







一.定义
Flink是一个分布式计算框架,可以处理海量数据,既可以离线批处理,也可以做实时流处理。主要是用于实时流处理。
flink实时流处理的优势可以归纳为三点:
①低延迟
②高吞吐
③支持精确一次

从上图,可以看出flink可以接受多种数据源数据,比如socket,file,Kafka数据源等,然后通过flink处理计算。此外,flink也支持和主流的资源调度框架的整合,比如k8s,yarn,mesos,使得对整个集群的资源调度更为合理。最后flink可以将结果存到其他的应用系统中,比如hbase,mysql,es等
二.flink的技术亮点
1.在目前所有的实时流计算框架中,flink是唯一一个同时支持低延迟、高吞吐、精确一次语义的实时流计算框架

2.flink既支持事件事件(Event Time),也支持处理时间(Process Time)之前的实时流计算框架都是基于Process Time来处理数据的。Process Time可以理解为:以数据到达计算框架被处理的时间戳为Process Time。
有些时候,可能由于网络波动、网络故障或其他的服务器故障导致实际发送的数据的顺序和实际到达的顺序不一样,导致最终结果不正确性。
Flink可以基于事件时间来进行处理


3.Flink支持状态编程
flink允许用户在实时流计算过程中,获取计算的中间状态,从而实现比较复杂的业务场景。
4.Flink支持精确一次语义
flink通过轻量级分布式快照机制,能够确保数据不丢失,并且能够精确处理
5.Flink实现了独立的内存管理机制
可以说Flink是一种内存计算框架,Flink实现了独立的内存管理机制,减少了JVMGC的依赖,从而降低了JVMGC可能带来的负面影响。
三.Flink-Source
1.CollectSource
2.FileSource
3.SocketSource
4.KafkaSource(下面讲解)
val env = StreamExecutionEnvironment.getExecutionEnvironment
//创建参数对象
val properties = new Properties()
//设置kafka的集群列表
properties.setProperty("bootstrap.servers","kafka01:9092,kafka02:9092,kafka03:9092")
//设置zookeeper集群列表
properties.setProperty("zookeeper.connect","zk1:2181,zk2:2181,zk3:2181")
//①参:消费的主题名 ②指定消费的数据类型,普通文本类型③属性参数对象
//flink-kafkasource的并行度和主题的分区数量有关,比如主题一个分区,则并行度为1
val consumer=new FlinkKafkaConsumer011[String]("topicsc",new SimpleStringSchema(),properties)
val source = env.addSource(consumer)
env.execute()
source.print()
四.Flink API
Flink的模块可以分为三个模块:
1.DataSource模块:用于指定flink的数据源,使得flink可以获取
2.Transformation模块(Flink API):用于定义flink对数据的处理逻辑。
3.DataSink模块。用于指定flink的输出目的地,使得flink可以将计算结果输出到其他的应用系统中
Flink API可以分为两类:
1.DataStream API,用于实时流处理的API
2.Data Set,用于离线处理的API
Flink既可以做离线处理,也可以做实时处理,但flink最擅长的就是实时流处理.。
实时系列:
①map,
②flatmap,
③filter,
④keyBy(将Stream指定key并根据key的散列值进行分区),
⑤reduce,
⑥Aggregations(是DataStream结构提供的聚合算子,根据指定的字段进行聚合操作,滚动地产生一系列数据聚合结果。其实是将Reduce算子中的函数进行了封装,封装的聚合操作有sum、min、max,这样就不需要用户自己定义Reduce函数。),
//数据源helle flink hello
//flink提供一些aggregations函数,比如sum,min,max,这些函数需要作用于keyedStream上
//keyedStream就是调用keyBy产生的
val result = source.flatMap(line=>line.split(" "))
.map(world=>(word,1))
.keyBy(0)//0表示元祖的下标0,本例中以单词key进行分组
//如不加入timeWindow实现对历史数据的累计处理
.timeWindow(Time.of(5,TimeUnit.SECONDS))//实现实时流单词频次统计-实现窗口操作。比如窗口=5s,类比于sparkStreaming的微批流处理形式
.reduce((a,b))//这个就相当于aggregations函数的sum
⑦union,
⑧split&select(func)
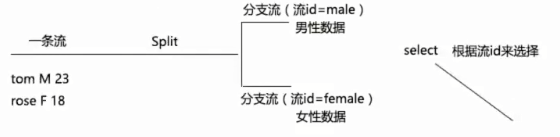
⑨connect
五.Flink的并发度(并行度)概念及设置使用
首先先明确Flink的Slot的概念

1.Slot槽位,初学时类比于Yarn中的Container容器概念。是对资源(内存+cpu核数)的一种限定和划分。
2.Slot是针对TaskManager而言的,默认情况下,每个TaskManager的Slot的数量=其CPU核数总和
3.Slot对应TaskManager的资源是均分策略
4.通过设置Flink的并行度,从而提高Flink的开发处理能力。可以认为Flink的并行度就是分区数。

//上图并行度代码
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度,不设置默认为1
env.setParallelism(2)
//从nc socket发送数据,数据源:如hello world hello
val source = env.socketTextStream("hadoop01",8888)
val result = source.flatMap(line=>line.split(" ")).map(word=>(word,1))
补充:如果在idea启动,默认并行度等于电脑核数
小结:可以将flink的并行度看做分区,并行度越高,分区数越多,则flink的并行效率越高


//上两张图并行度代码
val env = StreamExecutionEnvironment.getExecutionEnvironment
//从nc socket发送数据,数据源:如hello world hello
val source = env.socketTextStream("hadoop01",8888)
val result = source.flatMap(line=>line.split(" ")).setParallelism(2).map(word=>(word,1)).setParallelism(3)
result.print().setParallelism(1)
Flink的并行度设置分为4个层面,算子层面(代码算子后面中写),执行环境层面(env.setParallelism(2)),客户端层面(提交任务页面),系统层面(配置文件中配置)–优先级从前往后,算子优先级最高
六.Flink的窗口计算
Flink的窗口计算,指的是window操作,需要注意的是:窗口计算必须是基于KeyedStream来操作的,即必须在keyBy之后进行窗口计算,在一个窗口内针对同一个key的数据进行处理。
Flink的窗口计算分为:
1.滚动窗口:窗口之间数据没有重叠部分,比如设定窗口的大小=5s
2.滑动窗口:需要指定一个滑动区间以及窗口大小,每个一段时间计算一个窗口数据。即窗口与窗口之间存在重叠数据。比如窗口大小=10s,滑动区间=5s
3.计数窗口,当时间key的数量达到指定计数操作的时候时,触发后续计算:当相同key的数量达到指定计数操作时,触发后续计算

//统计五秒内的wordcount
val env = StreamExecutionEnvironment.getExecutionEnvironment
//从nc socket发送数据,数据源:如hello world hello
val source = env.socketTextStream("hadoop01",8888)
val wordcount = source.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
wordcount.print()
env.execute()
//每隔五秒统计10s窗口内的wordcount
val env = StreamExecutionEnvironment.getExecutionEnvironment
//从nc socket发送数据,数据源:如hello world hello
val source = env.socketTextStream("hadoop01",8888)
val wordcount = source.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.keyBy(0)
//①参:窗口大小②参:滑动区间大小
.timeWindow(Time.seconds(10),Time.seconds(5))
.sum(1)
wordcount.print( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2076
2076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









