






前文
遇到很多问题是因为消费积压导致的数据延迟,数据对校时问题重重。那么今天就记录下解决这个问题。
问题定位
消费积压顾名思义,就是产生的数据堆积没有实时消费数据
可以使用kafka工具查看
也可以直接在kafka容器内服务器上直接执行命令查看
./kafka-consumer-groups.sh --bootstrap-server --describe localhost:9092 --group testgroup
和上面的kafka工具一样可以看到存在积压
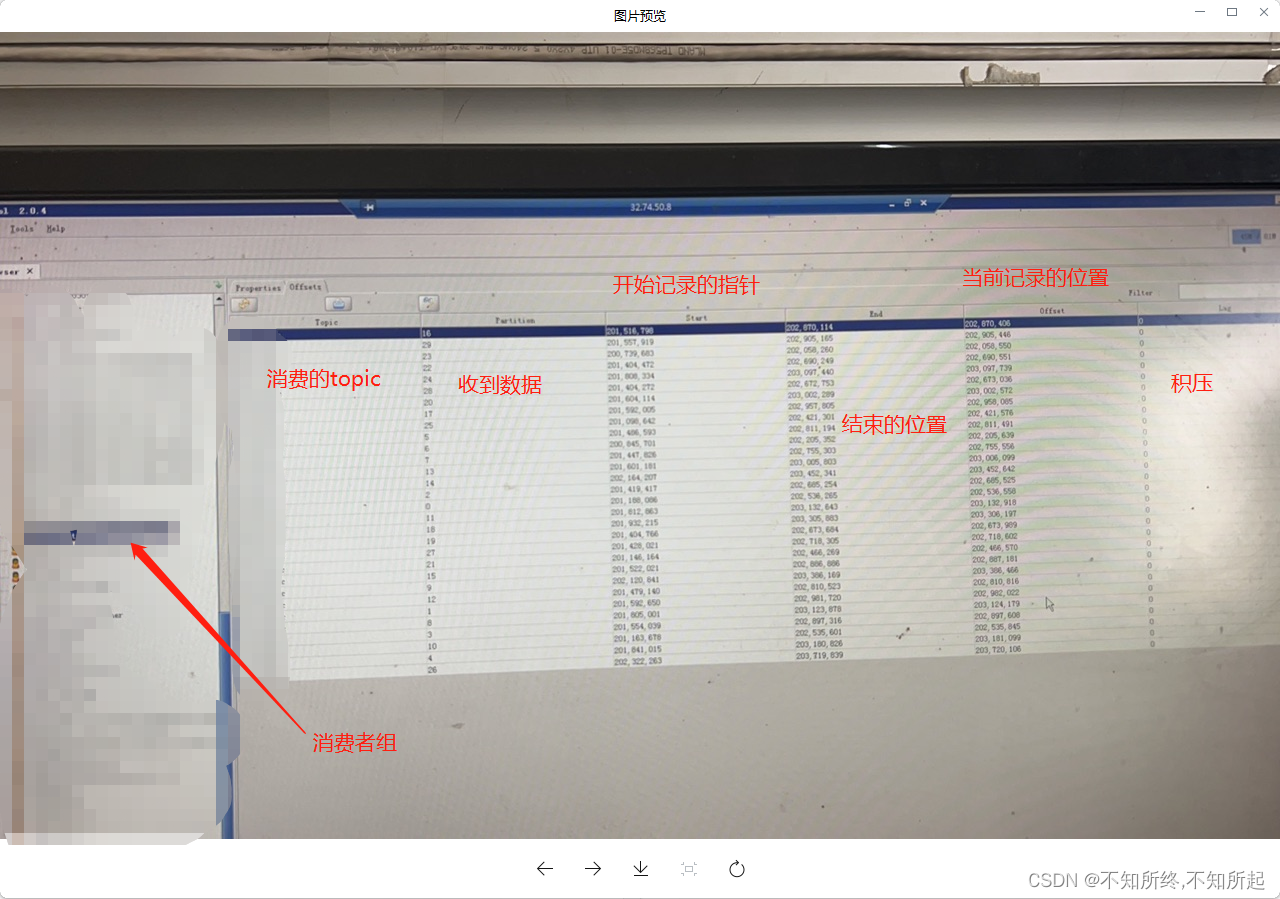
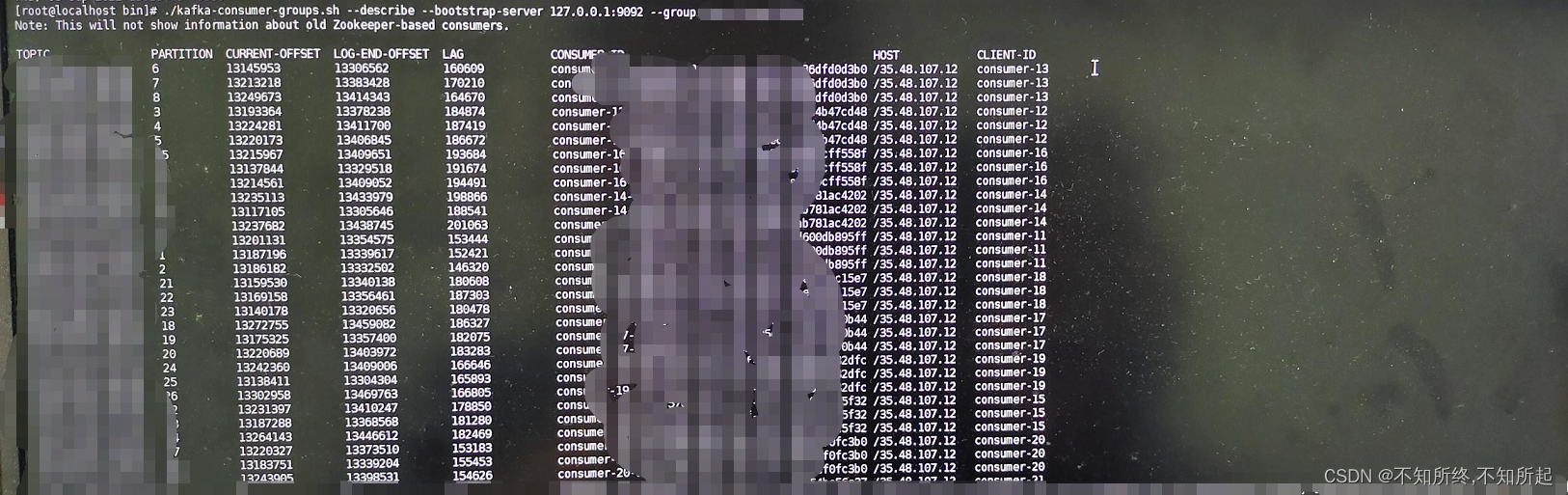
积压造成的原因
积压造成的原因,基本都可以定位为消费能力不足、消费端每次获取数据过少。这些都是在项目压测阶段可以展示出来的,但是对于会在某个阶段产生的峰值来说,并不能有效的解决,此问题还是要追加机器和启动多实例。
解决方法
比如一分钟消费1000条,但是每分钟会产生2000条消息,就会存在1000条的积压。!!!理想情况下
更改配置
这里给到的是测试在压测阶段解决方案
查看配置:
spring.kafka.consumer.max-poll-records
一次拉取数据的数量多少。这个要看从拉取到通过代码在到代码结束的平均耗时。如果消费端是直接塞入线程池,进行消费,这里要考虑,线程池的队列大小和拒绝策略等诸多问题。
由上述来考虑问题:比如一分钟消费1000条,但是每分钟会产生2000条消息,就会存在1000条的积压。
一次拉取500条数据消费,耗时30s,一分钟消费1000条。存在每分钟增加1000条积压情况。
一次拉取550条数据消费,耗时30s,一分钟消费1100条。存在每分钟增加900条积压情况。
—————————————————————————————————————————————————————————————
spring.kafka.properties.max.poll.interval.ms
每次拉取数据的时间间隔,kafka在拉取消息时会记录当前消费者的心跳,心跳消失,当前消费者会被剔除。
如果当前值太小,一次拉取的数据过多,在时间内并未处理完成,会导致kafka的consumer挂掉从而让分区重新选举,选举中不会消费数据,之前该consumer拥有的分区和offset信息也会失效。
spring.kafka.haiyan.consumer.enable-auto-commit 是否自动提交,一般设置为true
—————————————————————————————————————————————————————————————
spring.kafka.consumer.concurrency
配置为1的时候等于1个消费者消费指定的kafka(单线程),配置为多个时候,是根据消费指定的topic的分区来分配的,比如配置了三个消费线程,一个topic三个分区,就是一个线程去消费一个分区,如果当前topic只有两个分区呢?会存在一个线程是闲置状态。两个线程分别消费两个分区。可设置数据为分区数>=concurrency
由上述来解决:比如一分钟消费1000条,但是每分钟会产生2000条消息,就会存在1000条的积压。
topic有两个分区,开启两个线程就是,每个线程一次拉取500条数据消费,耗时30s,一个线程一分钟消费1000条,两个线程就是一分钟消费2000条,每分钟不存在积压
优化消费端
@KafkaListener(containerFactory = "batchFactory", topics = {"#{'${spring.kafka.consumer.topic}'}"})
