







1. 各用户等级的不同得分表现占比
现有用户信息表user_info(uid用户ID,nick_name昵称, achievement成就值, level等级, job职业方向, register_time注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客1号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客2号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客3号♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客4号 | 25 | 0 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客555号 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 75 |
| 4 | 1001 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:11:01 | 60 |
| 5 | 1001 | 9003 | 2021-09-02 12:01:01 | 2021-09-02 12:41:01 | 90 |
| 6 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
| 7 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 8 | 1001 | 9004 | 2021-09-03 12:01:01 | (NULL) | (NULL) |
| 9 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 99 |
| 10 | 1002 | 9003 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
| 11 | 1002 | 9003 | 2020-02-02 12:11:01 | 2020-02-02 12:41:01 | 76 |
为了得到用户试卷作答的定性表现,我们将试卷得分按分界点[90,75,60]分为优良中差四个得分等级(分界点划分到左区间),请统计不同用户等级的人在完成过的试卷中各得分等级占比(结果保留3位小数),未完成过试卷的用户无需输出,结果按用户等级降序、占比降序排序。
由示例数据结果输出如下:
| level | score_grade | ratio |
|---|---|---|
| 3 | 良 | 0.667 |
| 3 | 优 | 0.333 |
| 0 | 良 | 0.500 |
| 0 | 中 | 0.167 |
| 0 | 优 | 0.167 |
| 0 | 差 | 0.167 |
解释:完成过试卷的用户有1001、1002;完成了的试卷对应的用户等级和分数等级如下:
| uid | exam_id | score | level | score_grade |
|---|---|---|---|---|
| 1001 | 9001 | 80 | 0 | 良 |
| 1001 | 9002 | 75 | 0 | 良 |
| 1001 | 9002 | 60 | 0 | 中 |
| 1001 | 9003 | 90 | 0 | 优 |
| 1001 | 9001 | 20 | 0 | 差 |
| 1001 | 9002 | 89 | 0 | 良 |
| 1002 | 9001 | 99 | 3 | 优 |
| 1002 | 9003 | 82 | 3 | 良 |
| 1002 | 9003 | 76 | 3 | 良 |
因此0级用户(只有1001)的各分数等级比例为:优1/6,良1/6,中1/6,差3/6;3级用户(只有1002)各分数等级比例为:优1/3,良2/3。结果保留3位小数。
示例1
drop table if exists user_info,exam_record;
CREATE TABLE user_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int UNIQUE NOT NULL COMMENT '用户ID',
`nick_name` varchar(64) COMMENT '昵称',
achievement int COMMENT '成就值',
level int COMMENT '用户等级',
job varchar(32) COMMENT '职业方向',
register_time datetime COMMENT '注册时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO user_info(uid,`nick_name`,achievement,level,job,register_time) VALUES
(1001, '牛客1', 19, 0, '算法', '2020-01-01 10:00:00'),
(1002, '牛客2号', 1200, 3, '算法', '2020-01-01 10:00:00'),
(1003, '牛客3号♂', 22, 0, '算法', '2020-01-01 10:00:00'),
(1004, '牛客4号', 25, 0, '算法', '2020-01-01 10:00:00'),
(1005, '牛客555号', 2000, 7, 'C++', '2020-01-01 10:00:00'),
(1006, '666666', 3000, 6, 'C++', '2020-01-01 10:00:00');
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2020-01-02 09:01:01', '2020-01-02 09:21:59', 80),
(1001, 9001, '2021-05-02 10:01:01', null, null),
(1001, 9002, '2021-02-02 19:01:01', '2021-02-02 19:30:01', 75),
(1001, 9002, '2021-09-01 12:01:01', '2021-09-01 12:11:01', 60),
(1001, 9003, '2021-09-02 12:01:01', '2021-09-02 12:41:01', 90),
(1001, 9001, '2021-06-02 19:01:01', '2021-06-02 19:32:00', 20),
(1001, 9002, '2021-09-05 19:01:01', '2021-09-05 19:40:01', 89),
(1001, 9004, '2021-09-03 12:01:01', null, null),
(1002, 9001, '2020-01-01 12:01:01', '2020-01-01 12:31:01', 99),
(1002, 9003, '2020-02-01 12:01:01', '2020-02-01 12:31:01', 82),
(1002, 9003, '2020-02-02 12:11:01', '2020-02-02 12:41:01', 76);
输出
3|良|0.667
3|优|0.333
