







前言:此文章从客户端提交job任务开始,到对需要处理的数据进行切片,产生对应的maptask任务,Yarn来管理任务的调度来执行maptask和reducetask(包括shuffle)进行了详细的代码分析。
一、hadoop的Job 提交流程源码
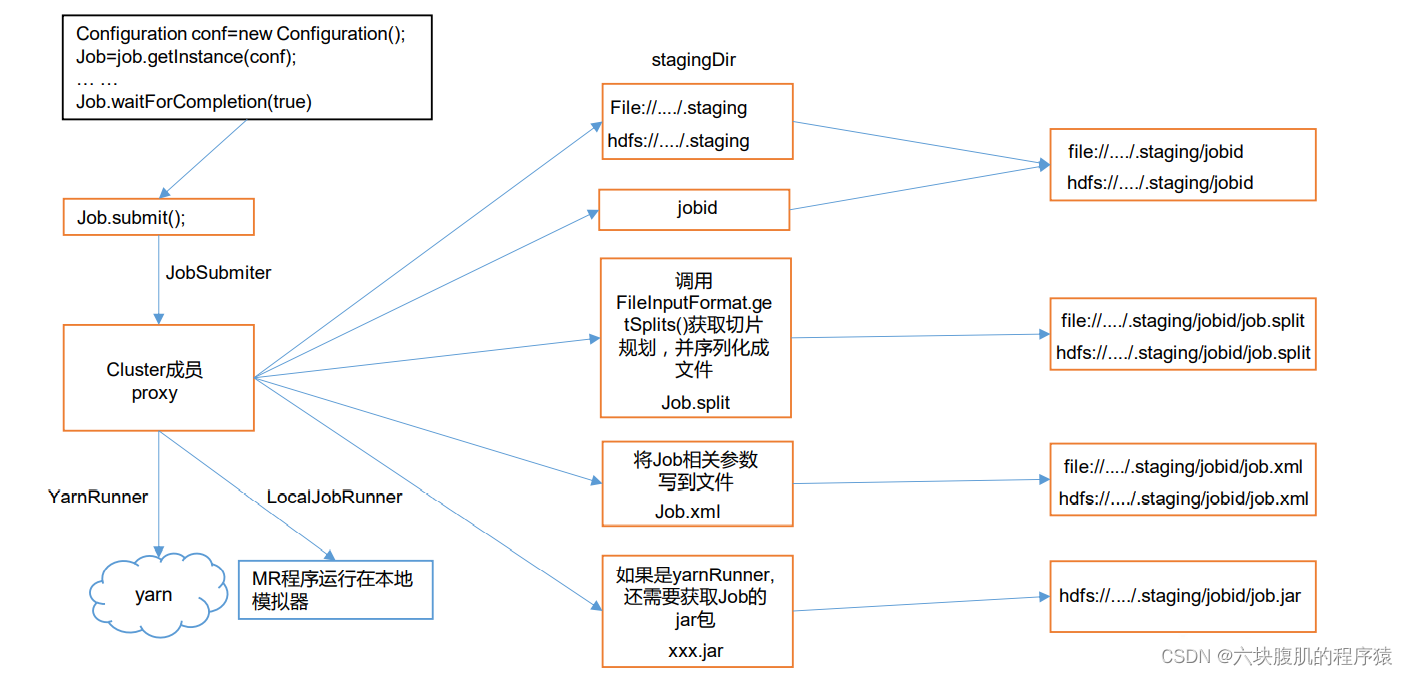
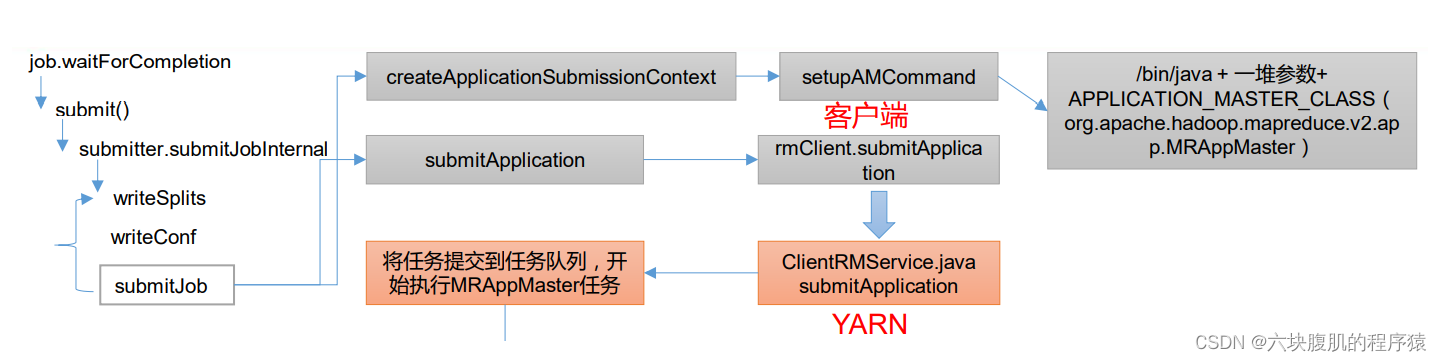
流程图:
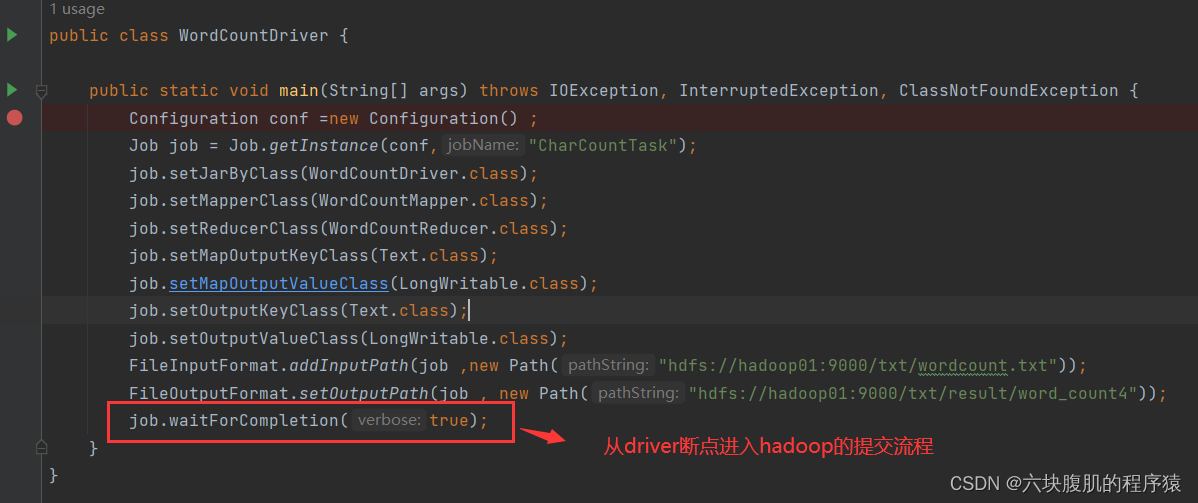
