






作者:幻好
来源:恒生LIGHT云社区
概述
本文将通过虚拟机搭建单机伪集群的Hadoop服务,帮助更好的学习和理解Hadoop大数据平台的运行原理。具体到每个细节,方便新手学习和理解。

环境准备
- Linux centos 7(虚拟机)
- JDK1.8
- Hadoop 2.5+
JDK系统环境配置
首先检查系统是否安装JDK,如果安装,确保系统安装JDK版本在1.8+且不是OpenJDK,否则后续安装Hadoop可能会报错。
通过以下命令查看JDK版本:java -version
如果安装版本较低或者已经安装了OpenJDK,可以通过命令进行卸载重装:
查看系统安装的JDK包:rpm -qa|grep java
然后将查出的包进行逐个删除:rpm -e --nodeps [包名]
安装JDK时,首先创建一个文件夹用来存放JDK安装包,如下命令:
mkdir -p /opt/local/java/jdk
进入以上创建目录后,使用以下命令下载JDK包:
weget [https://repo.huaweicloud.com/java/jdk/8u192-b12/jdk-8u192-linux-x64.tar.gz](https://repo.huaweicloud.com/java/jdk/8u192-b12/jdk-8u192-linux-x64.tar.gz)
下载完成后,对压缩包进行解压:
tar -zxvf jdk-8u192-linux-x64.tar.gz
解压完成后,配置系统环境变量:
vi /etc/profile
向文件末尾添加以下配置参数:
# jdk1.8
export JAVA_HOME=/opt/local/java/jdk/jdk1.8.0_192
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
配置完成后保存,刷新系统配置:
source /etc/profile
最后检验JDK是否生效:
java -version
打印以下日志信息即可。

系统配置
- 主机名配置
