







文章目录
一 基本介绍
1.1 简介
- ES是建立在Lucene基础之上的分布式准实时搜索引擎,它所提供的诸多功能中有一大优点,即实时性好。那么什么是实时性好呢?在一般的业务需求中,新增加的数据至少要1min才能被搜索到,而在ES中,数秒甚至1s内即可搜索到新增的数据。
- 除了良好的实时性外,ES还提供了很多优秀的功能。例如,ES是分布式的架构设计,当单台或者少量的计算机不能很好地支持搜索任务时,完全可以扩展到足够多的计算机上进行搜索;以往在使用Lucene时,需要用户有Java语言基础,而ES提供了REST风格的API接口,使用户可以借助任何语言使用HTTP对ES执行请求来完成搜索任务;ES本身还提供了聚合功能,用户可以使用该功能对索引中的数据进行统计分析;在数据安全方面,ES提供了X-Pack进行用户验证。
- 如今,ES不仅是一个搜索引擎框架,而且其官方还提供了ELK“全家桶”,为构建搜索引擎提供了很好的解决方案。其中,E代表Elasticsearch,主要提供数据搜索和分析功能;L代表Logstash,借助它可以将数据库和日志等结构化或非结构化数据轻松地导入ES中;K代表Kibana,它可以将分析结果进行图形化展示,此外还可以使用它提供的开发工具对ES进行请求的交互。
1.2 基本概念
1.2.1 索引
在使用传统的关系型数据库时,如果对数据有存取和更新操作,需要建立一个数据库。相应地,在ES中则需要建立索引。用户的数据新增、搜索和更新等操作的对象全部对应索引。但是,ES中的索引和Lucene中的索引不是一一对应的。ES中的一个索引对应一个或多个Lucene索引,这是由其分布式的设计方案决定的。
1.2.2 文档
在使用传统的关系型数据库时,需要把数据封装成数据库中的一条记录,而在ES中对应的则是文档。ES的文档中可以有一个或多个字段,每个字段可以是各种类型。用户对数据操作的最细粒度对象就是文档。ES文档操作使用了版本的概念,即文档的初始版本为1,每次的写操作会把文档的版本加1,每次使用文档时,ES返回给用户的是最新版本的文档。另外,为了减轻集群负载和提升效率,ES提供了文档的批量索引、更新和删除功能。
1.2.3 字段
一个文档可以包含一个或多个字段,每个字段都有一个类型与其对应。除了常用的数据类型(如字符串型、文本型和数值型)外,ES还提供了多种数据类型,如数组类型、经纬度类型和IP地址类型等。
1.2.4 隐射
建立索引时需要定义文档的数据结构,这种结构叫作映射。在映射中,文档的字段类型一旦设定后就不能更改。因为字段类型在定义后,ES已经针对定义的类型建立了特定的索引结构,这种结构不能更改。借助映射可以给文档新增字段。另外,ES还提供了自动映射功能,即在添加数据时,如果该字段没有定义类型,ES会根据用户提供的该字段的真实数据来猜测可能的类型,从而自动进行字段类型的定义。
1.2.5 集群与节点
在分布式系统中,为了完成海量数据的存储、计算并提升系统的高可用性,需要多台计算机集成在一起协作,这种形式被称为集群,这些集群中的每台计算机叫作节点。ES集群的节点个数不受限制,用户可以根据需求增加计算机对搜索服务进行扩展。
1.2.6 分片