1.从我们编写的mapreduce的代码中进入job提交源码
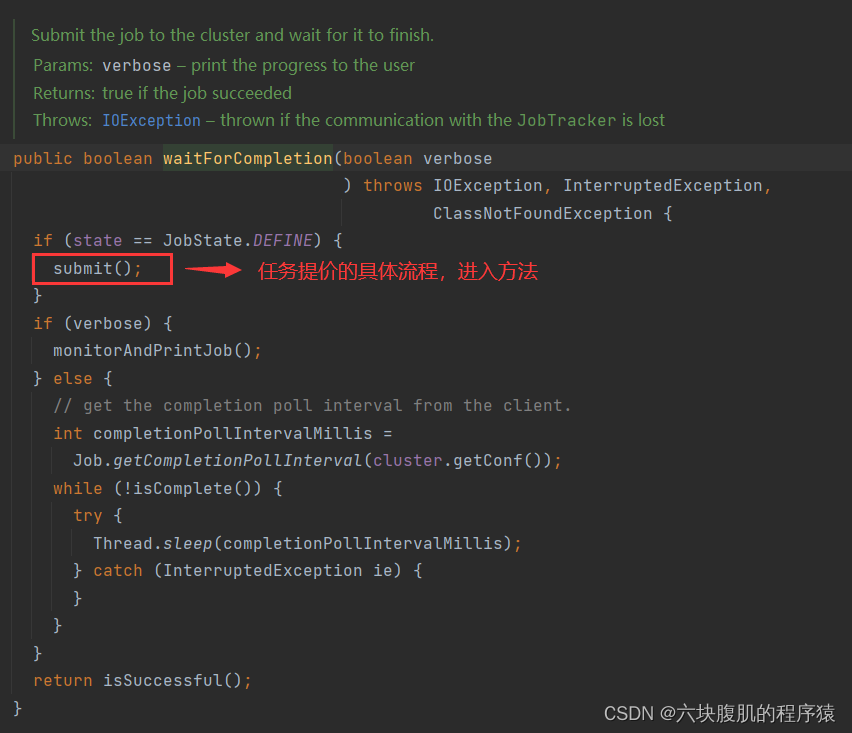
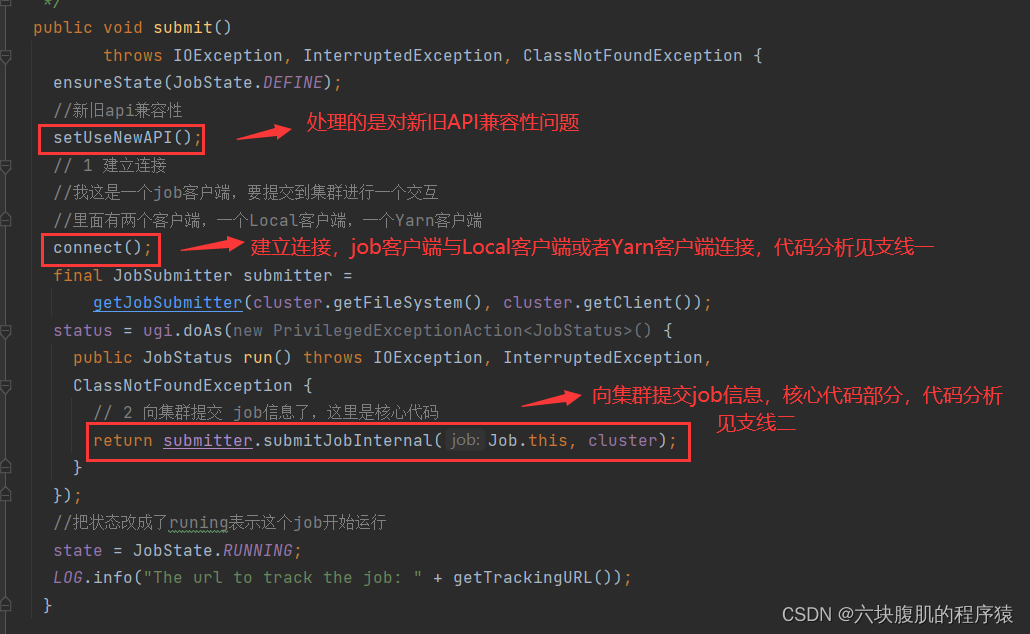
