







Apriori算法理解与介绍
一.基本概念
1.基于先验原理的剪枝
先验原理:如果一个项集是频繁的,则它的所有子集一定也是频繁的。相反,如果一个项集是非频繁的,则他的所有超集也是非频繁的。
先验原理的理解也很简单,将支持度的公式列出来,我们可以发现,项集的支持度不会小于它的超集。
基于这个原理,如果项集{x,y}是非频繁的,则我们不用去判断{x,y,z},因为肯定是非频繁的。这就是基于支持度的剪枝。可以不用去判别所有的项集,因为有一部分项集是否频繁是可以基于它的子集推出来的。
2.候选项集的产生
最开始将每个项集都看作是候选项集,再通过计算得到第一批频繁项集。
通过合并上一轮产生的频繁(k-1)项集,只有当它们的前k-2项都相同时,才合并生成k项集。
例如对于{a,b},{a,c},{b,d}这三个项集,最开始,我们将生成第一批1-项集 {a},{b},{c},{d},再通过两个相同的1-项集产生2-项集 即生成了{a,b},{a,c},{a,d},{b,c},{b,d},{c,d}。再通过两个2-项集生成3-项集,{a,b,c},{a,b,d},{a,c,d},{b,c,d}以此类推…
注意{a,b,c}是由{a,b}和{a,c}合成的,而不是有{a,b}和{b,c}合成的,因为{a,b}和{b,c}的第一项不同,一个为a,一个为b,所以不能合并。
3.支持度计数(hash树)
4.规则产生
规则的产生是基于上面3点之后,产生了候选项集,再从这些候选项集中产生规则,最后筛选出置信度高的规则。
注意这里计算置信度时并不需要再次扫描数据集,因为置信度公式为: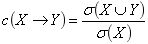 这里分子分母都是在前面产生频繁项集时就计算过了。
这里分子分母都是在前面产生频繁项集时就计算过了。
二.Apriori算法的过程介绍
主要由两大部分组成,第一部分是找出频繁项集,第二部分是找出强规则。
1.找出频繁项集
通过合并频繁(k-1)-项集产生k-项集,再通过剪枝原理,从这批k-项集中筛选出一批项集(以此来减少后面hash计数的计算量),从筛选出的k-项集进行hash计数,找出频繁k-项集。再合并频繁k-项集生成(k+1)项集…以此类推。
2.找出强规则
从上一步产生的频繁项集中,组合成规则,从中找出强规则。
三.Apriori算法的实例
接下来用一个例子用apriori算法来走一遍关联规则的流程(本例子预定义的支持度为2),下图是事物数据,9个顾客分别买了不同的商品列表(我们假定I1表示泡面,I2表示矿泉水,I3表示牛栏山,I4表示雪碧,I5表示火腿)。
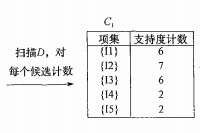
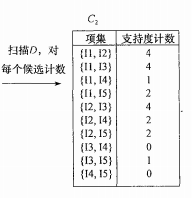
首先我们要做的是第一次迭代,扫描所有的事物,对每个项进行计数得到候选项集,得到如下图所示的结果,记为C1。
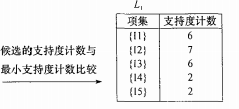
此时,我们要对支持度计数和支持度的阈值进行比较,剔除小于支持度阈值的项集,显而易见,在本例中C1的项集都达到了阈值。我们便可以得出频繁1项集记作L1
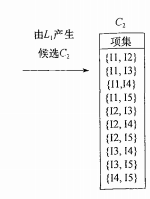
接下来我们要进行第二次迭代,目的是得出频繁2项集,所以要使用连接来产生候选项集2项集。L1L1 得出
连接这一步,我们把它叫做连接步,连接得到C2后,接下来做的是剪枝步,就是剪掉项集中包含不频繁项的项集,在本例中1项集全部都是频繁项集,例如{I1,I2}中没有不频繁项集,此项集不剪,{I1,I3}中没有不频繁项集,同理不剪,以此类推。所以C2中所有的项集都不需要剪掉。到此连接步、剪枝步全部完成。(这里值得注意的是剪枝是必须的一步,不能省略)最后再计一下数得出最终的C2。如下图所示。
将支持度计数小于阈值2的全部剔除,得出频繁2项集L2,如下图所示。
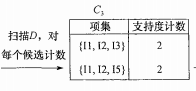
现在开始进行第三次迭代,L2L2 得出候选项集C3,如下图所示。
在这一步同样是经过了连接步和剪枝步。L2自连接得到
然而除了之外。
中都含有不频繁项集,第一个{I3,I5}不是L2的元素所以要剪枝,后面以此类推,最终得到上图的C3。(再重视一下,这个剪枝不能省略)。最后记一下数,得出最终的候选项集C3。
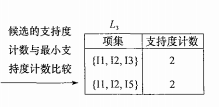
得到候选项集C3后与支持度阈值比较,得出频繁3项集L3。
现在继续第四次迭代,L3 自连接得到 {I1,I2,I3,I5}
,接下来剪枝,因为这个项集中{I2,I3,I5}不属于L3,所以剪掉,C4为空了,所以算法到此结束,现在得出了所有的频繁项集。到此为止,我们做完了第一步:找出所有的频繁项集。接下来要做的便是输出强关联规则。
现在我们拿X =
{I1,I2,I5}为例,输出关联规则。X的非空子集为{I1,I2}、{I1,I5}、{I2,I5}、{I1}、{I2}、{I5}。所以组合一下关联规则如下:
置信度我们根据上文提到的公式来算,拿第一个{I1,I2} => I5为例。confidence = P(I5 | {I1,I2})
通过查找L3,{I1,I2,I5}的支持度计数为2,通过查L2,{I1,I2}的支持度计数为4。即最终可以计算出confidence =
= 50%。剩下的以此类推,假定我们预定义70%的置信度。在这些规则中,我们可以输出强关联规则的只有三个。即三个100%置信度的规则。那么我们可以得到买泡面和火腿的一定会买矿泉水,买矿泉水和火腿的一定会买泡面,买火腿的一定会买泡面和矿泉水这三个关联规则。




PS:本文第三部分Apriori算法的实例来自文章:https://blog.csdn.net/huihuisd/article/details/86489810
参考书籍:数据挖掘导论















 4275
4275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