在分布式系统中,为了能存储和计算海量的数据,会先对数据进行切分,然后再将它们存储到多台计算机中。这样不仅能分担集群的存储和计算压力,而且在该架构基础上进一步优化,还可以提升系统中数据的高可用性。在ES中,一个分片对应的就是一个Lucene索引,每个分片可以设置多个副分片,这样当主分片所在的计算机因为发生故障而离线时,副分片会充当主分片继续服务。索引的分片个数只能设置一次,之后不能更改。在默认情况下,ES的每个索引设置为5个分片。
1.2.7 副分片
为了提升系统索引数据的高可用性并减轻集群搜索的负载,可以启用分片的副本,该副本叫作副分片,而原有分片叫作主分片。在一个索引中,主分片的副分片个数是没有限制的,用户可以按需设定。在默认情况下,ES不会为索引的分片开启副分片,用户需要手动设置。副分片的个数设定后,也可以进行更改。一个分片的主分片和副分片分别存储在不同的计算机上,所示为一个3个节点的集群,某个索引设置了3个主分片,每个主分片分配两个副分片。深色方框中的P表示该分片为主分片,R表示该分片为副分片,P和R后面的数字表示其编号。在极端情况下,当只有一个节点时,如果索引的副分片个数设置大于1,则系统只分配主分片,而不会分配副分片。
1.2.8 DSL
使用DSL(Domain Specific Language,领域特定语言),来定义查询。与编程语言不同,DSL是在特定领域解决特定任务的语言,它可以有多种表达形式,如我们常见的HTML、CSS、SQL等都属于DSL。
ES中的DSL采用JSON进行表达,相应地,ES也将响应客户端请求的返回数据封装成了JSON形式。这样不仅可以简单明了地表达请求/响应内容,而且还屏蔽了各种编程语言之间数据通信的差异。
1.3 Elasticsearch和关系型数据库的对比
1.3.1 索引方式
关系型数据库的索引大多是B-Tree结构,而ES使用的是倒排索引,两种不同的数据索引方式决定了这两种产品在某些场景中性能和速度的差异。
1.3.2 事务支持
事务是关系型数据库的核心组成模块,而ES是不支持事务的。ES更新文档时,先读取文档再进行修改,然后再为文档重新建立索引。如果同一个文档同时有多个并发请求,则极有可能会丢失某个更新操作。
ES使用了乐观锁,即假定冲突是不会发生的,不阻塞当前数据的更新操作,每次更新会增加当前文档的版本号,最新的数据由文档的最新版本来决定,这种机制就决定了ES没有事务管理。
1.3.3 SQL与DSL
SQL和DSL都有自己的语法结构,都是各自和用户之间进行交互的一种语言表达方式。SQL是关系型数据库使用的语言,主要是因为SQL查询的逻辑比较简单和直接,一般是大小、相等之类的比较运算,以及逻辑与、或、非的关系运算。
ES不仅包含上述运算,而且支持文本搜索、地理位置搜索等复杂数据的搜索,因此ES使用DSL查询进行请求通信。虽然ES的高版本也开始支持SQL查询,但若需要完成比较复杂的数据搜索需求,使用DSL查询会更加方便快捷。
1.3.4 扩展方式
关系型数据库的扩展,需要借助第三方组件完成分库分表的支持。分库分表即按照某个ID取模将数据打散后分散到不同的数据节点中,借此来分摊集群的压力。但是分库分表有多种策略,需要使用人员对业务数据特别精通才能进行正确的选择。另外,分库分表会对一些业务造成延迟,如查询结果的合并及多表Join操作。
ES本身就是支持分片的,只要初期对分片的个数进行了合理的设置,后期是不需要对扩展过分担心的,即使现有集群负载较高,也可以通过后期增加节点和副分片的方式来解决。
