







1. 关联规则简介
Apriori 算法是最为经典的 关联规则挖掘算法 之一。
相关算法介绍参考博客:Apriori算法
1.1 什么是关联规则 ?
关于关联规则有个很常见的例子:啤酒与尿布。沃尔玛在分析销售记录时,发现啤酒和尿布经常一起被购买,于是他们调整了货架,把两者放在一起,结果真的提升了啤酒的销量。
关联规则分析也称为购物篮分析,最早是为了发现超市销售数据库中不同的商品之间的关联关系。关联规则是反映一个事物与其他事物之间的关联性,若多个事物之间存在着某种关联关系,那么其中的一个事物就能通过其他事物预测到。
这里要注意,关联规则不是因果关系,有可能有因果关系,有可能没有。
2. 基本定义
定义 1 :两个不相交的非空集合 X , Y X, Y X,Y ,如果有 X → Y X →Y X→Y ,就说 X → Y X →Y X→Y 是一条关联规则。如吃咸菜的人偏爱喝粥( 咸菜->粥)就是一条关联规则。
关联规则的强度(可信度)用 支持度(support) 和 自信度(confidence) 来描述。
定义 2 :项集
X
,
Y
X, Y
X,Y 同时发生的概率称为关联规则
X
→
Y
X →Y
X→Y 的支持度(support):
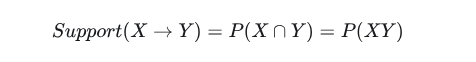
最小支持度是用户或专家定义的用来衡量支持度的一个阈值,表示关联规则具有统计学意义的最低重要性。具有“统计学意义”的显著特征就是这个事件发生的概率/频率不能太低(否则就不具有推广到其他个体的价值)。
由于现实生活中,常用古典概型估计概率,因此,上式也可写为:
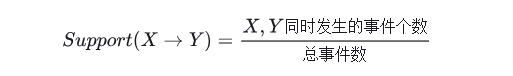
定义 3 :项集
X
X
X 发生的前提下,项集
Y
Y
Y 发生的概率称为关联规则
x
→
Y
x →Y
x→Y 的自信度(confidence 条件概率):
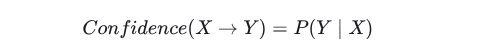
最小置信度是用户或专家定义的用来衡量置信度的一个阈值,表示关联规则的最低可靠性。同理,在古典概型中,上式也可以写为:
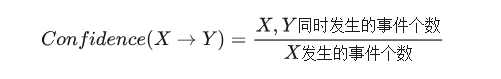
3. 算法步骤
Apriori 算法是最经典也是最常用的挖掘频繁项集的算法,其核心思想是通过连接产生候选项及其支持度,然后通过剪枝生成频繁项集。
Apriori算法主要包含两个步骤:
1. 生成频繁项集
这一阶段找出所有满足 最小支持度的项集(具有统计学意义的组合),找出的这些项集称为频繁项集。自信度与支持度的计算涉及到多个列表的循环,极大影响频繁项集的生成时间。
2. 生成关联规则
在上一步产生的频繁项集的基础上生成满足最小自信度的规则,产生的规则称为强规则。
这里涉及两个重要的定理:
1. 如果一个集合是频繁项集,则它的所有子集都是频繁项集。 假设一个集合{A,B}是频繁项集,则它的子集{A}, {B} 都是频繁项集。
2. 如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。 假设集合{A}不是频繁项集,则它的任何超集如{A,B},{A,B,C}必定也不是频繁项集。
根据定理1和定理2易知:若
X
→
Y
X →Y
X→Y 是强规则,则
X
,
Y
,
X
Y
X, Y, XY
X,Y,XY 都必须是频繁项集。

4. Python3实现
使用的编程语言:python3.6.4 (Anaconda3)
使用的编辑器:pycharm
使用的模块:pandas、itertools(标准库模块)
# !/usr/bin/env python
# -*- coding:utf-8 -*-
# version: Python 3.6.4 on win64
# author: Suranyi time: 8/6
# title: Apriori算法
import os,itertools
import numpy as np
import pandas as pd
class Apriori(object):
def __init__(self, itemSets, minSupport=0.5, minConf=0.7, sort = False):
self.itemSets = itemSets
self.minSupport = minSupport
self.minConf = minConf
self.sort = sort
self.__Initialize()
def __Initialize(self):
self.__item()
self.__creat_matrix()
self.update(minSupport=self.minSupport, minConf=self.minConf)
def __item(self):
'''获取项目元素列表'''
self.item = []
for itemSet in self.itemSets:
for item in itemSet:
if item not in self.item:
self.item.append(item)
self.item.sort()
def __creat_matrix(self):
'''将项集转为pandas.DataFrame数据类型'''
self.data = pd.DataFrame(columns=self.item)
for i in range(len(self.itemSets)):
self.data.loc[i, self.itemSets[i]] = 1
def __candidate_itemsets_l1(self):
'''创建单项频繁项集及L1'''
self.L1 = self.data.loc[:, self.data.sum(axis=0) / len(self.itemSets) >= self.minSupport]
self.L1_support_selects = dict(self.L1.sum(axis=0) / len(self.itemSets)) # 只作为分母,不进行拆分
def __candidate_itemsets_lk(self):
'''根据L1创建多项频繁项集Lk,非频繁项集的任何超集都不是频繁项集'''
last_support_selects = self.L1_support_selects.copy() # 初始化
while last_support_selects:
new_support_selects = {}
for last_support_select in last_support_selects.keys():
for L1_support_name in set(self.L1.columns) - set(last_support_select.split(',')):
columns = sorted([L1_support_name] + last_support_select.split(',')) # 新的列名:合并后排序
count = (self.L1.loc[:, columns].sum(axis=1) == len(columns)).sum()
if count / len(self.itemSets) >= self.minSupport:
new_support_selects[','.join(columns)] = count / len(self.itemSets)
self.support_selects.update(new_support_selects)
last_support_selects = new_support_selects.copy() # 作为新的 Lk,进行下一轮更新
def __support_selects(self):
'''支持度选择'''
self.__candidate_itemsets_l1()
self.__candidate_itemsets_lk()
self.item_Conf = self.L1_support_selects.copy()
self.item_Conf.update(self.support_selects)
def __confidence_selects(self):
'''生成关联规则,其中support_selects已经按照长度大小排列'''
for groups, Supp_groups in self.support_selects.items():
groups_list = groups.split(',')
for recommend_len in range(1, len(groups_list)):
for recommend in itertools.combinations(groups_list, recommend_len):
items = ','.join(sorted(set(groups_list) - set(recommend)))
Conf = Supp_groups / self.item_Conf[items]
if Conf >= self.minConf:
self.confidence_select.setdefault(items, {})
self.confidence_select[items].setdefault(','.join(recommend),{'Support': Supp_groups, 'Confidence': Conf})
def show(self,**kwargs):
'''可视化输出'''
if kwargs.get('data'):
select = kwargs['data']
else:
select = self.confidence_select
items = []
value = []
for ks, vs in select.items():
items.extend(list(zip([ks] * vs.__len__(), vs.keys())))
for v in vs.values():
value.append([v['Support'], v['Confidence']])
index = pd.MultiIndex.from_tuples(items, names=['Items', 'Recommend'])
self.rules = pd.DataFrame(value, index=index, columns=['Support', 'Confidence'])
if self.sort or kwargs.get('sort'):
result = self.rules.sort_values(by=['Support', 'Confidence'], ascending=False)
else:
result = self.rules.copy()
return result
def update(self, **kwargs):
'''用于更新数据'''
if kwargs.get('minSupport'):
self.minSupport = kwargs['minSupport']
self.support_selects = {} # 用于储存满足支持度的频繁项集
self.__support_selects()
if kwargs.get('minConf'):
self.minConf = kwargs['minConf']
self.confidence_select = {} # 用于储存满足自信度的关联规则
self.__confidence_selects()
print(self.show())
if kwargs.get('file_name'):
file_name = kwargs['file_name']
if file_name.endswith(".xlsx"):
self.show().to_excel(f'{file_name}')
else:
self.show().to_excel(f'{file_name}.xlsx')
self.apriori_rules = self.rules.copy()
def __get_Recommend_list(self,itemSet):
'''输入数据,获取关联规则列表'''
self.recommend_selects = {}
itemSet = set(itemSet) & set(self.apriori_rules.index.levels[0])
if itemSet:
for start_str in itemSet:
for end_str in self.apriori_rules.loc[start_str].index:
start_list = start_str.split(',')
end_list = end_str.split(',')
