







 Apache Phoenix是一个构建在HBase之上的SQL层,提供JDBC接口以简化HBase的数据操作。它支持创建、删除表,插入、更新和查询数据,以及创建各种类型的索引,包括全局索引、本地索引、覆盖索引和函数索引。Phoenix通过将SQL查询转换为HBase扫描来提高查询性能,并提供了多种特性,如统计收集、表抽样、事务支持和时间序列优化。此外,Phoenix支持通过视图映射HBase表,并可以通过JDBC进行连接和操作。
Apache Phoenix是一个构建在HBase之上的SQL层,提供JDBC接口以简化HBase的数据操作。它支持创建、删除表,插入、更新和查询数据,以及创建各种类型的索引,包括全局索引、本地索引、覆盖索引和函数索引。Phoenix通过将SQL查询转换为HBase扫描来提高查询性能,并提供了多种特性,如统计收集、表抽样、事务支持和时间序列优化。此外,Phoenix支持通过视图映射HBase表,并可以通过JDBC进行连接和操作。
Apache Phoenix 5.1.0

1. 官网介绍
- 官网 : http://phoenix.apache.org/
- Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC APIs而不是HBase客户端APIs
来创建表,插入数据和对HBase数据进行查询。Phoenix完全使用Java编写,作为HBase内嵌的
JDBC驱动。Phoenix查询引擎会将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准
的JDBC结果集。 - Apache Phoenix是使用Apache HBase作为后备存储的开源,大规模并行,关系数据库引擎,支持OLTP for Hadoop 。Phoenix提供了一个JDBC驱动程序,该驱动程序隐藏了noSQL存储的复杂
性,使用户可以创建,删除和更改SQL表,视图,索引和序列。批量插入和删除行;并通过SQL查
询数据。Phoenix将查询和其他语句编译到本机的noSQL存储区API中,而不是使用MapReduce来
在noSQL存储区之上构建低延迟应用程序。
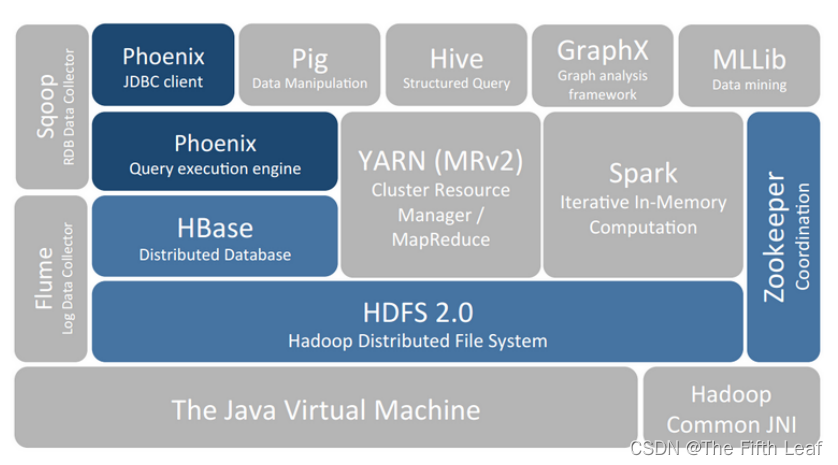
2. 软件功能
- 表抽样。通过实现一个过滤器来支持 TABLESAMPLE 子句,该过滤器使用由统计信息收集建立的路标仅返回一定百分比的行。4.12版本中可用
- 减少磁盘存储。通过以下方式减少磁盘存储,以提高性能:①将所有值打包到每个列族的单个单元中;②提供列名和列限定符之间的间接寻址。4.10版本中可用
- 原子更新。现在可以在UPSERT VALUES语句中进行原子更新,以支持计数器和其他用例。4.9版本中可用
- 默认声明。现在,在定义列时,可以为初始值提供DEFAULT声明。4.9版本中可用
- 命名空间映射。将Phoenix模式映射到HBase命名空间,以改善不同模式之间的隔离。4.8版本中可用
- Hive整合。使Hive与Phoenix一起使用,以支持将大型表连接到其他大型表。4.8版本中可用
- 本地索引的改进。重新设计了本地索引实现,以确保表和索引数据的共置,并使用受支持的HBaseAPI以获得更好的可维护性。4.8版本中可用
- DISTINCT查询优化。在主键的前导部分上将查找逻辑推入服务器,以进行SELECT DISTINCT和COUNT DISTINCT查询,从而带来显着更好的性能。4.8版本中可用
