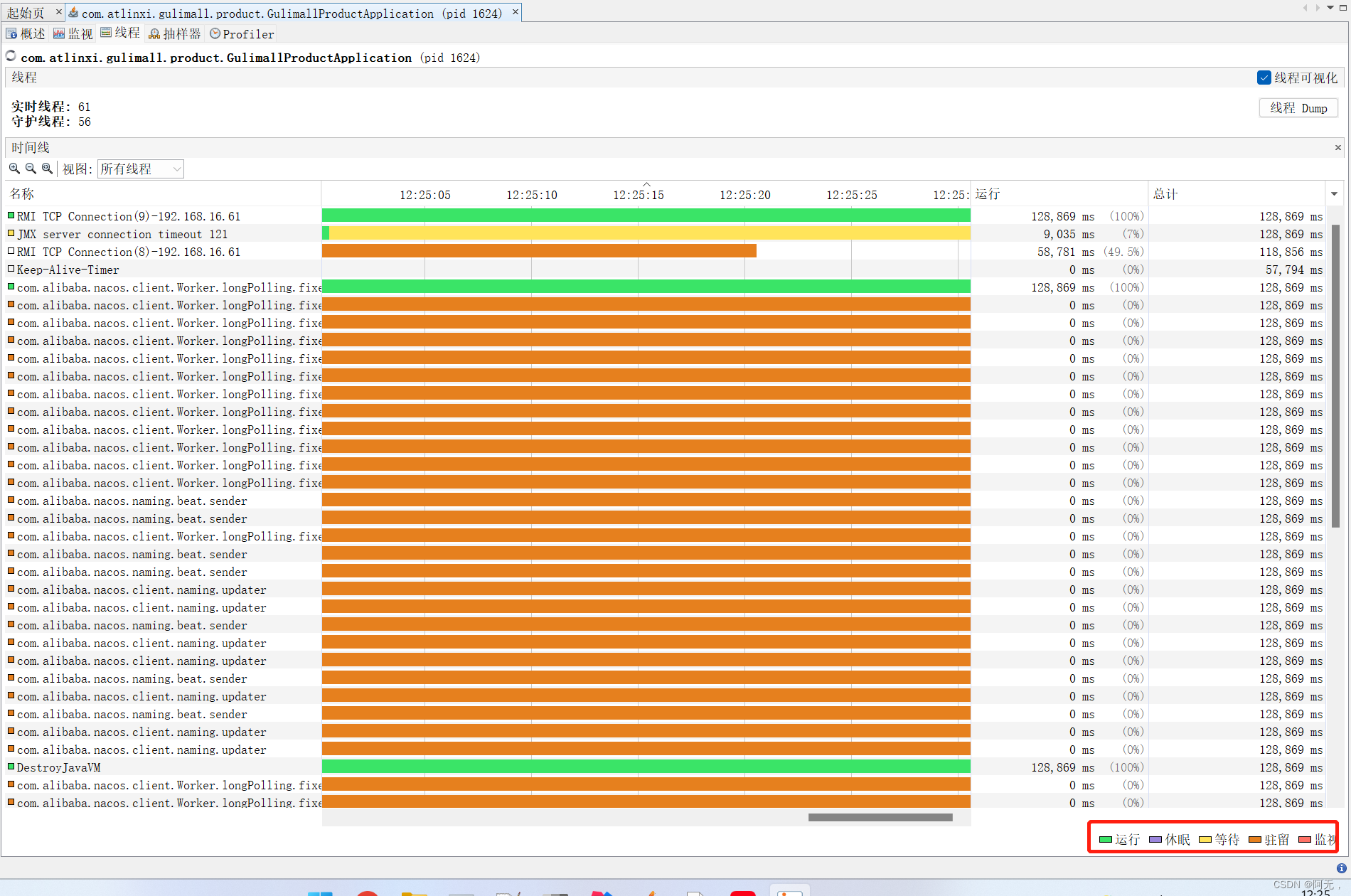
休眠:调用了sleep的线程
等待:使用了wait,等待被唤醒
驻留:线程池里空闲的线程
监视:几个线程发生了锁的竞争(阻塞的线程),正在等待锁的释放
jvisualvm需要安装一个插件,在工具-插件可用插件中,需要更新一下插件中心的地址,地址在这个地址找,https://visualvm.github.io/,但是win11怎么都打不开这个地址,我试过改dns、hosts,都不行,最后,我选择的是离线安装。
很奇怪,QQ浏览器是可以打开上面那个地址的,然后下载对应jdk版本的visual gc,然后在jvisualvm已下载中添加插件进行安装,重启jvisualvm。
开始压测
- 虚拟机环境
cpu2核,内存3G - 本地环境
win11,i5-12500H,16核,16g - product服务和gateway服务100m
以下压测数据只能做一个参照标准,因为我们的压测和服务是在同一个机器,同时压测的话肯定会线程竞争,如果可以拿另外一台机器来请求进行压测,那就是相对于更标准的数据了。
…:数据有点儿离谱,不具有参考价值
| 压测内容 | 压测线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 | 压测路径 |
|---|---|---|---|---|---|
| nginx | 50 | 3581 | 19 | 52 | 192.168.56.10:80 |
| gateway | 50 | 23448 | 4 | 12 | 127.0.0.1:88 |
| 简单服务 | 50 | 43525 | 2 | 5 | 127.0.0.1:12000/hello |
| gateway+简单服务 | 50 | 9637 | 8 | 13 | 127.0.0.1:88/hello |
| 全链路(gateway+简单服务+nginx) | 50 | 1867 | 55 | 77 | gulimall.com/hello |
| 首页一级菜单渲染 | 50 | 190(mysql,thymeleaf) | 376 | 663 | 127.0.0.1:12000 |
| 首页一级菜单渲染(thymeleaf开缓存) | 50 | 232 | 306 | 514 | 127.0.0.1:12000 |
| 首页一级菜单渲染(thymeleaf开缓存,优化数据库(加索引),关日志) | 50 | 528 | 150 | 414 | 127.0.0.1:12000 |
| 三级分类数据获取 | 50 | 4(mysql) /8(上一行优化后的) | 。。。 | 。。。 | 127.0.0.1:12000/index/catalog.json |