0|良|0.500
0|中|0.167
0|优|0.167
0|差|0.167
思路
1.统计每次试卷完成记录的分数、等级、得分等级和该用户等级总人数:
2.内连接试卷作答表和用户信息表:exam_record JOIN user_info USING(uid)
3.筛选已完成作答的记录:WHERE submit_time IS NOT NULL
4.生成得分等级:CASE WHEN score >= 90 THEN '优' ... END AS score_grade
5.统计该用户等级总人数,拼接到每条记录:
COUNT(score) over(PARTITION BY level) AS level_cnt
6.按用户等级、得分等级分组:GROUP BY level, score_grade
7.计算每个得分等级占比:COUNT(score_grade) / level_cnt AS ratio
题解
select
`level`,
score_grade,
round(count(score_grade)/level_count,3) ratio
from
(
select uid,exam_id,score,`level`,
case
when score < 60 then '差'
when score < 75 then '中'
when score <90 then '良'
else '优'
end
score_grade,
count(*)over(partition by `level` ) level_count
from user_info
inner join exam_record
using(uid)
where submit_time is not null
)t
group by `level`,score_grade
order by `level` desc,ratio desc
2. 注册当天就完成了试卷的名单第三页
现有用户信息表user_info(uid用户ID,nick_name昵称, achievement成就值, level等级, job职业方向, register_time注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客1 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客2号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客3号♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客4号 | 25 | 0 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客555号 | 4000 | 7 | 算法 | 2020-01-11 10:00:00 |
| 6 | 1006 | 牛客6号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 7 | 1007 | 牛客7号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 8 | 1008 | 牛客8号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 9 | 1009 | 牛客9号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 10 | 1010 | 牛客10号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 11 | 1011 | 666666 | 3000 | 6 | C++ | 2020-01-02 10:00:00 |
试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | 算法 | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | 算法 | hard | 80 | 2020-01-01 10:00:00 |
| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
| 3 | 1002 | 9002 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
| 4 | 1003 | 9002 | 2020-01-01 19:01:01 | 2020-01-01 19:30:01 | 75 |
| 5 | 1004 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:11:01 | 60 |
| 6 | 1005 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:41:01 | 90 |
| 7 | 1006 | 9001 | 2020-01-02 19:01:01 | 2020-01-02 19:32:00 | 20 |
| 8 | 1007 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
| 9 | 1008 | 9003 | 2020-01-02 12:01:01 | 2020-01-02 12:20:01 | 99 |
| 10 | 1008 | 9001 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 98 |
| 11 | 1009 | 9002 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 82 |
| 12 | 1010 | 9002 | 2020-01-02 12:11:01 | 2020-01-02 12:41:01 | 76 |
| 13 | 1011 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
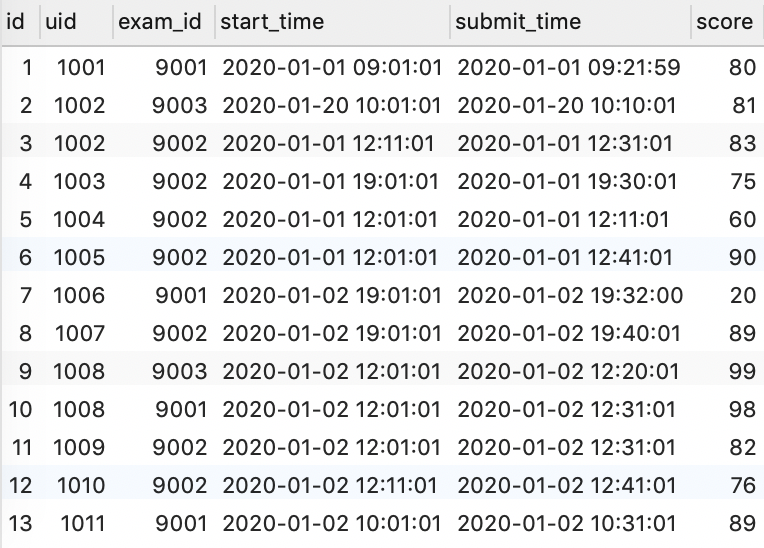
找到求职方向为算法工程师,且注册当天就完成了算法类试卷的人,按参加过的所有考试最高得分排名。排名榜很长,我们将采用分页展示,每页3条,现在需要你取出第3页(页码从1开始)的人的信息。
由示例数据结果输出如下:
| uid | level | register_time | max_score |
|---|---|---|---|
| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
解释:除了1011其他用户的求职方向都为算法工程师;算法类试卷有9001和9002,11个用户注册当天都完成了算法类试卷;计算他们的所有考试最大分时,只有1002和1008完成了两次考试,其他人只完成了一场考试,1002两场考试最高分为81,1008最高分为99。
按最高分排名如下:
| uid | level | register_time | max_score |
|---|---|---|---|
| 1008 | 0 | 2020-01-02 11:00:00 | 99 |
| 1005 | 7 | 2020-01-01 10:00:00 | 90 |
| 1007 | 0 | 2020-01-02 11:00:00 | 89 |