- 交易支持。通过与Tephra集成来支持交易。4.7版本中可用
- 时间序列优化。为更详细地解释优化对时间序列数据的查询这里。4.6版本中可用
- 异步索引填充。允许使用map reduce作业异步创建索引。4.5版本中可用
- 用户定义的功能。允许用户创建自己的自定义或特定于域的用户定义功能并将其部署到群集。4.4版本中可用
- 功能指标。允许将索引定义为表达式,而不仅仅是列名,并在查询包含该表达式时使用索引。4.3版本中可用
- 映射减少集成。通过实现自定义输入和输出格式,支持与Phoenix的常规map-reduce集成。3.3 /4.3版本中可用
- 统计收集。收集表的统计信息以改善查询并行化。3.2 / 4.2版本中可用
- 加入改进
- 改进现有的哈希联接实现。
- 子查询支持WHERE子句中的独立子查询和相关子查询以及FROM子句中的子查询。3.2 / 4.2版本中
可用 - 追踪。允许查看 UPSERT 或 SELECT 语句的各个步骤,以及每个步骤在集群中所有计算机上花费的时间。4.1版本中可用
- 本地索引。一个新的,互补分stragegry写沉重,空间受限的使用情况。使用本地索引,索引和表数据共存于同一服务器上,因此在写入过程中不会发生网络开销。即使查询未完全覆盖,也可以使用局部索引(即Phoenix通过针对数据表的指向获取自动检索不在索引中的列)。4.1版本中可用
- 派生表。允许在FROM子句中使用 SELECT 子句来定义派生表(包括联接查询)。3.1 / 4.1版本中可用
- Apache Pig加载程序。支持Pig加载器在通过Pig处理数据时利用Phoenix的性能。3.1 / 4.1版本中可用
- 概观。允许使用同一物理HBase表创建多个表。3.0 / 4.0版本中可用
- 多租户。允许不同租户在每个连接的基础上创建独立视图,这些视图均共享相同的物理HBase表。3.0 / 4.0版本中可用
- 序列。已实现对CREATE / DROP SEQUENCE,NEXT VALUE FOR和CURRENT VALUE FOR的支持。3.0 / 4.0版本中可用
- 数组类型。支持标准JDBC ARRAY类型。3.0 / 4.0版本中可用
- 二级索引。允许用户在可变或不可变数据上创建索引。
- 分页查询。通过行值构造函数进行分页查询,这是一种标准SQL构造,可以有效地将行定位在组合键值处或之后。启用更多查询功能,可以有效地逐步浏览数据并优化复合键值的IN列表以获取积分。
- CSV批量加载程序。通过map-reduce或客户端脚本将CSV文件批量加载到HBase中。
- 聚合增强。现在支持
COUNT DISTINCT,PERCENTILE和STDDEV。 - 类型添加。该
FLOAT,DOUBLE,TINYINT和SMALLINT现在支持。 - IN / OR / Like优化。当使用前导行键列的查询中出现IN(或等效的OR)和LIKE时,请将其编译为跳过扫描过滤器,以更有效地检索查询结果。
- 支持主键列的ASC / DESC声明。允许将主键列声明为升序(默认)或降序,以使行键顺序可以匹配所需的排序顺序(从而防止进行额外的排序)。
- 盐化行键。为了防止写入时出现热点,可以通过在行密钥中插入前导字节来“加盐”,这是整个行密钥的N个存储桶上的mod模。当行键是单调递增的值(通常是表示当前时间的时间戳)时,这可确保写入的均匀分布。
- TopN查询。当与TopN结合使用时,通过对ORDER BY的支持,支持返回前N行的查询。