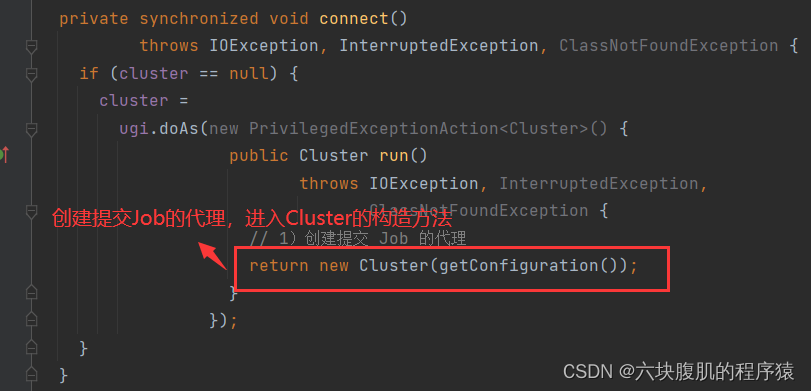
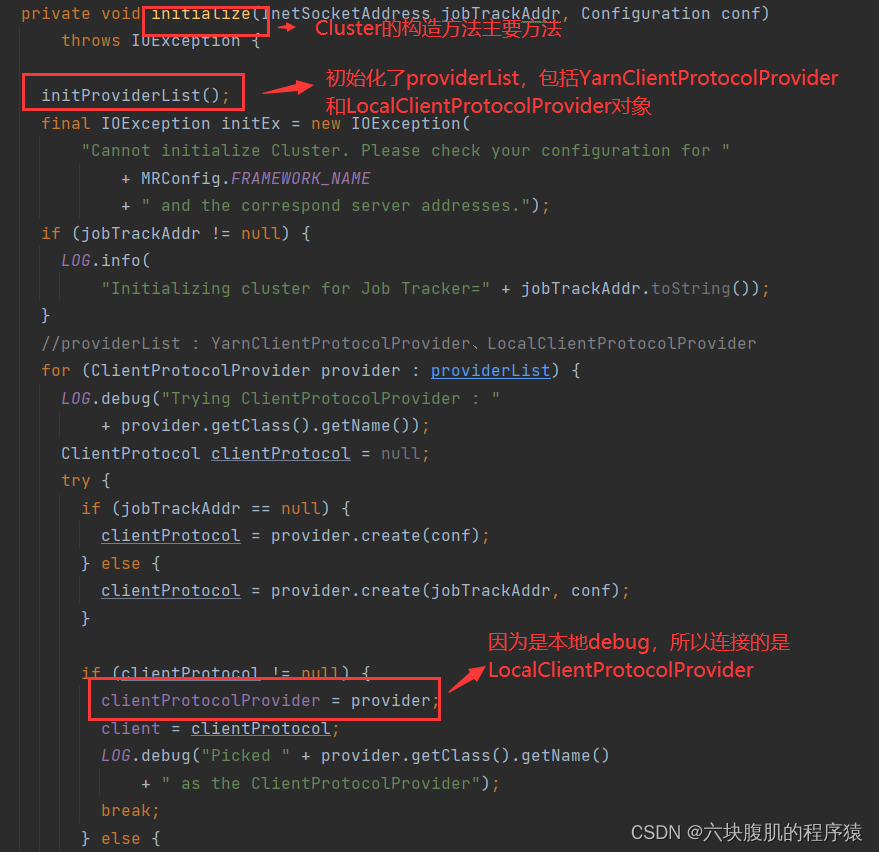
支线一:进入connect();
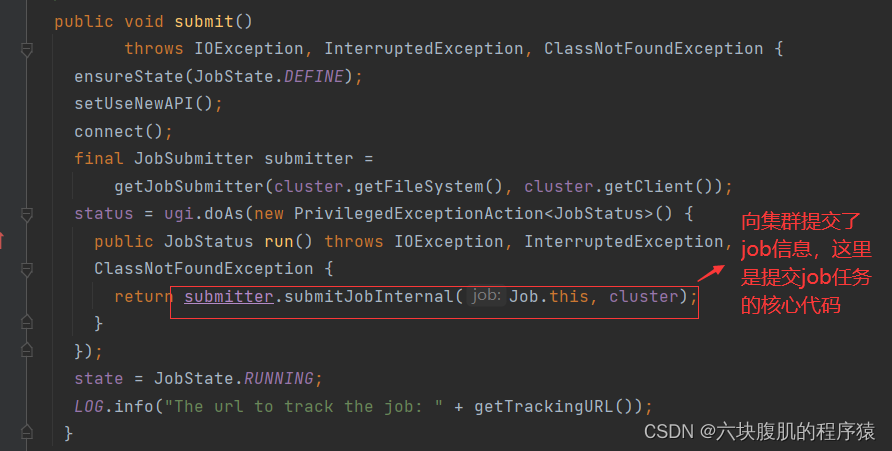
