







之前,学习了张量的一系列操作,随着操作种类和数量的增多,会导致各种各样的问题,比如多个操作之间是并行还是顺行,如何协同不同底层设备,以及如何避免各种冗余的操作等等。这些问题会影响运算效率,甚至会引入一些不必要的bug。
计算图就是为解决这类问题而产生的。
一、计算图
计算图是用来描述运算的有向无环图,有两个主要元素:结点(Node)和边(Edge)
结点表示数据,如向量,矩阵,张量边表示运算,如加减乘除卷积,激活函数等
举例 用计算图表示: y= (x+ w) * (w+1) 令a =X+W,b=w+1,则y=a*b
如图:

采用运算图来描述运算的好处:让运算更加简洁、使得梯度求导更加方便
看一看y对w求导的过程


按图中数值进行计算后,w的梯度为5
y对w求导,其实就是在计算图中,找到所有y到w的路径,把路径上的导数进行求和。
叶子结点:用户创建的结点为叶子结点,如x与w (叶子结点是整个计算图的根基,十分关键,上图中不论是a,b还是y都要根据x和w进行计算的。在反向传播过程中,所有梯度的计算都要依赖于叶子结点,如求解w梯度中,需要除了常数1之外,还需要x与w,而w和x恰恰是叶子结点)
(之所以设置叶子结点主要是为了节省内存,因为在梯度反向传播结束之后,非叶子结点的梯度会被释放掉)
(代码中a,b,y的梯度情况,见程序结果图,含有x,w,a,b,y是否为叶子结点及它们的梯度分别是多少)
若想保存非叶子结点梯度须使用<>.retain_grad()
- is_leaf:指示张量是否为叶子结点(是torch.Tensor()的一个属性参数)
grad_ fn:记录创建该张量时所用的方法(函数) (是torch.Tensor()的一个属性参数)
y.grad _ fn = < MulBackward0> y是a与b相乘得到的
a.grad _ fn = < AddBackward0>
b.grad_ fn = < AddBackward0>
代码实现:
import torch
# 创建w,x
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x) # retain_grad()
# a.retain_grad() # 保存非叶子结点梯度 a
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad)
# 查看叶子结点
print("is_leaf:\n", w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)
# 查看梯度
print("gradient:\n", w.grad, x.grad, a.grad, b.grad, y.grad)
# 查看 grad_fn
print("grad_fn:\n", w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn)
结果:

二、PyTorch的动态图机制
pytorch采用的是动态图机制,TensorFlow采用静态图机制。
在计算图中,根据搭建方式的不同,可将计算图分为动态和静态。动态图是运算与搭建同时进行,静态图是先搭建图后运算。动态图特点为灵活、易调节,静态图特点为高效、不灵活。
两个实例:
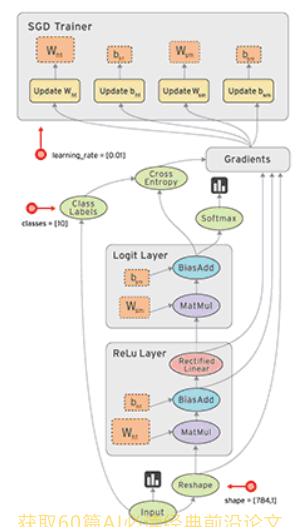
以TensorFlow为例,静态图首先需要搭建计算图,图中椭圆形以及矩形是结点,黑色箭头是边,就是数据要流向的方向,现在,图搭建完成,但是它是没有数据的,当图搭建完成后将数据放进input里,即可以执行运算。这些数据通常是tensor,这些tensor在图中流动,这也就是TensorFlow命名由来。缺点是,tensor存入后,就不能改变tensor流动方向了。
而在pytorch中,首先创建原始数据,也就是tensor,创建四个tensor,之后执行第一个乘法操作,在计算图中搭建乘法操作,产生h2h新张量,然后,再执行另外一个乘法操作,在计算图中搭建乘法操作,接着执行加法操作,在计算图中搭建加法操作,接着执行一个激活函数,最后,计算一个Loss,有了Loss之后,我们执行一个backward()梯度反向传播,这个梯度就可以沿着我们刚刚根据运算过程中搭建的这一个计算图去传播我们的梯度。
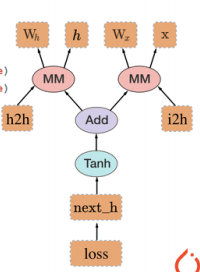
pytorch与TensorFlow不同,pytorch动态图搭建是根据每一步计算搭建的,而TensorFlow是先搭建所有的计算图,之后再把数据输入进去,这就是动态图与静态图的区别。
















 2157
2157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