1.3.5 数据查询速度
在少量字段和记录的情况下,传统的关系型数据库的查询速度非常快。如果单表有上百个字段和几十亿条记录,则查询速度是比较慢的。虽然可以通过索引进行缓解,但是随着数据量的增长,查询速度还是会越来越慢。
ES是基于Lucene库的搜索引擎,可以支持全字段建立索引。在ES中,单个索引存储上百个字段或几十亿条记录都是没有问题的,并且查询速度也不会变慢。
1.3.6 数据实时性
关系型数据库存储和查询数据基本上是实时的,即单条数据写入之后可以立即查询。
为了提高数据写入的性能,ES在内存和磁盘之间增加了一层系统缓存。ES响应写入数据的请求后,会先将数据存储在内存中,此时该数据还不能被搜索到。内存中的数据每隔一段时间(默认为1s)被刷新到系统缓存内,此时数据才能被搜索到。因此,ES的数据写入不是实时的,而是准实时的。
1.4 基本架构
1.4.1 节点职责
- 节点按照职责可以分为master节点、数据节点和协调节点,每个节点类型可以进行单独配置。
- master节点负责维护整个集群的相关工作,管理集群的变更,如创建/删除索引、节点健康状态监测、节点上/下线等。master节点是由集群节点通过选举算法选举出来的,一个集群中只有一个节点可以成为master节点,但是可以有一个或多个节点参与master节点的选举。
- 数据节点主要负责索引数据的保存工作,此外也执行数据的其他操作,如文档的删除、修改和查询操作。数据节点的很多工作是调用Lucene库进行Lucene索引操作,因此这种节点对于内存和I/O的消耗比较大,生产环境中应多注意数据节点的计算机负载情况。
- 客户端可以向ES集群的节点发起请求,这个节点叫作协调节点。在默认情况下,协调节点可以是集群中的任意节点,此时它的生命周期是和一个单独的请求相关的。
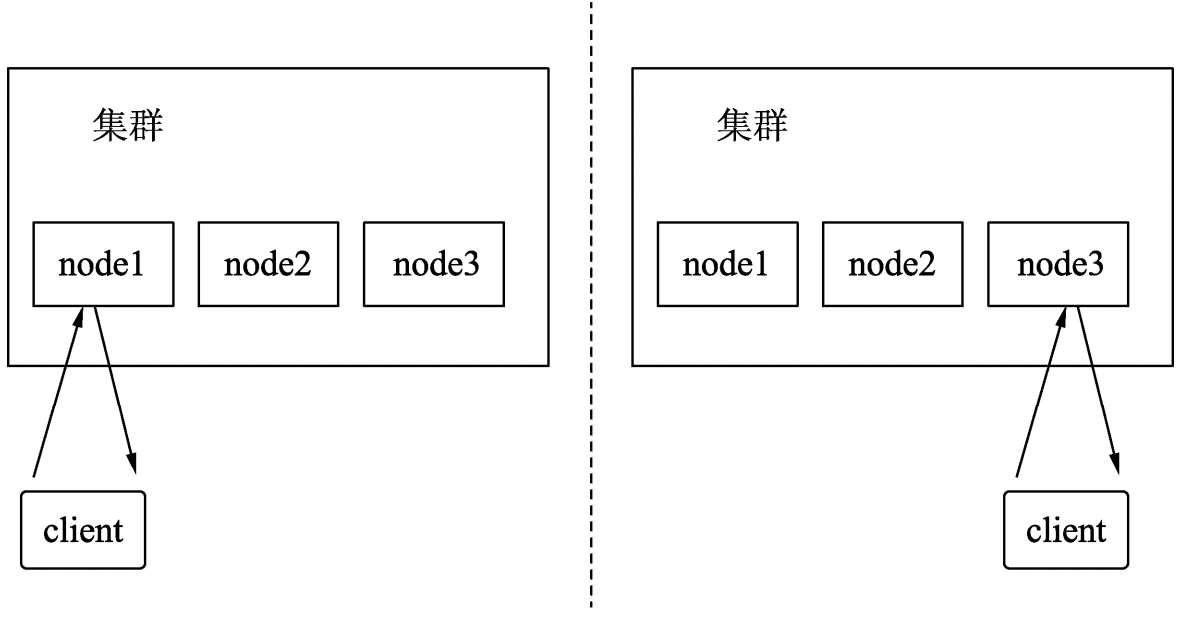
1.4.2 主分片与副分片
ES为了支持分布式搜索,会把数据按照分片进行切分。一个索引由一个或者多个分片构成,并且每个分片有0个甚至多个副分片。多个分片分布在不同的节点中,通过这种分布式结构提升了分片数据的高可用性和服务的高并发支持。
集群中的索引主分片和副分片在不同的计算机上,如果某个主分片所在的节点宕机,则原有的某个副分片会提升为主分片继续对外进行服务。
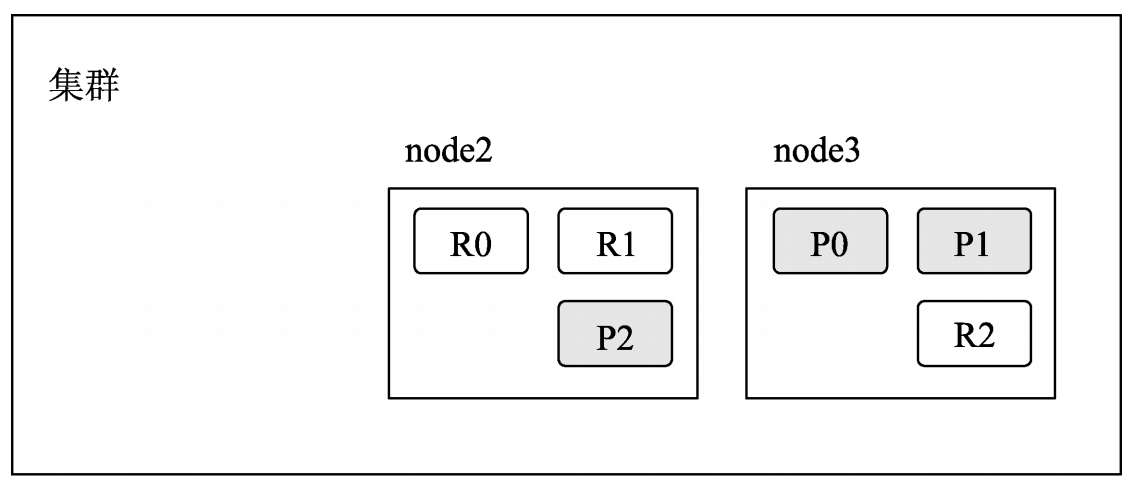
- 如果node1发生故障宕机,集群感知到分片0的主分片P0将要丢失,此时集群会立即将其他节点(如node3)上的分片0对应的副分片R0作为主分片P0进行服务。集群中由node2和node3对外提供服务,所有的分片相关的服务不受影响
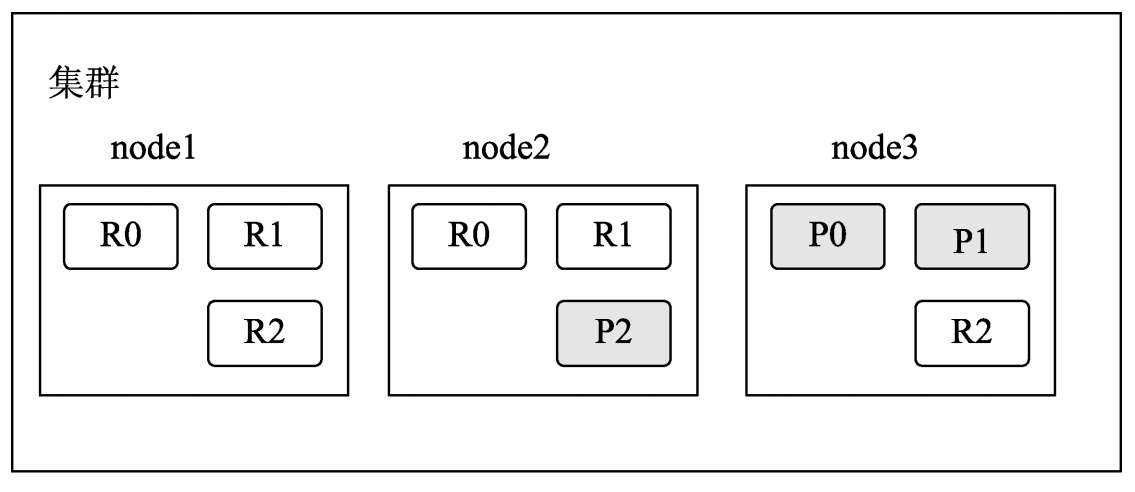
- 如果node1恢复了服务并加入集群中,因为在node1上还保留有分片0的数据,此时node1上的分片P0会变成副分片R0,在此期间缺失的数据会通过node3上的主分片P0进行补充。并且node1上的分片R1和R2也会分别从node3和node2上对应的P1和P2分片上补充数据。
1.4.3 路由计算
当客户端向一个ES协调节点发送一条数据的写入请求时,协调节点如何确认当前数据应该存储在哪个节点的哪个分片上呢?
