






大数据学习之scala(2)
2019.09.09
集合
容器类数据结构,支持声明式编程
<1> 序列:有先后次序的元素集合
<2> 数组:有索引的序列,类型相同,扁平的数据结构,是可变的数据结构(可以修改其中的数据元素),但是它的长度是固定的。

<3> 列表:线性的元素序列,类型是相同的,递归结构,不可对其进行修改。
方法:
- head方法:访问第一个元素
- tail方法:访问第一个元素后面的所有元素
- isEmpty方法:判断列表是否为空,为空会返回true
<4> 向量:结合列表、数组各自特性的类,可以进行索引访问和线性访问,支持快速修改和访问任意位置的元素。
<5> 集合:是一个无序的集合,其中每个元素都不相同,不能通过索引来访问。
方法:
- contains方法:若当前集合包含该元素,返回true
- isEmpty方法:如果当前集合为空,则返回true
<6> map:一个键值对集合,通过键找值,非常高效

集合类上的高阶方法
<1> map:参数是一个函数,作用于集合中的每一个元素,返回一个集合,返回个数和调用map的集合元素个数一致,类型却可能不一样。如果一个函数只有一个参数,包裹参数的列表可以用大括号代替:
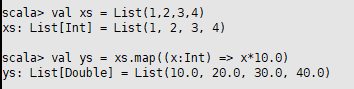
val ys = xs.map((x:Int) => x*10.0)
val ys = xs.map{(x:Int) => x*10.0}
//还可以改成以操作符的方式调用方法
val ys = xs map{(x:Int) => x*10.0}
//还可以省略参数类型
val ys = xs map{x => x*10.0}
//如果函数字面量的参数只在函数体内使用一次,右箭头及其左边部分都可以省略,可以只写函数字面量的主体
val ys = xs map{_*10.0}
//下划线表示集合中的元素,把它作为参数传递给map中的函数字面量

<2> flatMap:参数是一个函数,结果是一个扁平化的集合
toList方法:创建一个列表包含原有集合的所有元素

<3>filter:将谓词函数(返回一个布尔值的函数,要么为true,要么为false),作用于集合中的每一个元素,返回另一个集合,其中只包含计算结果为真的元素

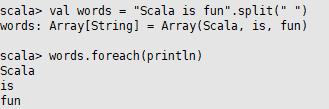
<4> foreach:参数是一个函数,作用于集合中的每一个元素,但是不返回任何东西,类似于map
<5> reduce:参数是一个函数,该函数有两个参数,将参数整合成一个值返回
应用:

- 求列表 +,-,*,/
- 求列表最大值、最小值
- 求字符串最大长度
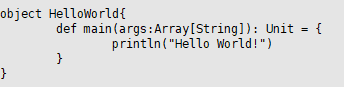
单独Scala应用程序
- 编译:scalac HelloWorld.scala
- 运行:scala HelloWorld















 2896
2896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