| 1002 | 3 | 2020-01-01 10:00:00 | 83 |
| 1009 | 0 | 2020-01-02 11:00:00 | 82 |
| 1001 | 0 | 2020-01-01 10:00:00 | 80 |
| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
| 1006 | 0 | 2020-01-02 11:00:00 | 20 |
每页3条,第三页也就是第7~9条,返回1010、1003、1004的行记录即可。
示例1
drop table if exists examination_info,user_info,exam_record;
CREATE TABLE examination_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
exam_id int UNIQUE NOT NULL COMMENT '试卷ID',
tag varchar(32) COMMENT '类别标签',
difficulty varchar(8) COMMENT '难度',
duration int NOT NULL COMMENT '时长',
release_time datetime COMMENT '发布时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE TABLE user_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int UNIQUE NOT NULL COMMENT '用户ID',
`nick_name` varchar(64) COMMENT '昵称',
achievement int COMMENT '成就值',
level int COMMENT '用户等级',
job varchar(32) COMMENT '职业方向',
register_time datetime COMMENT '注册时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO user_info(uid,`nick_name`,achievement,`level`,job,register_time) VALUES
(1001, '牛客1', 19, 0, '算法', '2020-01-01 10:00:00'),
(1002, '牛客2号', 1200, 3, '算法', '2020-01-01 10:00:00'),
(1003, '牛客3号♂', 22, 0, '算法', '2020-01-01 10:00:00'),
(1004, '牛客4号', 25, 0, '算法', '2020-01-01 11:00:00'),
(1005, '牛客555号', 4000, 7, '算法', '2020-01-01 10:00:00'),
(1006, '牛客6号', 25, 0, '算法', '2020-01-02 11:00:00'),
(1007, '牛客7号', 25, 0, '算法', '2020-01-02 11:00:00'),
(1008, '牛客8号', 25, 0, '算法', '2020-01-02 11:00:00'),
(1009, '牛客9号', 25, 0, '算法', '2020-01-02 11:00:00'),
(1010, '牛客10号', 25, 0, '算法', '2020-01-02 11:00:00'),
(1011, '666666', 3000, 6, 'C++', '2020-01-02 10:00:00');
INSERT INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES
(9001, '算法', 'hard', 60, '2020-01-01 10:00:00'),
(9002, '算法', 'hard', 80, '2020-01-01 10:00:00'),
(9003, 'SQL', 'medium', 70, '2020-01-01 10:00:00');
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2020-01-01 09:01:01', '2020-01-01 09:21:59', 80),
(1002, 9003, '2020-01-20 10:01:01', '2020-01-20 10:10:01', 81),
(1002, 9002, '2020-01-01 12:11:01', '2020-01-01 12:31:01', 83),
(1003, 9002, '2020-01-01 19:01:01', '2020-01-01 19:30:01', 75),
(1004, 9002, '2020-01-01 12:01:01', '2020-01-01 12:11:01', 60),
(1005, 9002, '2020-01-01 12:01:01', '2020-01-01 12:41:01', 90),
(1006, 9001, '2020-01-02 19:01:01', '2020-01-02 19:32:00', 20),
(1007, 9002, '2020-01-02 19:01:01', '2020-01-02 19:40:01', 89),
(1008, 9003, '2020-01-02 12:01:01', '2020-01-02 12:20:01', 99),
(1008, 9001, '2020-01-02 12:01:01', '2020-01-02 12:31:01', 98),
(1009, 9002, '2020-01-02 12:01:01', '2020-01-02 12:31:01', 82),
(1010, 9002, '2020-01-02 12:11:01', '2020-01-02 12:41:01', 76),
(1011, 9001, '2020-01-02 10:01:01', '2020-01-02 10:31:01', 89);
输出
1010|0|2020-01-02 11:00:00|76
1003|0|2020-01-01 10:00:00|75
1004|0|2020-01-01 11:00:00|60
思路
1.内连接用户信息表和试卷作答表:
user_info JOIN exam_record USING(uid)
2.继续内连接试卷信息表:JOIN examination_info USING(exam_id)
3.继续内连接每个人的最高分表:
按用户分组,计算分数的max:MAX(score) AS max_score;GROUP BY uid
4.筛选满足条件的记录:
求职方向为算法工程师:WHERE job = '算法'
算法类试卷:tag = '算法'
5.注册当天完成的试卷:DATE(register_time)=DATE(submit_time)
6.选取第三页的3条,即偏移/跳过前6条,取三条:LIMIT 6,3
题解
select
distinct users.uid,
`level`,
register_time,
max(score)over(partition by users.uid order by score desc) max_score