- 协调节点根据数据获取分片ID的计算公式如下:shard=hash(routing)%number_of_primary_shards
- routing代表每条文档提交时的参数,该值是可变的,用户可以自定义,在默认情况下使用的是文档的_id值;number_of_primary_shards是索引中主分片的个数。计算routing的哈希值后,除以索引的主分片数再取余,就是当前文档实际应该存储的分片ID。
1.4.4 文档的读写过程
- 当ES协调节点接收到来自客户端对某个索引的写入文档请求时,该节点会根据一定的路由算法将该文档映射到某个主分片上,然后将请求转发到该分片所在的节点。
- 完成数据的存储后,该节点会将请求转发给该分片的其他副分片所在的节点,直到所有副分片节点全部完成写入,ES协调节点向客户端报告写入成功。
写过程
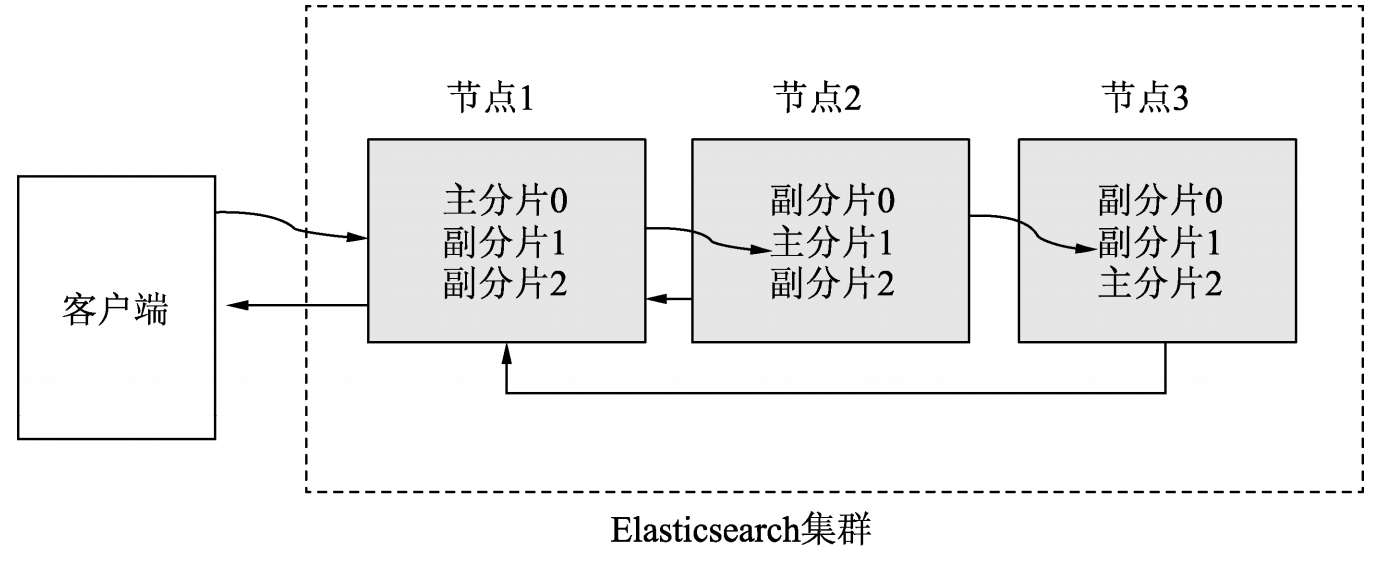
假设索引中只有3个主分片和6个副分片,客户端向节点1发起向索引写入一条文档的请求,在本次请求中,节点1被称为协调节点。节点1判断数据应该映射到哪个分片上。