







0.什么是特征工程:
业界广泛流传——“数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,这里的数据指的就是经过特征工程得到的数据。
- 特征工程是使用专业背景知识和技巧处理数据,似的特征能在机器学习算法上发挥更好作用的过程;
- 意义:直接影响机器学习的效果;
- 特征工程包含的内容:特征提取,特征预处理,特征降维
1.特征提取:
sklearn.feature_extraction
将数据(文本/图像)转换成机器学习可以处理,理解的数值类型:
- 字典特征提取:

- 文本特征提取:

stop_words :停用词,去掉不要的词不参与数值化
- 中文文本特征提取:

2.特征预处理
API :sklearn.preprocessing
- 数值型需要数据的无量纲化:归一化,标准化
- 意义: 特征的大小相差较大,容易影响目标结果,使得一些特征的作用很小,需要使用无量纲化;
归一化:
- 通过对原始数据进行变换,使得数据映射到默认区间 [0,1】;
- **缺陷:**处理异常值过多不适合,只适合精确小的数据
- 公式原理:例如:特征1 里面的75
- x’ =(75-60)/(90-60) =0.5
- x"= 0.5 * (1-0) + 0 = 0.5
- 75 ==> 0.5

- 归一化API使用:

标准化
- 定义:把原始数据变换成 均值为0,标准差为1的范围内
- 公式: 也是作用于每一列,mean为均值,σ为标准差
- 意义:相比较归一化来说,出现异常值,会影响最大值和最小值,归一化会严重影响;而对于标准化,如果出现异常值,只要具有一定的数据量,少量的异常点并不会对平均值造成影响,而方差改变也较小;
- 适用场景:推荐使用;在样本较多的情况下,适合现代嘈杂的大数据场景;
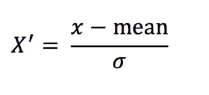
标准化API使用:

3.特征降维:
- 定义:在某些限定条件下,降低特征个数,得到一组不相关特征的过程;如果相关会对算法学习预测造成影响;
- 主要分为两种:特征选择,主成分分析
1>特征选择
-
方法:Filter过滤式,Embedded镶嵌式
Filter过滤式: 方差选择法:低方差特征过滤; 相关系数法:特征之间的相关程度; Embedded镶嵌式: 决策树:信息熵,信息增益; 正则化:L1,L2; 深度学习: 卷积学习等;
Filter过滤式:
1.低方差特征过滤
低偏差,低方差。表现出来就是,预测结果准确率很高,并且模型比较健壮(稳定),预测结果高度集中。
低偏差,高方差。表现出来就是,预测结果准确率较高,并且模型不稳定,预测结果比较发散。
高偏差,低方差。表现出来就是,预测结果准确率较低,但是模型稳定,预测结果比较集中。
高偏差,高方差。表现出来就是,预测结果准确率较低,模型也不稳定,预测结果比较发散。
低方差特征过滤API使用:

2.相关系数
-
反应变量相关关系密切程度的统计指标
-
如下图结果为0.99,说明广告投入费用和月平均销售额度之间有高度的正相关关系
-
取值范围-1 – 1,大于0正相关,小于0负相关
-
当2个特征相关性比较高时,可以选取其中一个,或加权求和,主成分分析

API使用:from scipy.stats import pearsonr r = pearsonr(data["x"],data["y"] r 为相关系数,X,Y,分布为数据data的2个特征
2>主成分分析():
- 将 n维特征映射到 k 维上(k<n) ,这 k 维是全新的正交特征。这 k 维特征称为主元,是重新构造出来的 k 维特征,而不是简单地从 n 维特征中去除其余 n‐k 维特征。
- 算法思想:最大方差理论、最小平方误差理论、坐标轴相关度理论
- 将一个二维转换成一维,并且缺失少量的信息–找到一个合适的直线,通过矩阵运算得出主成分分析的结果;
- PCA是一种非常有用的统计技术,它已经应用于人脸识别和图像压缩领域中,并且是高维数据计算模型的常用技术。简单说是把高维数据将成低维数据,比如100000x100000的矩阵降成100000x100的。
PCA-API使用:

PCA计算过程:五步 转自:https://www.cnblogs.com/sweetyu/p/5085798.html
假设我们得到的 2 维数据如下: 行代表样例,列代表特征,这里有 10 个样例,每个样例两个特征。
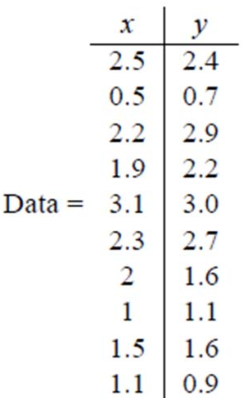
第一步,分别求 x 和 y 的平均值,然后对于所有的样例,都减去对应的均值。

第二步,求特征协方差矩阵。

















 4507
4507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









