







这一题的标准解法是用快慢指针,没错,就是快慢指针。在这里记录一下我的解题历程。
一开始我和评论区的快指针比慢指针只多走一圈的想法一致,但是没有证明,所以我打算先以这个命题为基础,看看题目能不能解出来。
根据题目条件,可以归为链表问题,即数组中的每一个数存储的都是下一个数的索引,由于有重复元素,加上题目所给的数组中元素的取值,所以构成的链表最终一定会在某处结成一个环,这就导致快指针一定是可以追到慢指针的。然而难点在于如何找到环的入口位置,也即重复元素。这个问题可以用画图来解释:

所以,当快指针追上慢指针时,要将快指针清零,然后快慢指针相等时,即它们同时到达了入口,取出该值即重复数。
代码如下:
public int findDuplicate(int[] nums) {
int slow = 0;
for (int fast = 0; slow != fast || fast == 0; ) {
slow = nums[slow];
fast = nums[nums[fast]];
// System.out.println("slow: " + slow + " fast: " + fast);
}
// System.out.println(slow);
// System.out.println("----------");
for (int i = 0; slow != i; i = nums[i]) {
// System.out.println("slow: " + slow + " fast: " + i);
slow = nums[slow];
}
// System.out.println("slow: " + slow + " fast: " + slow);
return slow;
}
然而,上面的结论是基于快指针只比慢指针多走一圈得出的,其实,快指针是可能比慢指针多走不止一圈的。比如,这个用例:[1, 2, 3, 4, 5, 6, 7, 10, 9, 10, 8],这个用例是快指针比慢指针多逗乐两圈,同样地,我们可以模仿上面列出式子:
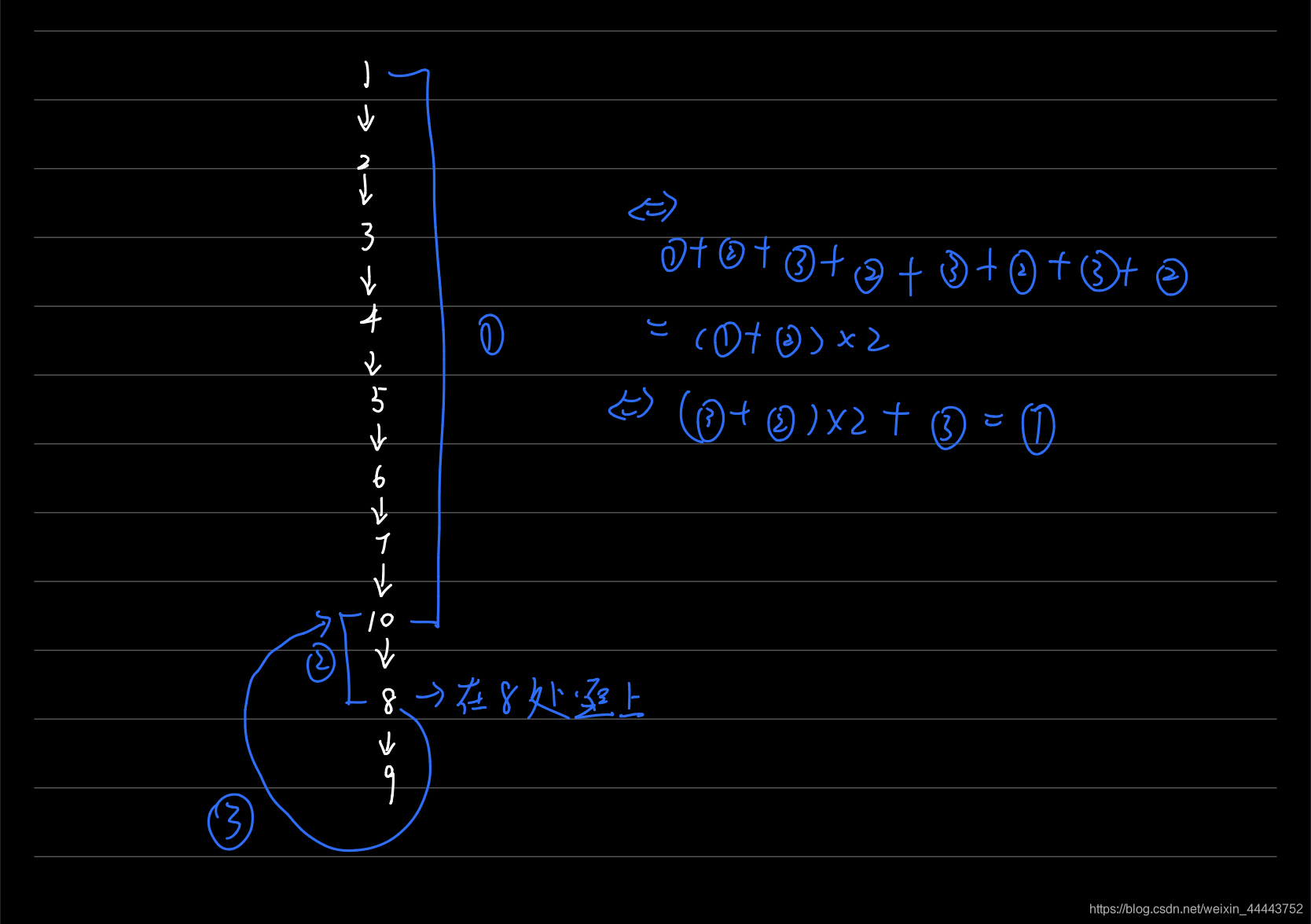
其实,最后找入口的时候,相当于快指针多饶了两圈,最后结果并没有改变。
优化后的代码,如下:
public int findDuplicatePro(int[] nums) {
int slow = 0;
int fast = 0;
while (true) {
slow = nums[slow];
fast = nums[nums[fast]];
if (slow == fast) {
fast = 0;
while (slow != fast) {
slow = nums[slow];
fast = nums[fast];
}
return slow;
}
}
}














 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