假设将数据映射到分片1上,因为分片1的主分片在节点2上,因此节点1把请求转发到节点2上。节点2接收客户端的数据并进行存储,然后把请求转发到副分片1所在的节点1和节点3上,当所有副分片所在的节点全部完成存储后,协调节点也就是节点1向客户端返回成功标志。
读过程
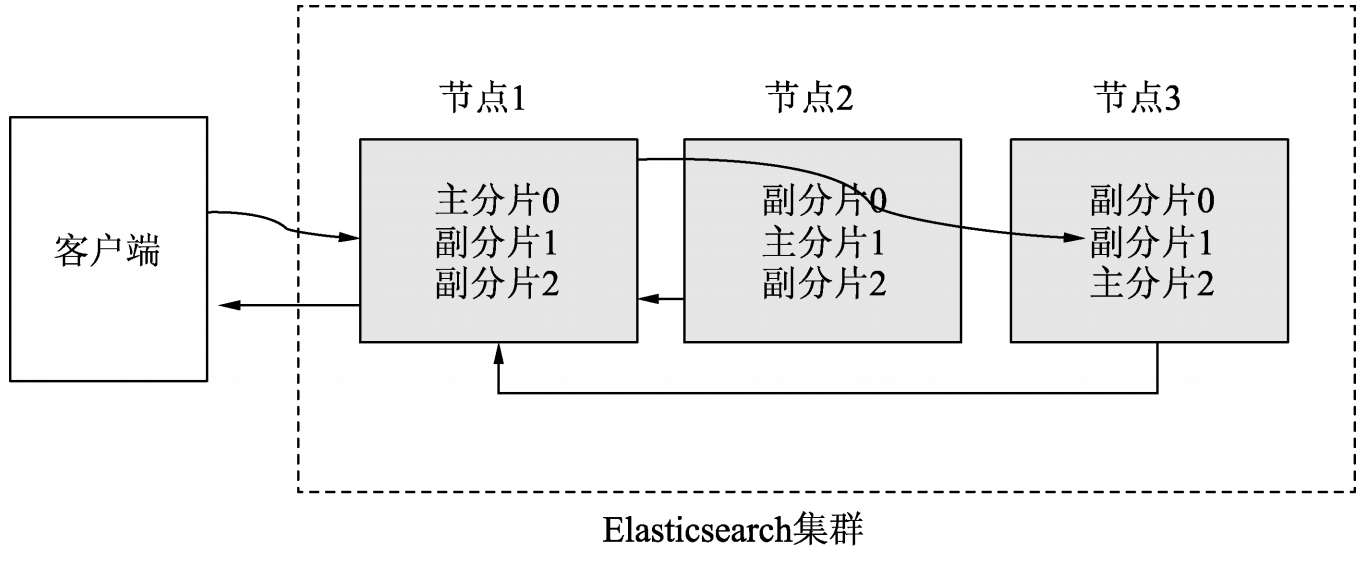
假设索引中只有3个主分片和6个副分片,客户端向节点1发起向索引获取文档的请求,在本次请求中,节点1被称为协调节点。节点1判断数据应该映射到哪个分片上。假设将数据映射到分片1上,分片1有主/副两种分片,分别在节点2、节点1和节点3上。假设此时协调节点的轮询算法选择的是节点3,那么它会将请求转发到节点3上,然后节点3会把数据传输给协调节点,也就是节点1,最后由节点1向客户端返回文档数据。
1.5 使用场景
1.5.1 搜索引擎
毫无疑问,ES最擅长的是充当搜索引擎,在这类场景中较典型的应用领域是垂直搜索,如电商搜索、地图搜索、新闻搜索等各类站内搜索。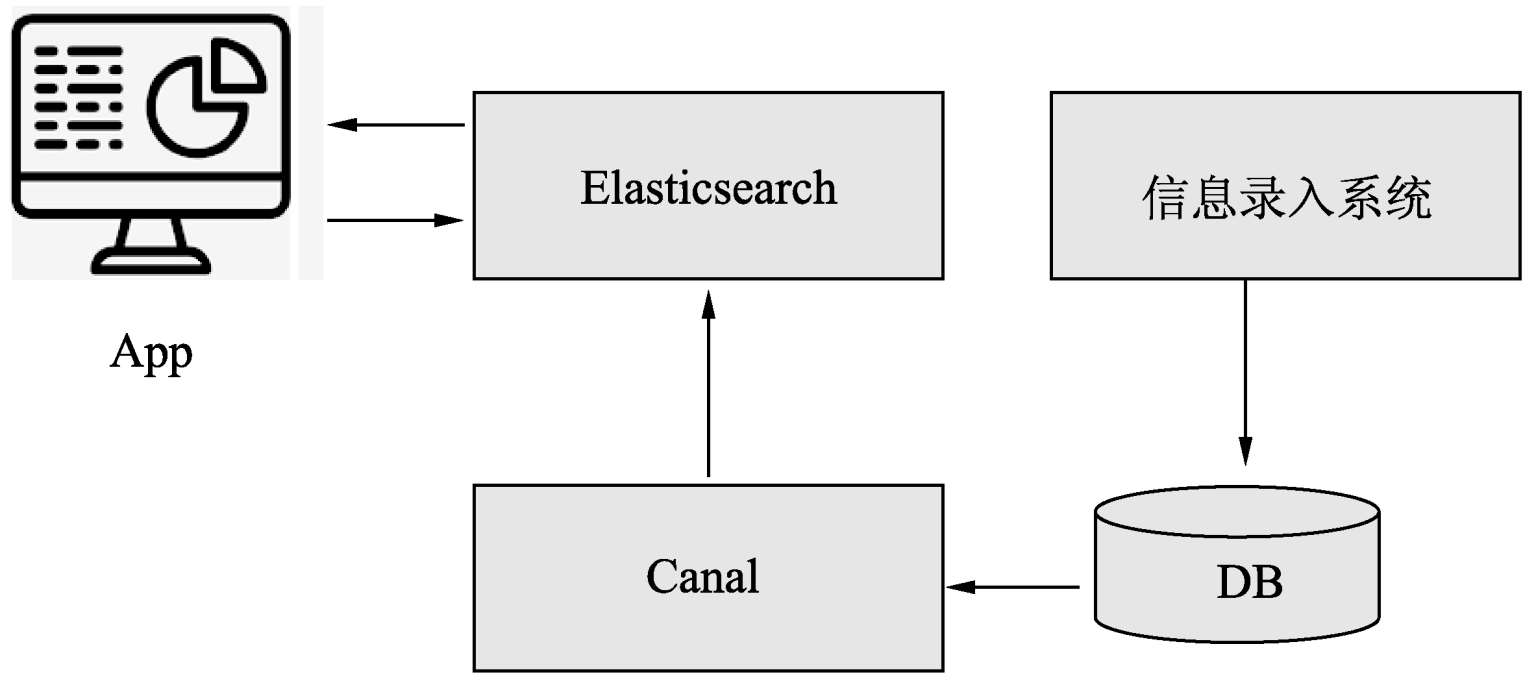
