









尚硅谷-MySql-高级思维导图:思维导图(mmap+HTML格式)
1. 前言
在实际的应用中、面对实际的项目系统时,不需要对所有的 SQL 都建立索引,费时费力。
只需要统计出系统中,使用频率最高的 、查询时间最慢的 一些 SQL 语句即可,也就是“八二原则”,处理 20% 的 SQL,达到 80% 的优化。
统计出 这些 SQL 语句,用到的方法大致为 : 1. 慢查询日志;2. show processlist
一般这项工作由运维人员进行,这里至少大致了解。
2. 查询优化
2.1. 永远小表驱动大表
-
小表驱动大表,小数据集驱动大数据集
-
IN 与 Exists 示例
select …… from A where id in (select id from B)可以用以下替换
select …… from A where id exists (select 1 from B where A.id = B.id)该语法可以理解为:将主查询的数据,放到子查询中做条件验证,根据验证结果(true/false)来决定主查询的数据结果是否得以保留
2.2. Order By 优化
-
Order by 子句尽量使用 Index 方式排序,避免使用 FileSort 方式排序
- index:指的是扫描索引本身进行排序,效率高
- filesort:文件排序,效率较低
- Order by 满足两种情况,会使用 index 排序:
- Order by 语句使用索引最左前缀
- 使用 where 子句与 order by 子句条件列组合满足索引最左前缀
-
如果不在索引列上,filesort 有两种算法:双路排序 和 单路排序
-
双路排序
- Mysql 4.1 之前使用的是双路排序,字面意思指的是两次扫描磁盘,最终得到结果
- 从磁盘读取排序字段,在 buffer 缓冲区进行排序,再从磁盘读取其他内容,此为两次IO
-
单路排序
- 从磁盘读取查询所需要的列,按照 Order by 列在 buffer 对他们进行排序,然后扫描排序后的列表进行输出
- 它的效率会高一点,避免了第二次读取数据,并把随机IO变为顺序IO
- 但它使用的空间更多了,因为它会把每一行都保存在内存中
-
单路存在的问题
在 sort_buffer 中,方法 B 比方法 A 要占用更多空间,因为方法 B 是把所有字段都取出,所以有可能取出的数据的总大小超出了 sort_buffer 容量,导致每次只能读取 sort_buffer 容量大小的数据进行排序,排完之后再取出 sort_buffer 容量大小数据,在排序……,从而导致多次 IO
-
此时优化策略
- 少写 Select *
- 增大 sort_buffer_size 参数,增大缓冲区容量
- 增大 max_length_for_sort_data
-
2.3. Group By 优化
- 大致与 Order by 一致
- group by 实质是先排序在分组,按照索引建的最佳左前缀
- 无法使用索引列,增大 max_length_for_sort_data 参数 + 增大 sort_buffer_size 参数
- where 高于 having ,能写在 where 限定的条件,就不要写在 having 中
3. 慢查询日志
3.1. 定义
- MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。
- long_query_time的默认值为10,意思是运行10秒以上的语句。
- 结合之前explain进行全面分析。
3.2. 注意
- 慢查询日志不是一直都要开着,因为开启慢查询日志需要一直向日志中发送 IO 流,一直开着会让系统负担更大
- 而是在系统运行开始变慢之后,找到运维人员,开启日志
- 在运行一周之后,再结合 explain 进行,查看、优化
3.3. 使用
1. 查看与开启
-
默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的,
可以通过设置slow_query_log的值来开启# 查看日志是否开启、存放位置 SHOW VARIABLES LIKE '%slow_query_log%'; # 开启日志 SET GLOBAL slow_query_log=1;
# 查看运行时间的阈值(默认值 10秒) SHOW VARIABLES LIKE 'long_query_time%'; # 修改阈值 SET 【GLOBAL / SESSION】 long_query_time=0.1; -
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具
mysqldumpslow。
2.mysqldumpslow
s:是表示按照何种方式排序
c:访问次数
I:锁定时间
r:返回记录
t:查询时间
al:平均锁定时间
ar:平均返回记录数据
at:平均查询时间
t:返回前多少条数据
g:后搭配使用正则匹配模式