self.__creat_Recommend_list(start_list, end_list, itemSet)
def __creat_Recommend_list(self,start_list,end_list,itemSet):
'''迭代创建关联规则列表'''
if set(end_list).issubset(itemSet):
start_str = ','.join(sorted(start_list+end_list))
if start_str in self.apriori_rules.index.levels[0]:
for end_str in self.apriori_rules.loc[start_str].index:
start_list = start_str.split(',')
end_list = end_str.split(',')
self.__creat_Recommend_list(sorted(start_list),end_list,itemSet)
elif not set(end_list) & itemSet:
start_str = ','.join(start_list)
end_str = ','.join(end_list)
self.recommend_selects.setdefault(start_str, {})
self.recommend_selects[start_str].setdefault(end_str, {'Support': self.apriori_rules.loc[(start_str, end_str), 'Support'], 'Confidence': self.apriori_rules.loc[(start_str, end_str), 'Confidence']})
def get_Recommend(self,itemSet,**kwargs):
'''获取加权关联规则'''
self.recommend = {}
self.__get_Recommend_list(itemSet)
self.show(data = self.recommend_selects)
items = self.rules.index.levels[0]
for item_str in items:
for recommends_str in self.rules.loc[item_str].index:
recommends_list = recommends_str.split(',')
for recommend_str in recommends_list:
self.recommend.setdefault(recommend_str,0)
self.recommend[recommend_str] += self.rules.loc[(item_str,recommends_str),'Support'] * self.rules.loc[(item_str,recommends_str),'Confidence'] * self.rules.loc[item_str,'Support'].mean()/(self.rules.loc[item_str,'Support'].sum()*len(recommends_list))
result = pd.Series(self.recommend,name='Weight').sort_values(ascending=False)
result.index.name = 'Recommend'
result = result/result.sum()
result = 1/(1+np.exp(-result))
print(result)
if kwargs.get('file_name'):
file_name = kwargs['file_name']
if file_name.endswith(".xlsx"):
excel_writer = pd.ExcelWriter(f'{file_name}')
else:
excel_writer = pd.ExcelWriter(f'{file_name}.xlsx')
result.to_excel(excel_writer,'推荐项目及权重')
self.rules.to_excel(excel_writer, '关联规则树状表')
self.show().to_excel(excel_writer, '总关联规则树状表')
self.show(sort = True).to_excel(excel_writer, '总关联规则排序表')
excel_writer.save()
return result
def str2itemsets(strings, split=','):
'''将字符串列表转化为对应的集合'''
itemsets = []
for string in strings:
itemsets.append(sorted(string.split(split)))
return itemsets
if __name__ == '__main__':
# 1.导入数据
data = pd.read_excel(r'apriori算法实现.xlsx', index=False)
# 2.关联规则中不考虑多次购买同一件物品,删除重复数据
data = data.drop_duplicates()
# 3.初始化列表
itemSets = []
# 3.按销售单分组,只有1件商品的没有意义,需要进行过滤
groups = data.groupby(by='销售单明细')
for group in groups:
if len(group[1]) >= 2:
itemSets.append(group[1]['商品编码'].tolist())
# 4.训练 Apriori
ap = Apriori(itemSets, minSupport=0.03, minConf=0.5)
ap.get_Recommend('2BYP206,2BYW001-,2BYW013,2BYX029'.split(','))
参考数据文件: apriori算法实现.xlsx,该数据为某药店销售单数据,已做脱敏处理。

















 3084
3084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









