







目录
一、数值型描述性统计:PROC MEANS
默认:针对数值型变量,并求其统计量。
输出的默认格式:BEST.
字符型变量和分类变量不输出
1、基本格式:
PROC MEANS <DATA=data-set> <STATISTIC-KEYWORD(S)> <OPTION(S)>;
RUN;miya.fbg数据集如下,共50条:
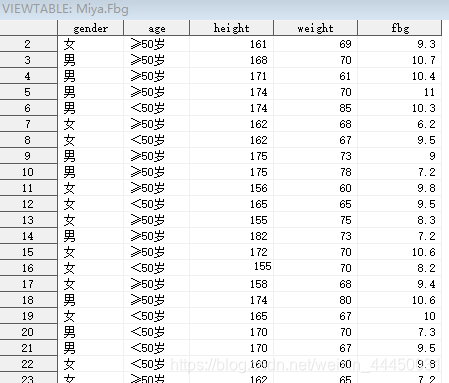
PROC MEANS data=miya.fbg;
RUN;输出结果为miya.fbg数据集中所有数值型变量的默认统计量
打印顺序为:variable,N,MEAN,STDDEV,MIN,MAX
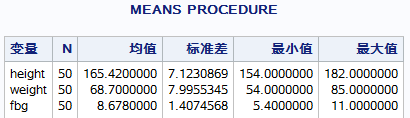
proc means data=miya.fbg median range;
run;输出结果为miya.fbg数据集中所有数值型变量的median range统计量
打印顺序为:variable,MEDIAN,RANGE
2、options:
proc means data=miya.fbg maxdec=2;
run; 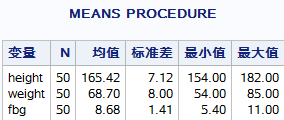
3、statistic-keywords:
若不加统计关键词,默认打印的顺序: 非缺失值个数(N),均值(MEAN),标准差(STDDEV),最小值(MIN),最大值(MAX)。
| 统计量 | 描述 |
|---|---|
| MAX | 最大值 |
| MIN | 最小值 |
| MEAN | 均值 |
| MEDIAN | 中位数 |
| N | 非缺失值个数 |
| NMISS | 缺失值个数 |
| STDDEV | 标准差 |
| SUM | 总和 |
3、语句
BY:
指定分组变量,分组后按分组变量生成多张表;
数据集按照by后的变量排序,才可以使用,效率更高。
proc sort data=miya.fbg;
by gender age;
run;
proc means data=miya.fbg maxdec=2;
by gender age;
run;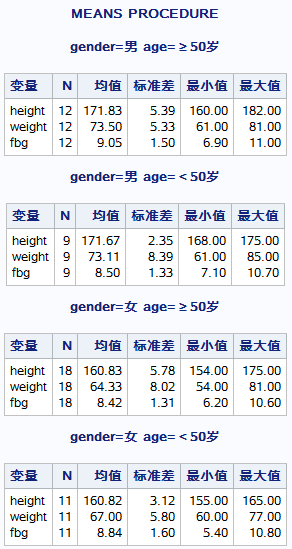
CLASS
指定分组变量,分组显示在同一张表中。
proc means data=miya.fbg maxdec=2;
class gender age;
run;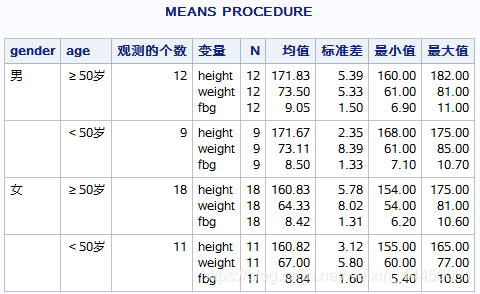
VAR
指定分析的数值变量,默认为所有的数值变量。
proc means data=miya.fbg maxdec=2;
var fbg height;
class gender;
run;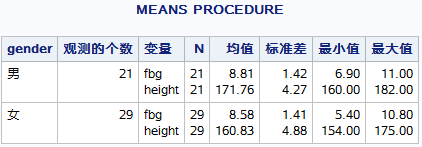
OUTPUT语句
将统计量生成数据集
基本格式:
OUTPUT OUT=data-set <STATISTIC-KEYWORD=variable-name>;proc means过程虽然有output语句,但执行完毕后只显示描述性统计,而没有work.sum_gender数据集中内容
若要输出work.sum_gender数据集中的内容需要在加上proc print语句。
proc means data=miya.fbg;
var fbg height weight;
class gender;
output out=work.sum_gender
mean=AvgFbg AvgHeight AvgWeight
min=MinFbg MinHeight MinWeight;/*与Var语句的分析变量个数相同,变量名可以自定义*/
run;
proc print data=sum_gender;
run;二、字符型描述性统计 :PROC FREQ
不仅仅针对字符型数据,主要是统计一些频数,百分比等信息
1、基本格式:
PROOC FREQ <DATA=DATASET>;
RUN;proc freq data=miya.fbg;
run; 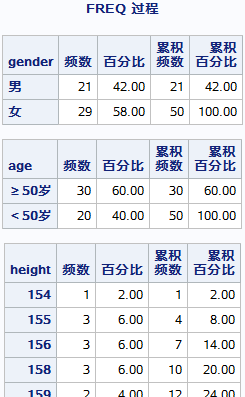
默认维度:一维
默认输出:频数(对分类变量有意义)、百分比、累计频数、累计百分比
默认对象:所有变量,每个变量一个表
2、table语句:
基本语法一:
生成一维的表,几个分析变量几个表,筛选变量。
选项NOCUM:不显示累计频数和累计百分比
PROOC FREQ <DATA=DATASET>;
TABLES variable-1 variable-2 ... variable-n /option;
RUN;基本语法二:
生成二维表,可以通过option选项控制是否输出
选项:
NOFREQ: 不显示某个单元格频数
NOPERCENT: 不显示总百分比
NOROW: 不显示行百分比
NOCOL: 不显示行百分比
MISSING: 在频数和百分数中包括缺失值
PROOC FREQ <DATA=DATASET>;
TABLES variable-1*variable-2 /options;
RUN;















 141
141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