1.5.2 推荐系统
ES在高版本(7.0及以上版本)中引入了高维向量的数据类型。可以把推荐模型算法计算的商品和用户向量存储到ES索引中,当实时请求时,加载用户向量并使用ES的Script Score进行查询,使每个文档最终的排序分值等于当前用户向量与当前文档向量的相似度。为同时满足实时向量计算和实时数据过滤的需求,可以在ScriptScore查询中添加filter(即过滤条件,如库存、上下架状态等)。
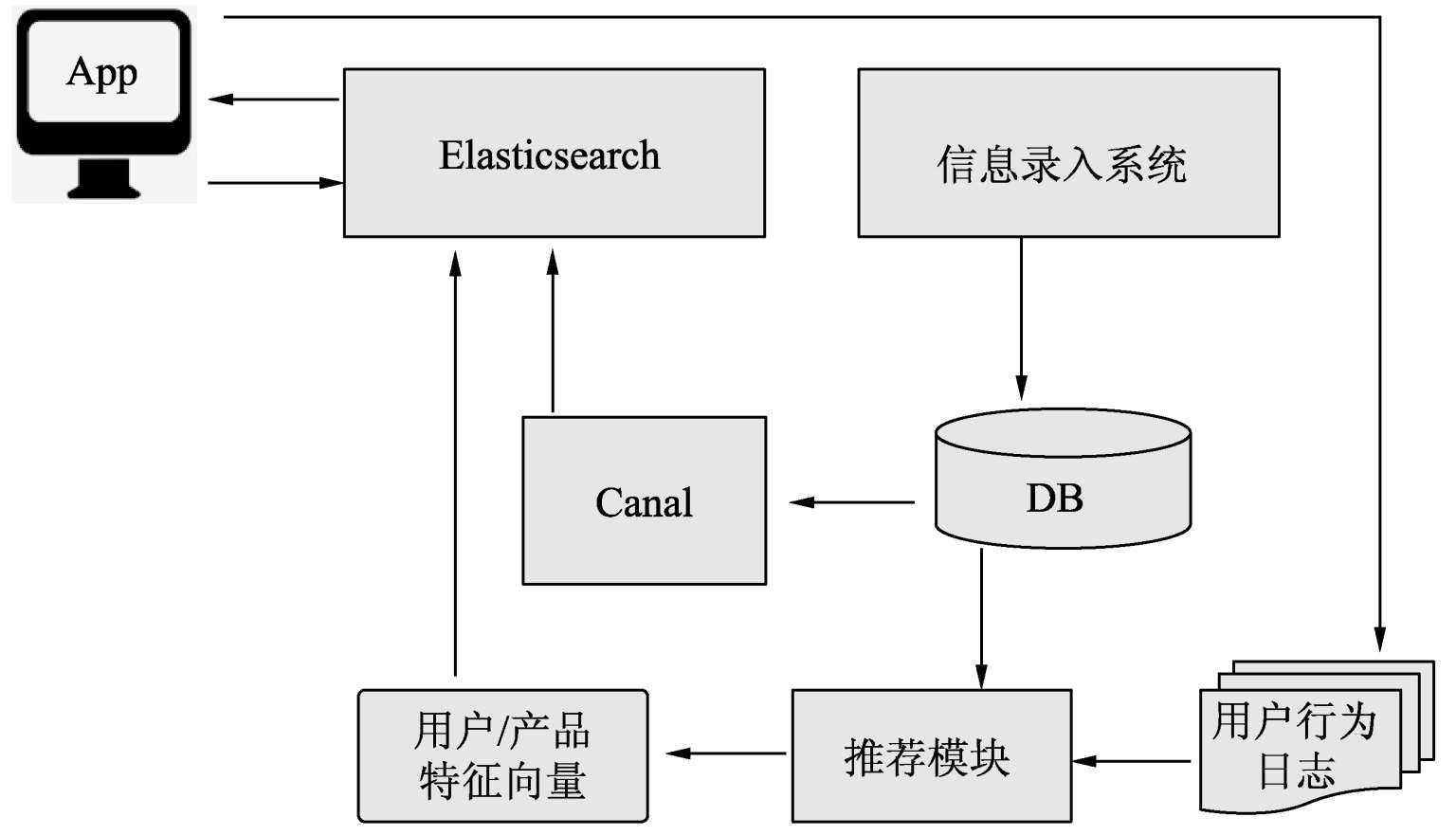
1.5.3 日志分析
在一些使用场景下,我们需要对用户的修改,删除,操作日志进行记录,并分析数据。
1.6 安装
1.6.1 单机安装
下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-8-0
window安装,解压直接使用
- 出于安全性考虑,ES不允许用root账户启动,应创建其他账户启动ES。
- 对基本的入门使用而言,ES的默认配置已经是最佳配置,用户不需要更改配置文件即可启动。
