







目录
实验任务一:计算级数
请用脚本的方式编程计算并输出下列级数的前 n 项之和 Sn,直到 Sn 刚好大于或等于 q 为止,其中 q 为大于 0 的整数,其值通过键盘输 入。
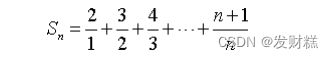
例如,若 q 的值为 50.0,则输出应为:Sn=50.416695。请将源文件 保存为 exercise2-1.scala,在 REPL 模式下测试运行,测试样例: q=1 时,Sn=2;q=30 时,Sn=30.891459;q=50 时,Sn=50.416695。
idea步骤分步:
// 导入输入输出库
import scala.io.StdIn._
// 导入输入输出库
import scala.io.StdIn._// 初始化 Sn 变量为 0
// 初始化 Sn 变量为 0
var Sn: Double = 0.0// 初始化 n 变量为 1
![]()
// 读取用户输入的 q 并赋值给变量 q
val q = StdIn.readInt()
// 读取用户输入的 q 并赋值给变量 q
println("请输入一个大于0的数q:")
val q = readDouble()// 当 Sn 小于 q 时执行循环
// 当 Sn 小于 q 时执行循环
while (Sn < q) {
}// Sn 的值加上(n+1)/n
// Sn 的值加上 (n+1)/n
Sn += (n + 1) / n.toDouble// n 自增 1
// n 自增 1
n += 1// 输出 Sn 的最终值
// 输出 Sn 的最终值
println(s"Sn=$Sn")完整代码:
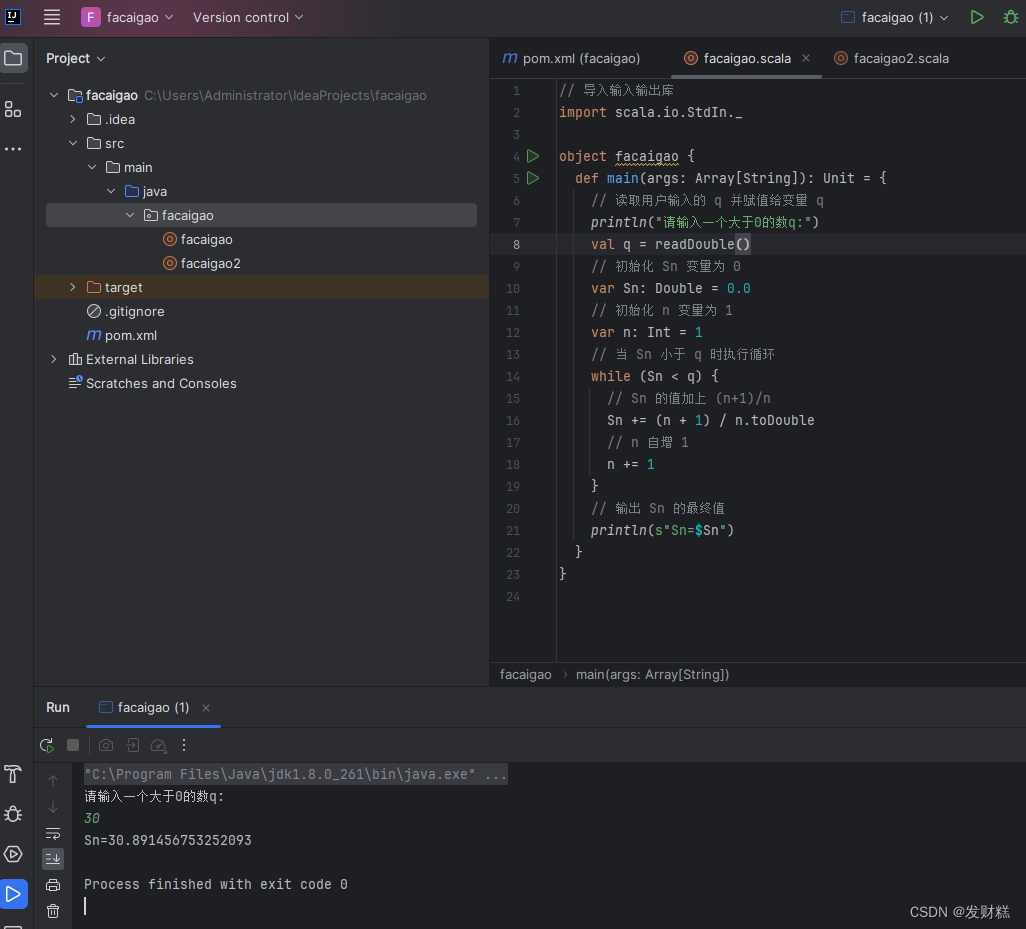
// 导入输入输出库
import scala.io.StdIn._
object facaigao {
def main(args: Array[String]): Unit = {
// 读取用户输入的 q 并赋值给变量 q
println("请输入一个大于0的数q:")
val q = readDouble()
// 初始化 Sn 变量为 0
var Sn: Double = 0.0
// 初始化 n 变量为 1
var n: Int = 1
// 当 Sn 小于 q 时执行循环
while (Sn < q) {
// Sn 的值加上 (n+1)/n
Sn += (n + 1) / n.toDouble
// n 自增 1
n += 1
}
// 输出 Sn 的最终值
println(s"Sn=$Sn")
}
}
linux步骤分布:
1、开启 scala 命令行:
[root@master ~]# su - hadoop
[hadoop@master 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











