







 本文介绍了一种在Shell环境中使用XPath解析HTML的方法。通过Python编写并打包成可执行文件,该工具可在无Python环境的Linux系统上运行。文中详细说明了安装与使用步骤,并提供了示例。
本文介绍了一种在Shell环境中使用XPath解析HTML的方法。通过Python编写并打包成可执行文件,该工具可在无Python环境的Linux系统上运行。文中详细说明了安装与使用步骤,并提供了示例。
发布于:2022-01-17 22:02:39
shell解析html
没有找到shell有这个功能,百度shell解析xpath所说不知都是什么,命令没找到包也没装上,很怀念Python这方面的优异,索性自己封装了一层.
采用Python语言,写好后打包制作而成,源码及打包命令见文章尾部,之所以打包一下因为这样可以不依赖Python环境只需要在Linux系统主机即可执行(基于centos 7系统测试),如果主机有Python环境和相关依赖直接执行代码文件也可.
如有疑问或问题欢迎大佬留言.
下载地址(百度网盘):
链接: https://pan.baidu.com/s/1eboXIJD-5JR30BRRsPTNjQ?pwd=9snv 提取码: 9snv 复制这段内容后打开百度网盘手机App,操作更方便哦
蓝奏云网盘
https://wwi.lanzouw.com/i7QpFywyjed
安装方法
[root@emr-header-01 tmp]# ls
xpath.tar.gz
[root@emr-header-01 tmp]# tar xf xpath.tar.gz
[root@emr-header-01 tmp]# ls
xpath xpath.tar.gz
[root@emr-header-01 tmp]# chown 755 xpath
[root@emr-header-01 tmp]# mv xpath /usr/bin/
[root@emr-header-01 tmp]#
- 下载上传
- 解压,执行
tar xf xpath.tar.gz - 授权,如果没有执行权限的话.
chown 755 xpath - 移动到bin目录下
mv xpath /usr/bin/.
使用方法
首先准备一个页面,下载保存到本地.
示例网址: https://so.gushiwen.cn/shiwenv_1fecfb7d6ac8.aspx
网站页面内容:
# 开始获取 将内容保存为文件
[root@emr-header-02 ~]# curl -o caiwei https://so.gushiwen.cn/shiwenv_1fecfb7d6ac8.aspx
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 34827 0 34827 0 0 423k 0 --:--:-- --:--:-- --:--:-- 419k
[root@emr-header-02 ~]# ls
anaconda-ks.cfg caiwei tmp xpath.tar.gz zookeeper.out
[root@emr-header-02 ~]#
解析内容使用示例
# 获取文本内容
[root@emr-header-02 ~]# xpath --file=caiwei --path="/html/body/div[2]/div[1]/div[2]/div[1]/div[2]/p/text()"
采薇采薇,薇亦作止。曰归曰归,岁亦莫止。 靡室靡家,猃狁之故。不遑启居,猃狁之故。
采薇采薇,薇亦柔止。曰归曰归,心亦忧止。 忧心烈烈,载饥载渴。我戍未定,靡使归聘。
采薇采薇,薇亦刚止。曰归曰归,岁亦阳止。 王事靡盬,不遑启处。忧心孔疚,我行不来!
彼尔维何?维常之华。彼路斯何?君子之车。 戎车既驾,四牡业业。岂敢定居?一月三捷。
驾彼四牡,四牡骙骙。君子所依,小人所腓。 四牡翼翼,象弭鱼服。岂不日戒?猃狁孔棘!
昔我往矣,杨柳依依。今我来思,雨雪霏霏。 行道迟迟,载渴载饥。我心伤悲,莫知我哀!
# 取其中的某个元素 如src='xxx'
[root@emr-header-02 ~]# xpath --file=caiwei --path="/html/body/div[2]/div[1]/div[2]/div[2]/div[1]/img/@src"
https://song.gushiwen.cn/siteimg/shou-cang.png
# 当出现异常时会返回不同的状态码,如果成功则返回0,可以以此判断执行是否成功,示例
[root@emr-header-02 ~]# xpath --file=caiwei.html --path="//*[@id="sonsyuanwen"]/div[1]/h1/text()"
没有找到文件!
[root@emr-header-02 ~]# echo $?
2
[root@emr-header-02 ~]# xpath --file=caiwei --path="//*[@id="sonsyuanwen"]/div[1]/h1/text()a"
xpath解析异常!
[root@emr-header-02 ~]# echo $?
3
# 取文章名称,获取结果成功返回 0
[root@emr-header-02 ~]# xpath --file=caiwei --path="/html/body/div[2]/div[1]/div[2]/div[1]/h1/text()"
采薇
[root@emr-header-02 ~]# echo $?
0
[root@emr-header-02 ~]# xpath --help
Usage: xpath [OPTIONS]
Options:
--file TEXT read code file name.
--path TEXT xpath path.
--help Show this message and exit.