2.支线二:进入submitter.submitJobInternal(Job.this, cluster),向集群提交了job信息,这里是提交job任务的核心代码
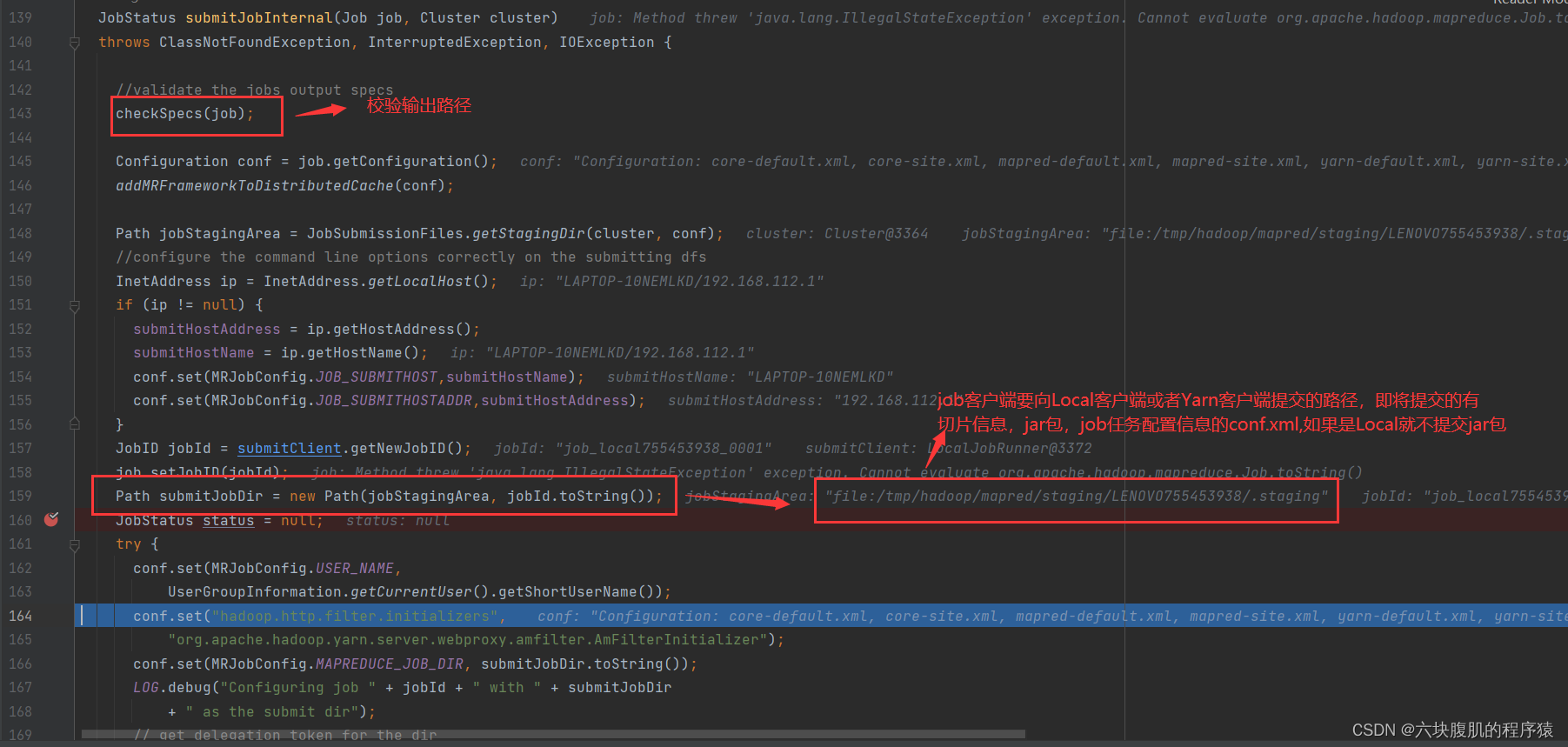