- 动态列。对于某些用例,很难预先对模式进行建模。您可能有一些只想在查询时指定的列。在HBase中这是可能的,因为每一行(和列族)都包含一个带有可在运行时指定的键的值的映射。因此,我们希望支持这一点。
- Apache Bigtop包含。有关更多信息,请参见BIGTOP-993。
3. 下载安装
下载地址:http://phoenix.apache.org/download.html
镜像下载地址:https://mirrors.bfsu.edu.cn/apache/phoenix/phoenix-5.1.0/phoenixhbase-2.2-5.1.0-bin.tar.gz
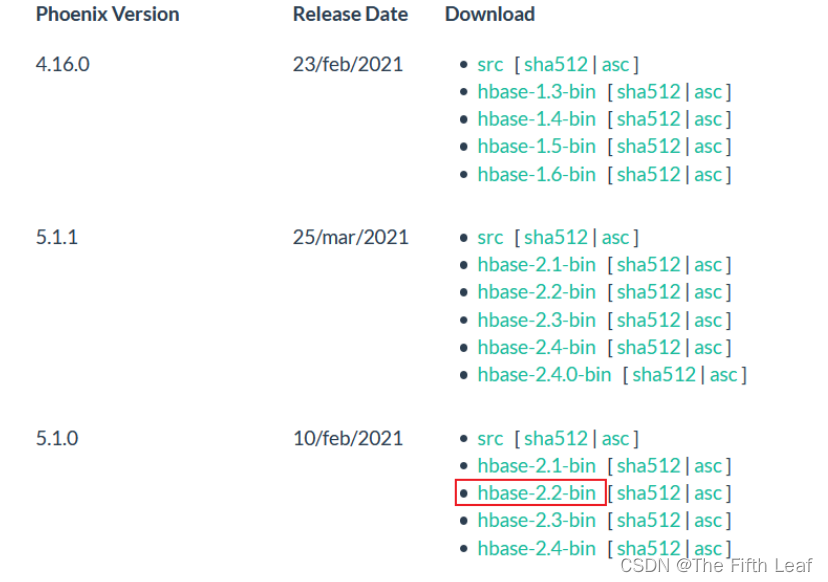
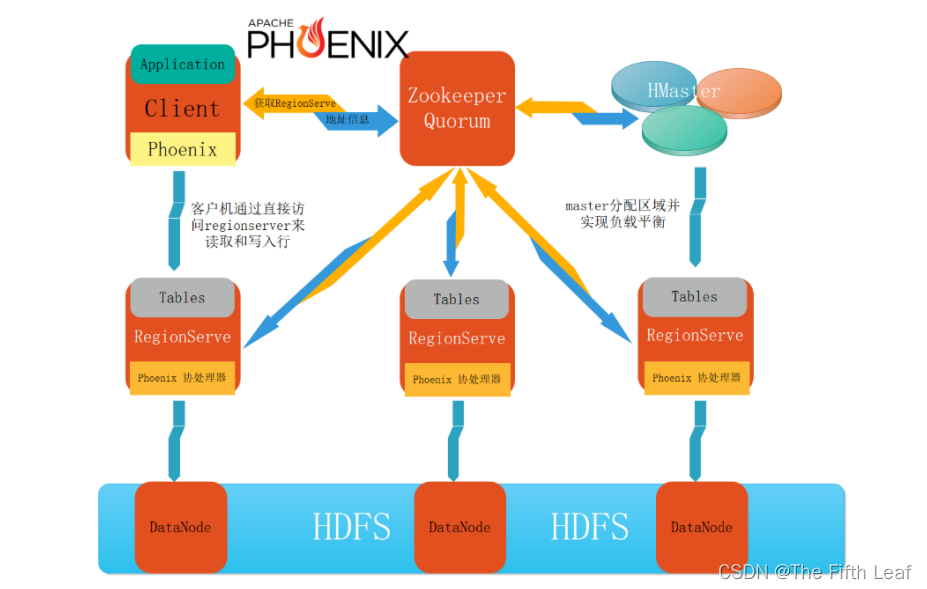
4. Phoenix安装
Phoenix是以JDBC驱动方式嵌入到HBase中的,在部署时只有一个包,直接放HBase的lib目录,逻辑构架如下:
| 节点\功能 | HMaster | HRegionServer | Zookeeper | Phoenix |
|---|---|---|---|---|
| node01 | * | * | * | * |
| node02 | * | * | * | * |
| node03 | * | * | * |
- 上传解压拷贝改名
[root@node01 ~]# tar -zxvf apache-phoenix-5.1.0-HBase-2.0-bin.tar.gz
[root@node01 ~]# mv phoenix-hbase-2.2-5.1.0-bin phoenix-5.1.0
[root@node01 ~]# mv phoenix-5.1.0 /opt/bdp/
[root@node01 ~]# cd /opt/bdp/phoenix-5.1.0/
- 客户端和HBase同时更新配置文件
[root@node01 ~]# vim /opt/bdp/phoenix-5.1.0/bin/hbase-site.xml
<!-- 开启schema与namespace的对应 -->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
[root@node01 ~]# vim /opt/bdp/hbase-2.2.5/conf/hbase-site.xml
<!-- 二级索引 -->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<!-- 开启schema与namespace的对应 -->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
- 拷贝到其他节点
[root@node01 ~]# scp /opt/bdp/hbase-2.2.5/conf/hbase-site.xml root@node02:/opt/bdp/hbase-2.2.5/conf/
[root@node01 ~]# scp /opt/bdp/hbase-2.2.5/conf/hbase-site.xml root@node03:/opt/bdp/hbase-2.2.5/conf/
- 拷贝jar包
[root@node01 phoenix-5.1.0]# cp phoenix-server-hbase-2.2-5.1.0.jar
