









作者:幻好
来源:恒生LIGHT云社区
基本概念
HDFS (Hadoop Distributed File System) 是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。
首先,通过名字就能很清楚的明白 HDFS 在 Hadoop 中是应该文件存储的组件。
HDFS 的设计之初,主要是考虑到在数据量的不断增长的环境下,由于受制单机资源有限,为了保证系统能够提供高可用、高可靠性以及高扩展等要求,于是通过分布式架构,以达到响应的需求。
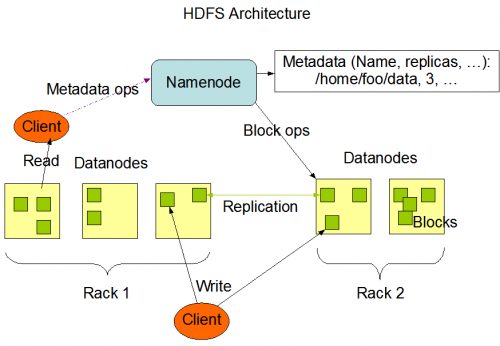
核心架构
HDFS 的主要架构分为三个部分:NameNode(nn)、DataNode(dn) 、Secondary NameNode(2nn)。
NameNode(nn)
- 存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的
DataNode等。
可以理解系统的文件资源管理器,方便我们查询文件存储位置以及相关属性信息。
DataNode(dn)
- 负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作。
可以理解为通过NameNode是存储一些文件基本属性信息方便我们查询,而DataNode则是存储文件数据的。
Secondary NameNode(2nn)
- 用来监控
HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照
Secondary NameNode可以理解为NameNode的备份,如果NameNode都挂了,Secondary NameNode的备份还能继续提供服务
一个 HDFS 集群由一个 NameNode 和一些 DataNode 组成, NameNode 相当于控制中心,负责管理文件系统的名字空间、数据块与数据节点的映射以及数据节点的调度。 DataNode 则负责处理实际的客户端读写的请求,存储数据。
运行原理
写数据
- 首先客户端向
NameNode发起RPC请求创建文件; NameNode会校验用户权限并查询文件是否存在,最终创建一条元数据信息并返回存储的DataNode信息给客户端;- 客户端开始向
DataNode上传数据,DataNode会对数据进行切分并完成副本的创建; - 然后
DataNode会将数据复制到其他的节点上; - 直到所有的节点完成后,返回上传成功,关闭连接。
读数据
- 首先客户端通过
RPC调用NameNode的查询方法; NameNode会校验用户权限并查询文件是否存在,并将文件保存在DataNode的节点返回;- 客户端向返回的
DataNode发起读取的请求,获取数据; - 当所有的数据读取完成后,资源关闭。
优缺点
优点:
- 能够处理较大文件,如MB到TB。
- 能够部署在廉价服务器上,对性能要求不高,具有较高容错性。
- 能够对已存储内容进行追加存储内容
缺点:
- 访问延迟较高,不适合应用在低延迟场景
- 不适合大量较小文件存储,会耗费较多资源。
总结
HDFS 的设计保证了系统的高可用、高扩展等要求,虽然也有弊端,但是我们应该根据切实的业务需求,选择最合适的技术方案。
HDFS 通过其良好的跨平台移植性,使得其他大数据计算框架都将其作为数据持久化存储的首选方案。
















 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