from examination_info info
left join exam_record record
on info.exam_id=record.exam_id
left join user_info users
on users.uid=record.uid
where
job="算法" AND tag = '算法'
and date(users.register_time)=date(record.submit_time)
order by max_score desc
limit 6,3
3. 对过长的昵称截取处理
现有用户信息表user_info(uid用户ID,nick_name昵称, achievement成就值, level等级, job职业方向, register_time注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客1 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客2号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客3号♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客4号 | 25 | 0 | 算法 | 2020-01-01 11:00:00 |
| 5 | 1005 | 牛客5678901234号 | 4000 | 7 | 算法 | 2020-01-11 10:00:00 |
| 6 | 1006 | 牛客67890123456789号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
有的用户的昵称特别长,在一些展示场景会导致样式混乱,因此需要将特别长的昵称转换一下再输出,请输出字符数大于10的用户信息,对于字符数大于13的用户输出前10个字符然后加上三个点号:『…』。
由示例数据结果输出如下:
| uid | nick_name |
|---|---|
| 1005 | 牛客5678901234号 |
| 1006 | 牛客67890123… |
解释:字符数大于10的用户有1005和1006,长度分别为13、17;因此需要对1006的昵称截断输出。
示例1
drop table if exists user_info;
CREATE TABLE user_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int UNIQUE NOT NULL COMMENT '用户ID',
`nick_name` varchar(64) COMMENT '昵称',
achievement int COMMENT '成就值',
level int COMMENT '用户等级',
job varchar(32) COMMENT '职业方向',
register_time datetime COMMENT '注册时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO user_info(uid,`nick_name`,achievement,`level`,job,register_time) VALUES
(1001, '牛客1', 19, 0, '算法', '2020-01-01 10:00:00'),
(1002, '牛客2号', 1200, 3, '算法', '2020-01-01 10:00:00'),
(1003, '牛客3号♂', 22, 0, '算法', '2020-01-01 10:00:00'),
(1004, '牛客4号', 25, 0, '算法', '2020-01-01 11:00:00'),
(1005, '牛客5678901234号', 4000, 7, '算法', '2020-01-01 10:00:00'),
(1006, '牛客67890123456789号', 25, 0, '算法', '2020-01-02 11:00:00');
输出:
1005|牛客5678901234号
1006|牛客67890123…
题解
select
uid,
if(char_length(nick_name)>13,concat(substr(nick_name,1,10),"..."),nick_name) nick_name
from user_info
where char_length(nick_name)>10
4. 大小写混乱时的筛选统计
现有试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | 算法 | hard | 60 | 2021-01-01 10:00:00 |
| 2 | 9002 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 3 | 9003 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 4 | 9004 | sql | medium | 70 | 2021-01-01 10:00:00 |
| 5 | 9005 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 6 | 9006 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 7 | 9007 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 8 | 9008 | SQL | medium | 70 | 2021-01-01 10:00:00 |
| 9 | 9009 | SQL | medium | 70 | 2021-01-01 10:00:00 |
| 10 | 9010 | SQL | medium | 70 | 2021-01-01 10:00:00 |
试卷作答信息表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 80 |
| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
| 3 | 1002 | 9002 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
| 4 | 1003 | 9002 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
| 5 | 1004 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
| 6 | 1005 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
| 7 | 1006 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 20 |
| 8 | 1007 | 9003 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
| 9 | 1008 | 9004 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