public void listener(List<ConsumerRecord<String, String>> records) {
for (ConsumerRecord<String, String> record : records) {
/*
* 各种操作
* */
}
}
消费端开启线程池对数据消费
private ExecutorService pool = newFixedThreadPool(20);
@KafkaListener(containerFactory = "batchFactory", topics = {"#{'${spring.kafka.consumer.topic}'.split(',')}"})
public void listener(List<ConsumerRecord<String, String>> records) {
//放入线程池执行
pool.execute(new ConsumerThread(records));
}
消费端开启线程池对数据消费
//创建线程池
private ExecutorService pool = newFixedThreadPool(20);
@KafkaListener(containerFactory = "batchFactory", topics = {"#{'${spring.kafka.consumer.topic}'.split(',')}"})
public void listener(List<ConsumerRecord<String, String>> records) {
//放入线程池执行
pool.execute(new ConsumerThread(records));
}
//创建线程池
private ExecutorService pool = newFixedThreadPool(20);
@KafkaListener(containerFactory = "batchFactory", topics = {"#{'${spring.kafka.consumer.topic}'}"},topicPartitions = @TopicPartition(topic = "#{'${spring.kafka.consumer.topic}'}", partitions = {"1", "3"}))
public void listener(List<ConsumerRecord<String, String>> records) {
//消费1、3放入线程池执行
pool.execute(new ConsumerThread(records));
}
@KafkaListener(containerFactory = "batchFactory", topics = {"#{'${spring.kafka.consumer.topic}'}"},topicPartitions = @TopicPartition(topic = "#{'${spring.kafka.consumer.topic}'}", partitions = {"2", "4"}))
public void listener(List<ConsumerRecord<String, String>> records) {
//消费2、4放入线程池执行
pool.execute(new ConsumerThread(records));
}
!!!kafka的key使用不恰当导致=某个分区中数据过多,推送数据时候做好规则。
kafkaTemplate.send(topic key, json);















 55
55











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