/opt/bdp/hbase-2.2.5/lib/
[root@node01 phoenix-5.1.0]# scp phoenix-server-hbase-2.2-5.1.0.jar root@node02:/opt/bdp/hbase-2.2.5/lib/
[root@node01 phoenix-5.1.0]# scp phoenix-server-hbase-2.2-5.1.0.jar root@node03:/opt/bdp/hbase-2.2.5/lib/
- 配置环境变量
[root@node01 ~ ]# vim /etc/profile
export PHOENIX_HOME=/opt/phoenix-5.1.0
export PATH=$PHOENIX_HOME/bin:$PATH
[root@node01 ~ ]# source /etc/profile
- 启动HBase
【123】zkServer.sh start
【1】 start-all.sh
【1】 start-hbase.sh
- 启动Phoenix
【1】sqlline.py node01,node02,node03:2181
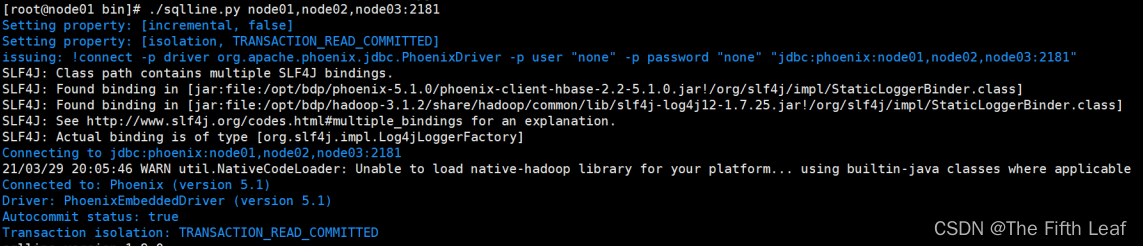
首次启动会在hbase中自动生成6张表,在phoenix中也可以看到
SYSTEM.CATALOG
SYSTEM.FUNCTION
SYSTEM.LOG
SYSTEM.MUTEX
SYSTEM.SEQUENCE
SYSTEM.STATS

5. Phoenix系统架构
5.1. 重客户端架构
从其架构来看,Phoenix结构上划分为客户端和服务端两部分:
- 客户端包括应用程序开发,将SQL进行解析优化生成QueryPlan,进而转化为HBase Scans,调用HBase API下发查询计算请求,并接收返回结果;
- 服务端主要是利用HBase的协处理器(Phoenix-core包里面包含hbase-client,以及hbase-server包),处理二级索引、聚合及JOIN计算等。
这种架构我们称之为重客户端架构,也是目前Phoenix使用最广泛的方式,但是这种方式存在一些使用
上的缺陷:
- 应用程序与Phoenix core绑定使用,需要引入Phoenix内核依赖,目前一个单独Phoenix重客户端
集成包已达120多M; - 运维不便,Phoenix仍在不断优化和发展,一旦Phoenix版本更新,那么应用程序也需要对应升级
版本并重新发布; - 仅支持Java API,其他语言开发者不能使用Phoenix。
5.2. 轻客户端架构
轻客户端架构将Phoenix分为三部分:
- 瘦客户端是用户最小依赖的JDBC驱动程序,与Phoenix依赖进行解耦,支持Java、Python、Go等多种语言客户端;
- QueryServer是一个单独部署的HTTP服务,接收轻客户端的RPC请求,并将SQL转发给PhoenixCore进行解析优化执行;
- Phoenix Server与重客户端架构相同。
QueryServer基于Calcite的Avatica组件实现,内部嵌入了独立的Jetty HttpServer,支持Protobuf和JSON两种RPC传输协议,其中Protobuf是默认协议,提供比JSON更高效的通信方式。
由于QueryServer是无状态的,可以部署在HBase集群的每台RegionServer上,通过HTTP负载均衡器将多个客户端的请求分发在多个QueryServer上。