| 10 | 1008 | 9001 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 98 |
| 11 | 1009 | 9002 | 2020-02-02 12:01:01 | 2020-01-02 12:43:01 | 81 |
| 12 | 1010 | 9001 | 2020-01-02 12:11:01 | (NULL) | (NULL) |
| 13 | 1010 | 9001 | 2020-02-02 12:01:01 | 2020-01-02 10:31:01 | 89 |
试卷的类别tag可能出现大小写混乱的情况,请先筛选出试卷作答数小于3的类别tag,统计将其转换为大写后对应的原本试卷作答数。
如果转换后tag并没有发生变化,不输出该条结果。
由示例数据结果输出如下:
| tag | answer_cnt |
|---|---|
| C++ | 6 |
解释:被作答过的试卷有9001、9002、9003、9004,他们的tag和被作答次数如下:
| exam_id | tag | answer_cnt |
|---|---|---|
| 9001 | 算法 | 4 |
| 9002 | C++ | 6 |
| 9003 | c++ | 2 |
| 9004 | sql | 2 |
作答次数小于3的tag有c++和sql,而转为大写后只有C++本来就有作答数,于是输出c++转化大写后的作答次数为6。
示例1
drop table if exists examination_info,exam_record;
CREATE TABLE examination_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
exam_id int UNIQUE NOT NULL COMMENT '试卷ID',
tag varchar(32) COMMENT '类别标签',
difficulty varchar(8) COMMENT '难度',
duration int NOT NULL COMMENT '时长',
release_time datetime COMMENT '发布时间'
)CHARACTER SET utf8 COLLATE utf8_bin;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES
(9001, '算法', 'hard', 60, '2020-01-01 10:00:00'),
(9002, 'C++', 'hard', 80, '2020-01-01 10:00:00'),
(9003, 'c++', 'hard', 80, '2020-01-01 10:00:00'),
(9004, 'sql', 'medium', 70, '2020-01-01 10:00:00'),
(9005, 'C++', 'hard', 80, '2020-01-01 10:00:00'),
(9006, 'C++', 'hard', 80, '2020-01-01 10:00:00'),
(9007, 'C++', 'hard', 80, '2020-01-01 10:00:00'),
(9008, 'SQL', 'medium', 70, '2020-01-01 10:00:00'),
(9009, 'SQL', 'medium', 70, '2020-01-01 10:00:00'),
(9010, 'SQL', 'medium', 70, '2020-01-01 10:00:00');
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2020-01-01 09:01:01', '2020-01-01 09:21:59', 80),
(1002, 9003, '2020-01-20 10:01:01', '2020-01-20 10:10:01', 81),
(1002, 9002, '2020-01-01 12:11:01', '2020-01-01 12:31:01', 83),
(1003, 9002, '2020-01-01 19:01:01', '2020-01-01 19:30:01', 75),
(1004, 9002, '2020-01-01 12:01:01', '2020-01-01 12:11:01', 60),
(1005, 9002, '2020-01-01 12:01:01', '2020-01-01 12:41:01', 90),
(1006, 9001, '2020-01-02 19:01:01', '2020-01-02 19:32:00', 20),
(1007, 9003, '2020-01-02 19:01:01', '2020-01-02 19:40:01', 89),
(1008, 9004, '2020-01-02 12:01:01', '2020-01-02 12:20:01', 99),
(1008, 9001, '2020-01-02 12:01:01', '2020-01-02 12:31:01', 98),
(1009, 9002, '2020-01-02 12:01:01', '2020-01-02 12:43:01', 81),
(1010, 9002, '2020-01-02 12:11:01', null, null),
(1011, 9001, '2020-01-02 10:01:01', '2020-01-02 10:31:01', 89);
输出
c++|6
题解
方式一:
WITH t_tag_count as (
SELECT tag, COUNT(uid) as answer_cnt
FROM exam_record
LEFT JOIN examination_info USING(exam_id)
GROUP BY tag
)
SELECT a.tag, b.answer_cnt
FROM t_tag_count as a
JOIN t_tag_count as b
ON UPPER(a.tag) = b.tag and a.tag != b.tag and a.answer_cnt < 3;
方式二:
select t1.tag, t2.answer_cnt answer_cnt
from
(
select tag,count(start_time) answer_cnt
from examination_info
inner join exam_record
using(exam_id)
group by tag
)t1
join
(
select tag,count(start_time) answer_cnt
from examination_info
inner join exam_record
using(exam_id)
group by tag
)t2
on t1.tag !=t2.tag
and upper(t1.tag) = t2.tag
and t1.answer_cnt < 3
拓展
lower(expr)参数说明:大写转成小写
upper(expr)参数说明:小写待转成大写的源串
返回值:字符串型
示例:
例1:upper(“ABCdef”)返回:“ABCDEF”
例2:lower(“AAA”)返回:“aaa”















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