| 三级分类数据获取(优化业务,只与数据库交互一次) | 50 | 112 | 571 | 896 | 127.0.0.1:12000/index/catalog.json |
| 三级分类数据获取(使用redis作为缓存) | 50 | 463 | 121 | 157 | 127.0.0.1:12000/index/catalog.json |
| 首页全量数据获取 | 50 | 15(静态资源) | 127.0.0.1:12000 | ||
| nginx+gateway | 50 |
-
nginx是浪费cpu,,不浪费内存
它总是把请求转交,它不需要创建对象,自然不需要多大的内存,
它更多的是拥有更多的线程接收请求来处理,所以cpu来回在线程之间切换计算 -
gateway也是浪费cpu,和nginx的道理类似
在压测gateway的同时我们打开jvisualvm,观察
visual gc,我们发现Eden区内存只有32m,非常小,所以gc次数很多,花费很多不必要的时间,所以我们可以调整Eden区的大小,就会减少gc的时间,吞吐量就会增加 -
简单服务就是在product模块写个返回hello字符串的请求,压测这个路径
gateway product_route断言需要新增/hello -
通过简单服务和简单服务+gateway压测的对比,中间件越多,性能损失越大,大多都损失在网络交互。考虑优化的话,中间件的效率要提高,它们之间的传输效率要提高(用更好的网卡,使用更高效率的传输协议等)
-
我们发现每过一个中间件,我们的响应时间都会加一点儿,虽然只有50ms,但是对于大并发计算机来说,累积效应起来,吞吐量就会损失很多。
首页全量数据获取是将数据库的资源请求,渲染html都算在其中,在Jmeter的HTTP请求高级勾选从HTML文件获取所有内含的资源
我们发现首页全量数据获取和首页全量数据获取多了静态资源,从业务角度,我们需要优化:
- db(mysql优化)
- 模板的渲染速度
模板渲染是浪费cpu的,cpu要计算,要插值,要把内存中的数据最终组装起来 - 静态资源
如果静态资源是放在微服务模块中,静态资源的获取是由tomcat来处理的,静态资源会剥夺很多的线程,整个吞吐量就会下去很多。
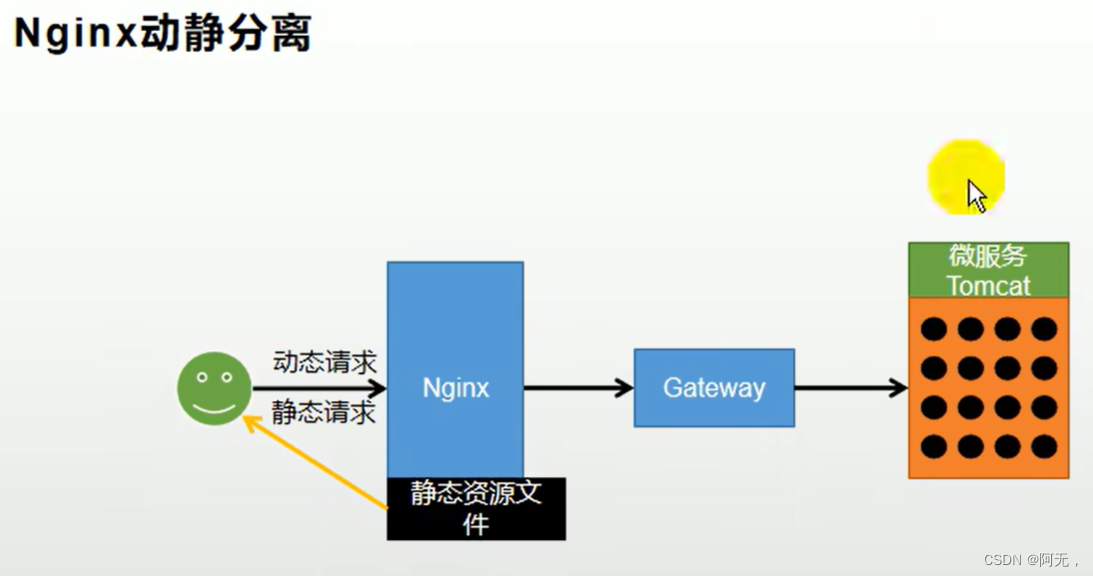
nginx动静分离
我们之前是将所有的请求,无论是动态请求还是静态请求,都是tomcat来处理的,那就会占用很多资源,所以吞吐量很低。
我们之前是将静态资源放在微服务中,现在我们将静态资源放在nginx中,动态请求nginx会将请求转交给网关,网关再交给微服务;静态资源由nginx直接返回。
-
以后将所有项目的静态资源都应该放在nginx里面