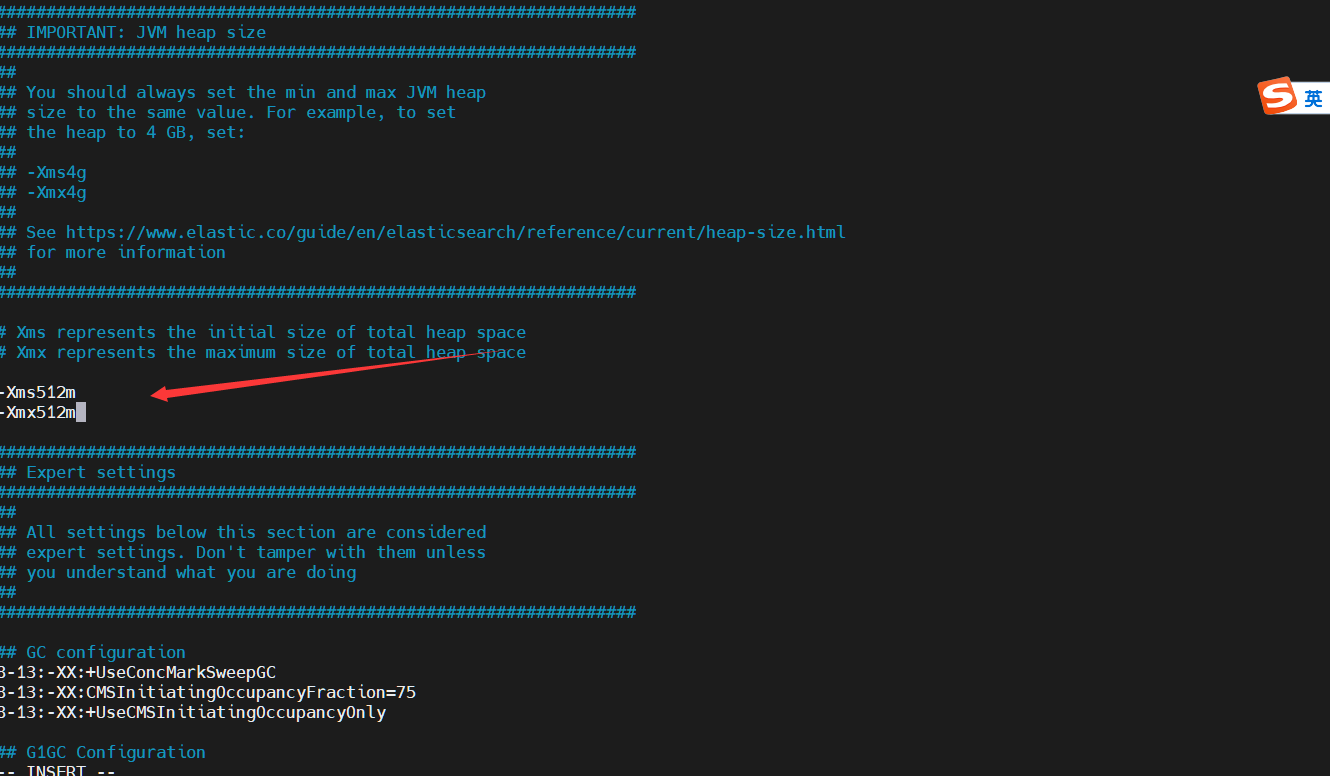
- 需要指出的是,在默认情况下,配置文件中ES进程占用的内存为1GB。如果计算机的内存较小,需要更改config/jvm.options配置文件,修改其中的-Xms和-Xmx参数值到合适的值即可。
- 通过执行bin/elasticsearch命令可以启动ES,如果需要在后台运行,则执行bin/elasticsearch-d命令即可。
linux 安装
- 将上传安装包上传服务器
- 解压命令
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz
- 修改JVM参数
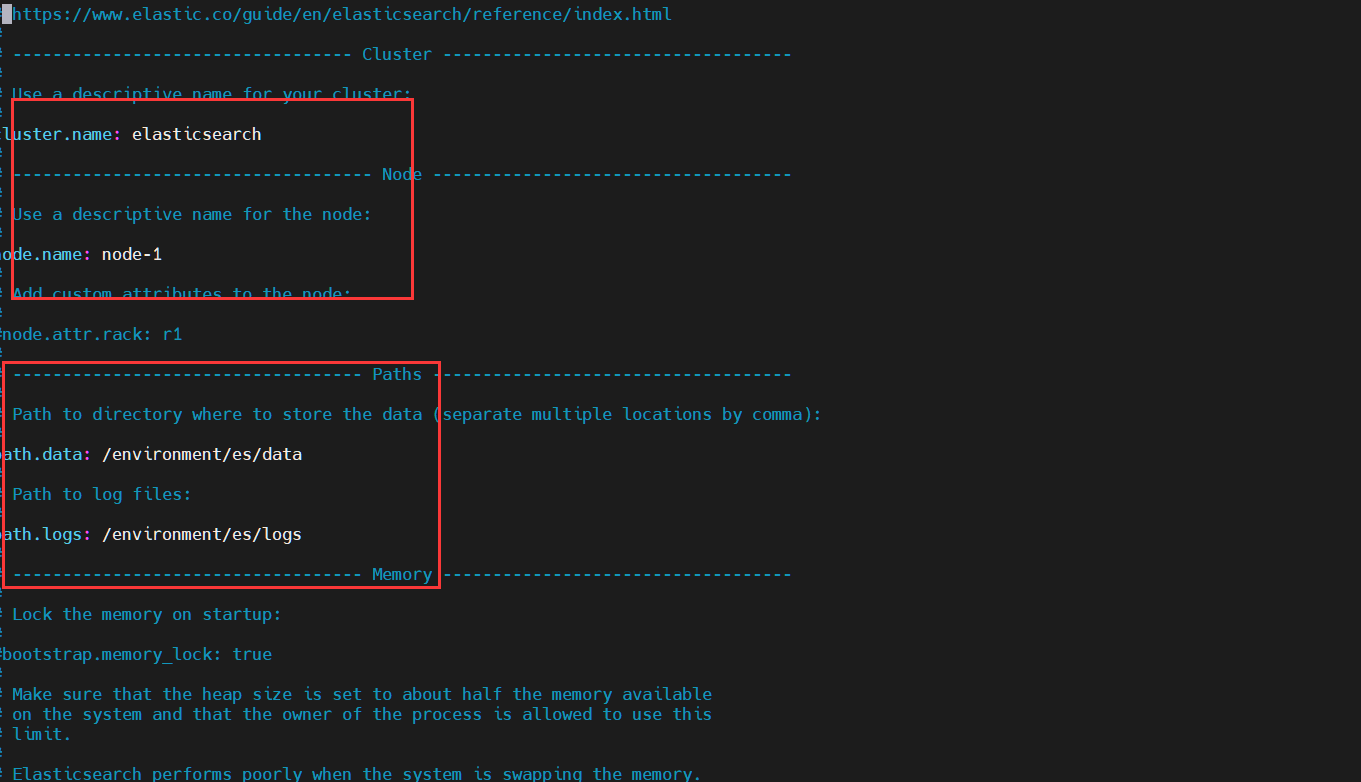
- 修改数据地方与日志文件
| 属性名 | 说明 |
|---|---|
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
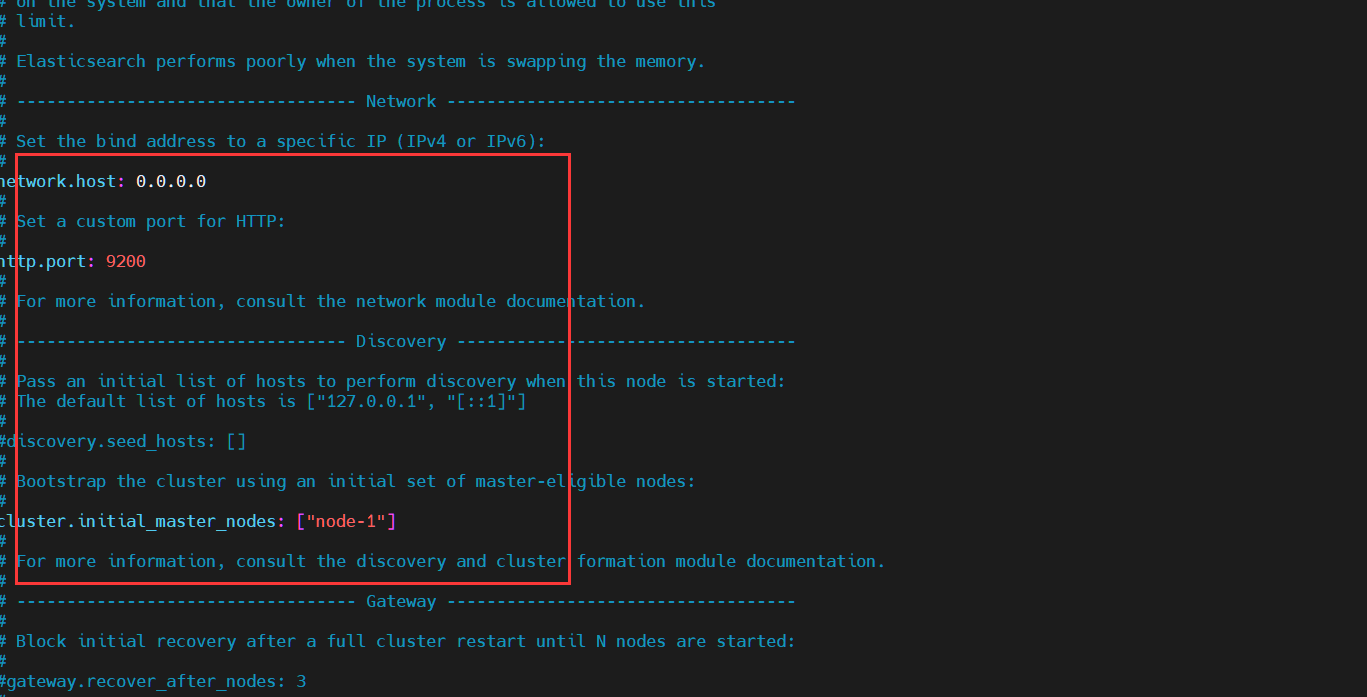