[root@emr-header-02 ~]#
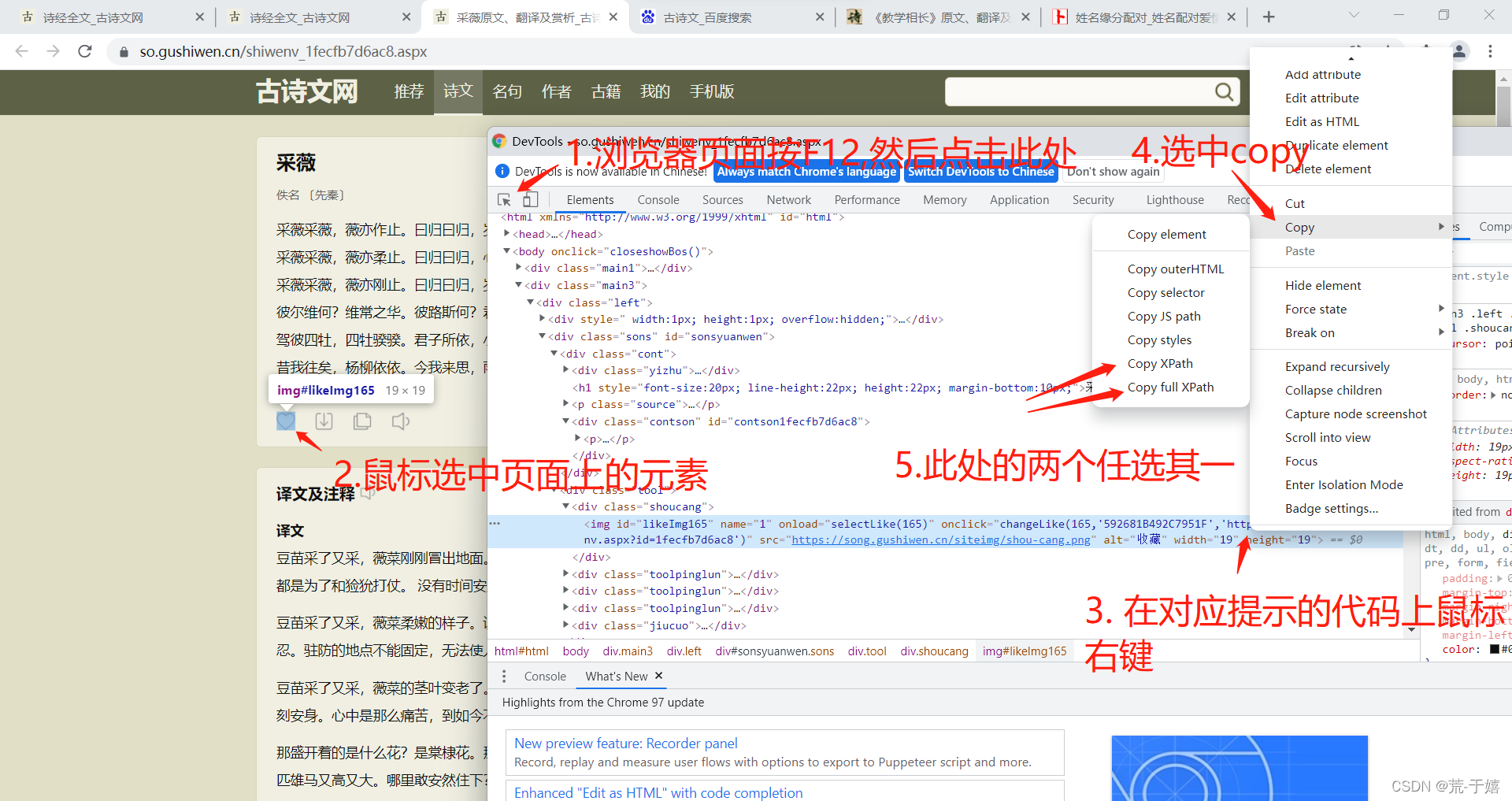
xpath地址获取方法
以Google浏览器为例
更多相关操作参考:
https://www.w3school.com.cn/xpath/index.asp
https://www.runoob.com/xpath/xpath-syntax.html
https://baike.baidu.com/item/XPath/5574064?fr=aladdin
源码及编译
源码
from lxml import etree
import click
import sys
# 获取参数
@click.command()
@click.option('--file', help='read code file name.')
@click.option("--path",help="xpath path.")
def parsing(file,path):
# 判断是否传入足够的参数
if file == None or path == None:
print("请指定--file和--path,或添加参数--help查看帮助.")
#return False
sys.exit(1)
try:
# 打开文件 读取数据
with open(file,mode="r",encoding='utf8') as r:
htmlData = r.read()
except FileNotFoundError:
print("没有找到文件!")
sys.exit(2)
# 装载HTML代码数据
xpath = etree.HTML(htmlData)
try:
# 解析地址 获取对应返回值
data = xpath.xpath(path)
except:
print("xpath解析异常!")
sys.exit(3)
if data == []:
print("没有找到任何数据,请检查地址是否正确")
else:
# 循环列表 打印内容
for i in data:
print(i)
if __name__ == '__main__':
# parsing("jianjia.html",'/html/body/div[2]/div[1]/div[2]/div[1]/div[2]/p/text()')
parsing()
python所写,主要使用了lxml包的etree.
编译
首先有一台装好Python3的主机,配置好pip.
安装打包命令
pip install pyinstaller
在代码文件放置位置执行
# main.py 为文件名称
pyinstaller -F main.py
# 执行完毕后在当前目录下有个dist目录,里面为二进制可执行包.
相关问题
- 从浏览器复制的xpath地址解析不到任何东西
可参考:Python lxml模块xpath解析不到内容
解决方案:Linux可以先使用curl将页面保存到本地,然后用浏览器打开保存的文件,F12控制台中重新复制xpath地址.

















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