6. Phoenix数据模型
Phoenix在数据模型上是将HBase非关系型形式转换成关系型数据模型 ,如下图所示
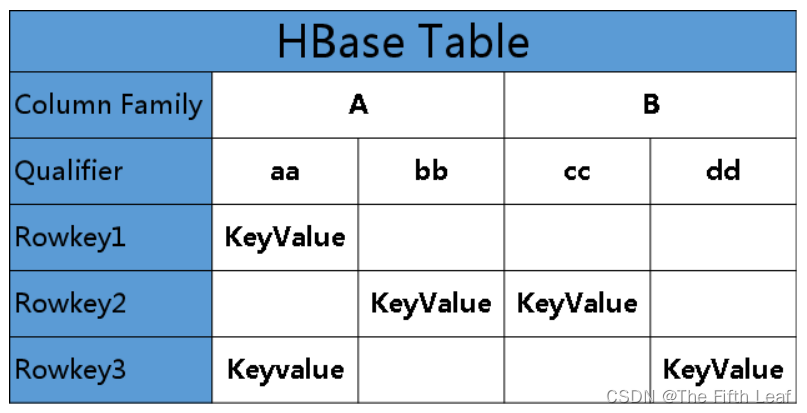
对于Phoenix来说,HBase的rowkey会被转换成primary key,column family如果不指定则为0否则字段名会带上,qualifier转换成表的字段名,如下是创建一个Phoenix表的例子,以创建表 test 为例,主键为 id即为HBase的rowkey, column family为 i , qualifier为name和age。
create table t_user ("id" varchar(20) primary key,"i"."name" varchar(20)
,"i"."age" varchar(20));
Phoenix还支持组合primary key,即由多个字段联合组成主键,对于组合主键来说,在HBase底层会把主键的多个字段组合成rowkey显示,其它字段为HBase的qualifier显示。如上面test表,假设id和name为主键,创建表语句又变成:
create table test ("id" varchar(20), "name" varchar(20) ,"i"."age"
varchar(20),constraint pk PRIMARY KEY("id","name"));
这样,假设插入一条数据:如下所示
upsert into t_user values ('1','zhangsanfeng','23');
在HBase中,rowkey即为 “1a” , i:age 为 23。这里,可能大家对双引号有点疑问,对于Phoenix来说,加了引号的话,不管是表还是字段名,会变成大小写敏感,不加的话,会统一转换成大写字母。
7. phoenix常用命令
目前Phoenix已经支持关系型数据库的大部分语法,如下图所示:

具体语法用法可参考Phoenix官网,写得比较详细。
7.1. 查看所有表
!tables
7.2. 创建schema
create schema school;
7.3. 创建表
建完表后hbase中也会自动创建对应的表
#创建完的表名和字段名都会自动转成大写,如需小写,需在建表时给表名和字段名前后加双引号。如下:
create table school.teacher(
tno INTEGER NOT NULL PRIMARY KEY,
tname VARCHAR,
age INTEGER
);
7.4. 插入/更新数据
upsert into school.teacher (tno,tname,age) values(1,'zhangsan',23);
upsert into school.teacher (tno,tname,age) values(2,'lisi',35);
upsert into school.teacher (tno,tname,age) values(3,'tianqi',66);
7.5. 查询插入的数据
select * from school.teacher;
7.6. 删除数据
delete from school.teacher where id =1;
7.7. 删除表
drop table school 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