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
- 修改/etc/security/limits.conf文件 增加配置
vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
vi /etc/sysctl.conf
vm.max_map_count=655360
sysctl -p
- 创建用户
创建用户:useradd esuser
设置密码:passwd esuser
- 启动
切换创建用户,并授权,注意授权文件夹
chgrp -R esuser ./es
chown -R esuser ./es
chmod 777 es
# 启动
./bin/elasticsearch -d
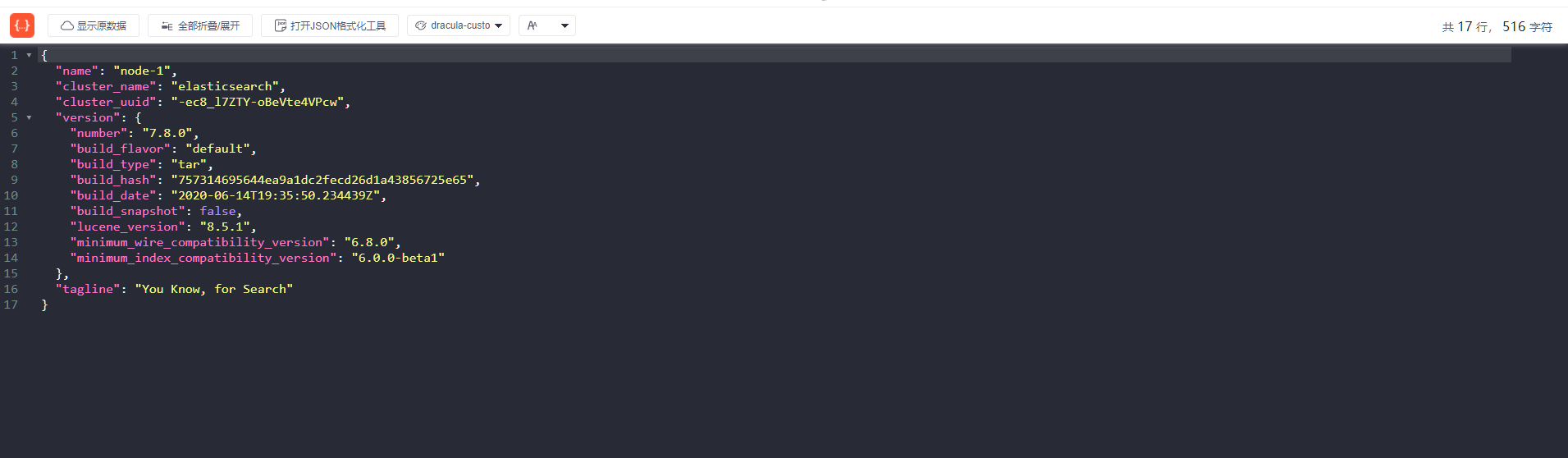
访问:ip:9200
1.6.2 集群搭建
后期补充















 2740
2740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