由于使用虚拟机搭建,ip可能并不是固定的,为了更好的访问和识别主机,我们需要先修改主机名配置,后面直接使用主机名访问服务。
查看主机目前的hostname:hostname
如果需要修改后的hostname能一直生效,则修改/etc/sysconfig/network文件,向文件新增以下参数:
NETWORKING=yes
HOSTNAME=centos001.com
修改后,需要重启主机生效。
如果需要立即生效,可以直接使用命令:
hostname centos001.com
- 防火墙配置
为了方便学习,先将防火墙关闭禁用,方便其他主机进行访问。(当然也可以配置开放的端口)
- 使用命令查看防火墙运行状态:
systemctl status firewalld - 停止运行防火墙:
service firewalld stop - 永远停用防火墙:
systemctl disable firewalld
Hadoop部署安装
- Hadoop安装包准备
- 首先创建存放Hadoop安装包存放的目录:
mkdir -p /home/local/hadoop
- 然后进入创建目录,下载Hadoop安装包:
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
- 解压安装包:
tar -zxvf hadoop-2.10.1.tar.gz
- 配置Hadoop环境变量
- 为了方便后续直接使用命令行启动 Hadoop 相关服务,可以配置相关环境变量
- 进入配置文件 /etc/profile,向末尾追加以下配置
export HADOOP_HOME=/home/local/hadoop/hadoop-2.10.1/
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- core-site.xml配置
- 向
configuration中添加以下配置参数:
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos001.com:8091</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/local/hadoop/hadoop-2.10.1/data/tmp</value>
</property>
- 上述不使用ip访问而改用主机名访问,这里配置HDFS的节点访问。
hadoop.tmp.dir是 Hadoop 文件系统依赖的基础配置,很多路径都依赖它。(如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中)。- 需要提前存储目录创建好:
mkdir -p /home/local/hadoop/hadoop-2.10.1/data/tmp - hdfs-site.xml配置
- 配置 HDFS 的 DataNode 的备份数量(默认数量为3),只单机模拟运行,配置1
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
- mapred-site.xml配置
- 这里配置Mapreduce的运行模式,常用的就是生产:
yarn,测试:local两种模式。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- yarn-site.xml配置
- 配置资源服务的相关运行参数
<property>
<name>yarn.resourcemanager.hostname</name>
<value>centos001.com</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- slaves配置
- 由于只演示单机模式,slaves文件无需配置
- 脚本参数配置
- hadoop-env.sh中需要配置JDK觉得路径:
JAVA_HOME,Hadoop配置路径:HADOOP_CONF_DIR - yarn-env.sh中需要配置JDK觉得路径:
JAVA_HOME - mepre-env.sh中需要配置JDK觉得路径:
JAVA_HOME
测试启动
首次启动格式化