3.4. 补充
- 与慢查询日志类似的还有,全局查询日志
- 全局查询日志,记录所有的 SQL 语句
- 所以一般不开启,只有遇到诡异问题(如:实在在不知道错误在哪,才开启定位一下)
4.批量数据脚本
4.1. 建库、建表
-
新建库
create database bigData; use bigData; -
新建 Dept 表
CREATE TABLE dept( id INT UNSIGNED PRIMARY KEY AUTO INCREMENT, deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT O, dname VARCHAR(20)NOT NULL DEFAULT ““, Ioc VARCHAR(13) NOT NULL DEFAULT ““ )ENGINE=INNODB DEFAULT CHARSET=GBK; -
新建 emp 表
CREATE TABLE emp( id INT UNSIGNED PRIMARY KEY AUTO INCREMENT, empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*编号*/ ename VARCHAR(20) NOT NULL DEFAULT "",/*名字*/ job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/ mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT O,/*上级编号*/ hiredate DATE NOT NULL,/*入职时间*/ sal DECIMAL(7,2)NOT NULL,/*薪水*/ comm DECIMAL(7,2) NOT NULL,/*红利*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT O/*部门编号*/ )JENGINE=INNODB DEFAULT CHARSET=GBK
4.2. 设置参数
-
创建函数若报错:This function has none of DETERMINISTIC……
-
设置参数
show variables like 'log_bin _trust_function _creators'; set global log_bin_trust_function_creators=1;
4.3. 创建函数,保证每条数据都不同
-
随机产生字符串
DELIMITER $$ CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255) BEGIN DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR(255) DEFAULT ""; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str = CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1)); SET i=i + 1; END WHILE; RETURN return_str; END $$ -
随机产生部门编号
DELIMITER $$ CREATE FUNCTION rand_num( ) RETURNS INT(5) BEGIN DECLARE i INT DEFAULT O; SET i= FLOOR(100+RAND()*10); RETURN i; END $$
4.4 创建存储过程
-
创建往emp表中插入数据的存储过程
DELIMITER $$ CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10)) BEGIN DECLARE i INT DEFAULT O; #set autocommit =0 把autocommit自动提交设置成0 SET autocommit = 0; REPEAT SET i=i + 1; INSERT INTO emp (empno, ename ,job ,mgr ,hiredate ,sal ,comm ,deptno ) VALUES ((START+i), rand_string(6),'SALESMAN',0001,CURDATE(),2000,400,rand_num()); UNTIL i = max_num END REPEAT; COMMIT; END SS -
创建往dept表中插入数据的存储过程
DELIMITER $$ CREATE PROCEDURE insert_dept(IN START INT(10),IN max num INT(10)) BEGIN DECLARE i INT DEFAULT O; SET autocommit = 0; REPEAT SET i=i+ 1; INSERT INTO dept (deptno ,dname,loc ) VALUES ((START+i) ,rand_string(10),rand_string(8)); UNTIL i = max_num END REPEAT; COMMIT; END $$
4.5 调用存储过程
-
dept
DELIMITER ; CALL insert_dept(100,10); -
emp
DELIMITER ; CALL insert_emp(100001, 500000);
5. show profile
5.1. 简介
- 是 MySQL 提供可以用来分析当前会话中语句执行的资源消耗情况
- 可以用于 SQL 调优
- 默认情况下,参数处于关闭状态,并保存最近 15 次的运行结果
5.2. 使用步骤
-
是否支持,查看当前的 MySql 版本是否支持
-
开启功能,默认是关闭
# 查看是否开启 show variables like 'profiles'; # 开启 set profiling=on; -
运行SQL
select * from emp group by id%10 limit 150000; select * from dept group by id%20 order by 5; -
查看结果
show profiles;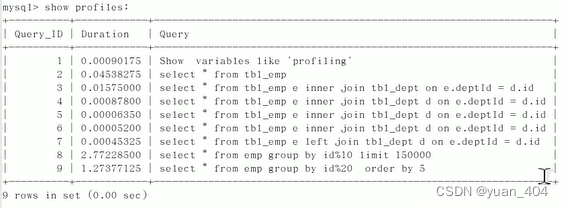
-
诊断SQL
# n 为上一步中的 Query_ID show profile cpu,block io for query n;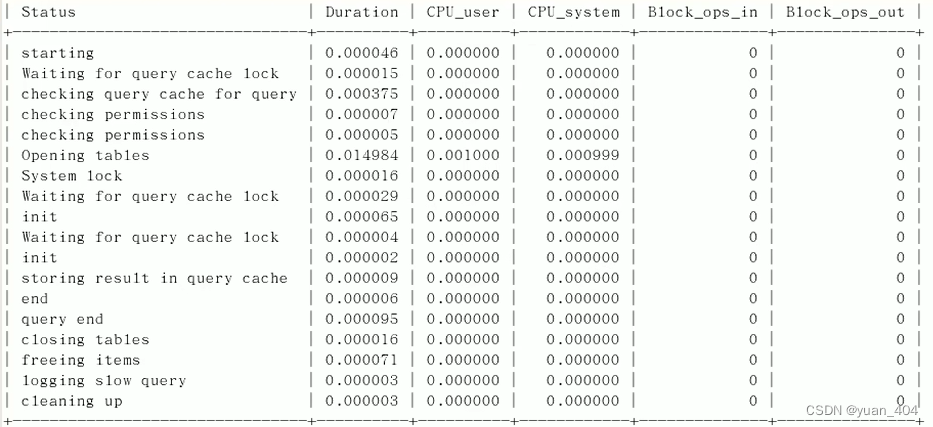
- 处理 CPU 、IO 其他类型

- 日常开发需要注意的结论
- converting HEAP to MyISAM:查询结果太大,内存不够用了,往磁盘上搬了
- Creating tmp table:创建临时表
- Coping to tmp table on disk:把内存中临时表复制到磁盘,(危险)
- locked
6. 全局查询日志
- 配置启用
- 编码启用
此后,所编写的SQL语句,将会记录到 MySql 中的 general_log 表,可以使用以下命令查看set global general_log=1; set global log_output='TABLE';select * from mysql.general_log; - 不要在正式环境使用















 209
209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