将product模块resources/static文件夹下的index文件夹全部上传到虚拟中的/mydata/nginx/html/static/路径下 -
规则:/static/**所有请求都由nginx直接返回
修改product模块resources/templates下的index.html,全部替换,href=“,href=”/static/,<script src=“,<script src=”/static/,<img src=“,<img src=”/static/,src=“index,src=”/static/index
修改完之后,我们再访问首页,图片的地址应该是http://127.0.0.1:12000/static/index/img/section_second_list_img8.jpg- 修改nginx配置文件 /mydata/nginx/conf/conf.d/gulimall.conf
server {
listen 80;
server_name gulimall.com;
#charset koi8-r;
#access_log /var/log/nginx/log/host.access.log main;
# 如果请求路径是 /static,就请求nginx中的静态资源
location /static/ {
root /usr/share/nginx/html;
}
# 如果请求路径是/,就请求http://gulimall
location / {
proxy_set_header Host $host;
proxy_pass http://gulimall;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
内存崩溃宕机异常
我们把jmeter线程调到200,发现不管是年轻代还是老年代的内存都爆满了,不久后tomcat线程会报异常了,内存溢出java.lang.OutofMemoryError:Java heap space等等,当我们再次访问首页时就会报找不到gulimall-product实例,这就是线上服务崩溃的整个过程。
我们持续在运行期间cpu内存爆满卡死,将我们应用挤下线,我们应用不能提供正常服务。
我们调整本地的运行内存,idea更改vm options -Xmx1024m -Xms1024m -Xmn512m
这样一来,一周就少了两天见到她们,喂伤痕累累的她以精神食粮的,她可爱的小女人们。
房思琪的初恋乐园
林奕含















 2102
2102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