如果第一次启动,需要先格式化 namenode
- 通过命令:
hdfs namenode -format - 如果看到打印以下日志,则表示格式化成功

启动Hadoop
通过以下命令启动Hadoop相关服务节点:
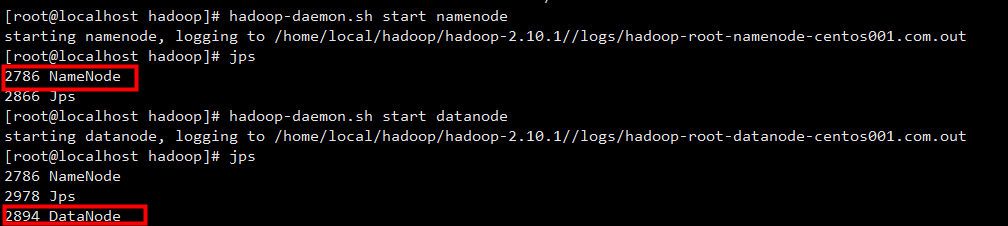
hadoop-daemon.sh start namenodehadoop-daemon.sh start datanode
启动后,可以通过命令:jps 查看服务是否成功启动:
启动YARN
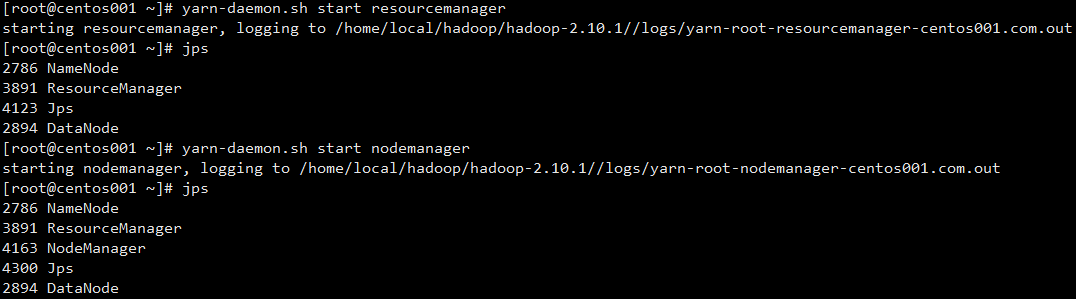
启动 Hadoop 相关服务节点后,在启动 Yarn 相关资源管理服务:
yarn-daemon.sh start resourcemanageryarn-daemon.sh start nodemanager
启动后,可以通过命令:jps 查看服务是否成功启动:
验证页面
服务启动成功后,在我们的PC(windows)上,配置域名映射。打开主机的hosts文件,配置以下参数:
192.168.201.129 centos001.com
配置保存后,可以直接通过上述配置域名进行访问Hadoop后台监控页面:http://centos001.com:50070
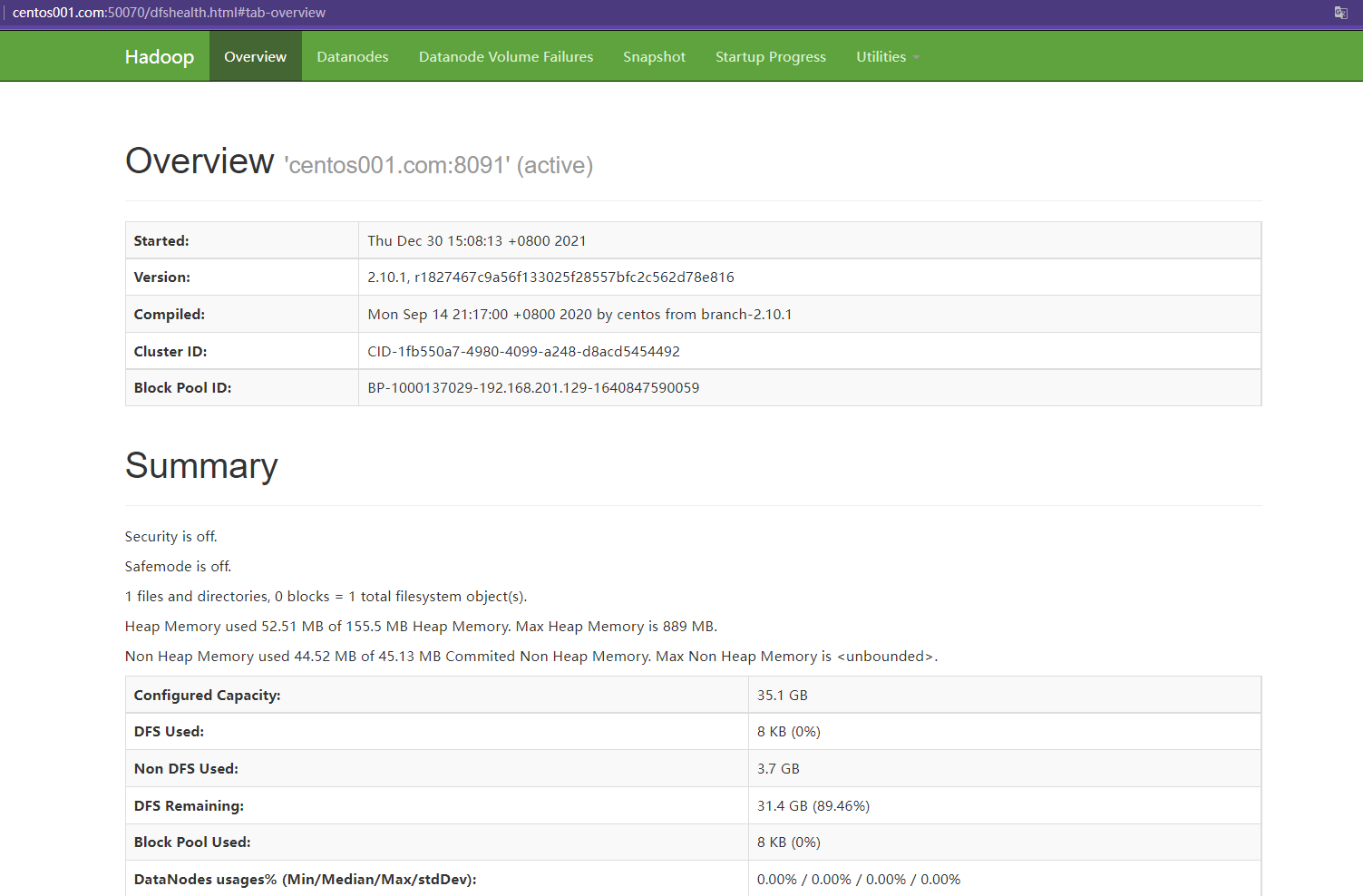
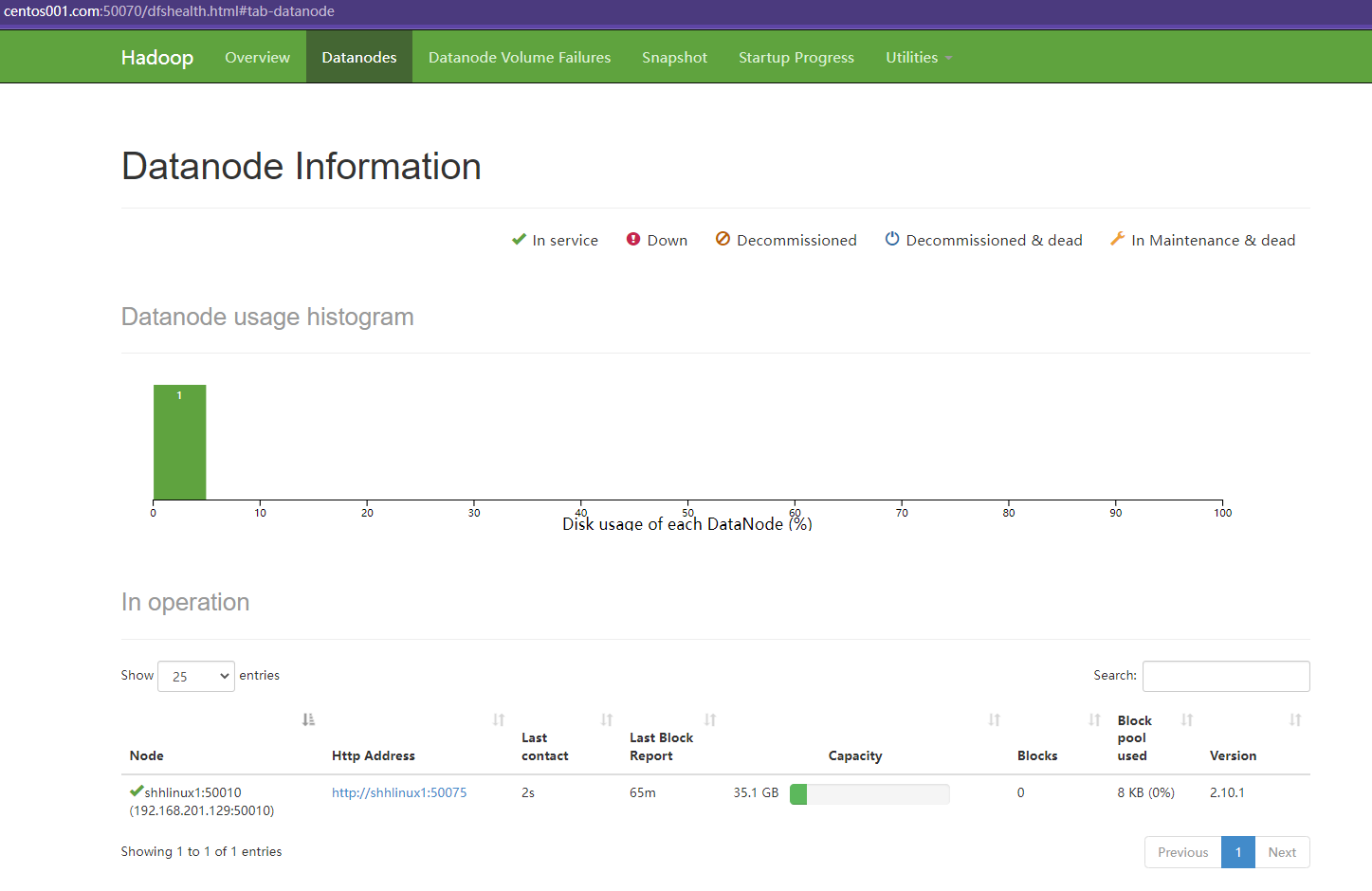
总结
以上为单机伪集群的Hadoop搭建实践过程,为了帮助新手更好的理解和学习 Hadoop ,实践才能出真知。
有任何问题,欢迎一起讨论交流。
想向技术大佬们多多取经?开发中遇到的问题何处探讨?如何获取金融科技海量资源?
恒生LIGHT云社区,由恒生电子搭建的金融科技专业社区平台,分享实用技术干货、资源数据、金融科技行业趋势,拥抱所有金融开发者。
















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