该方法(submitter.submitJobInternal(Job.this, cluster))往下翻:
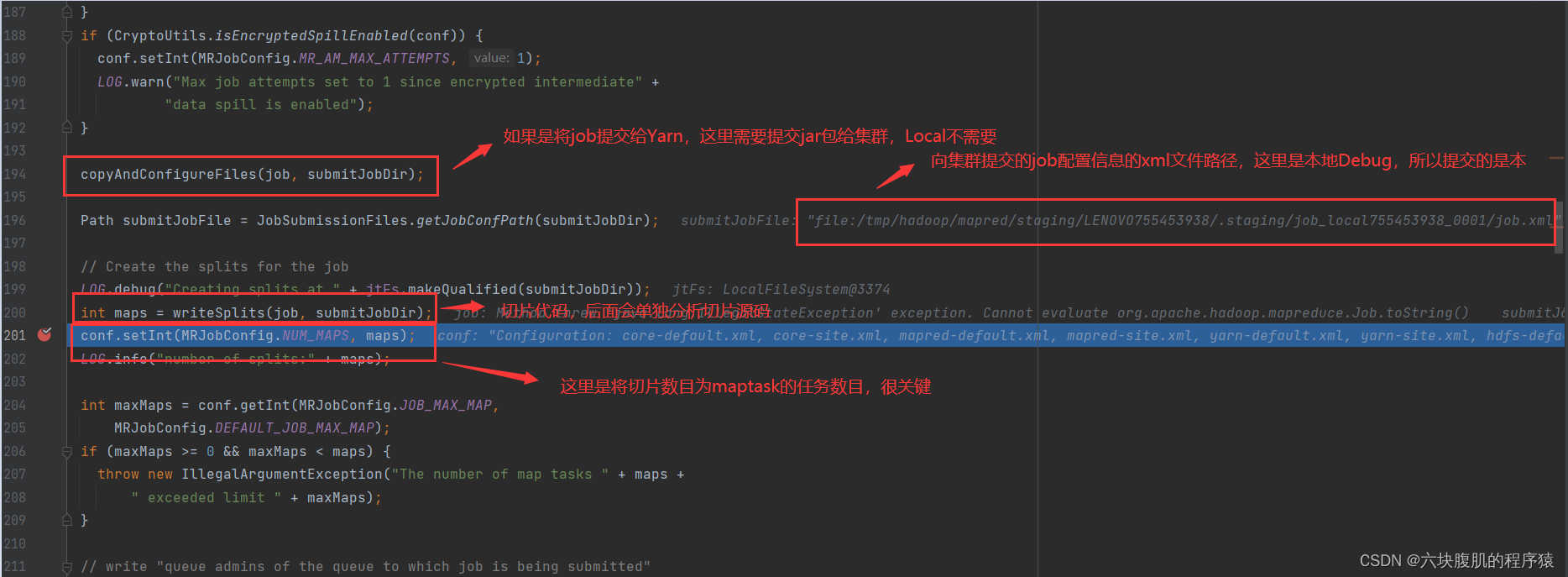
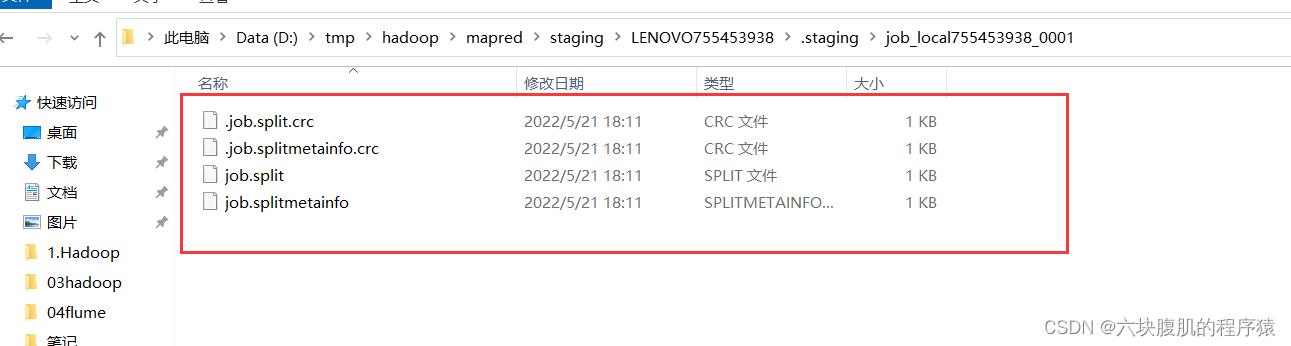
存入了切片信息的本地路径
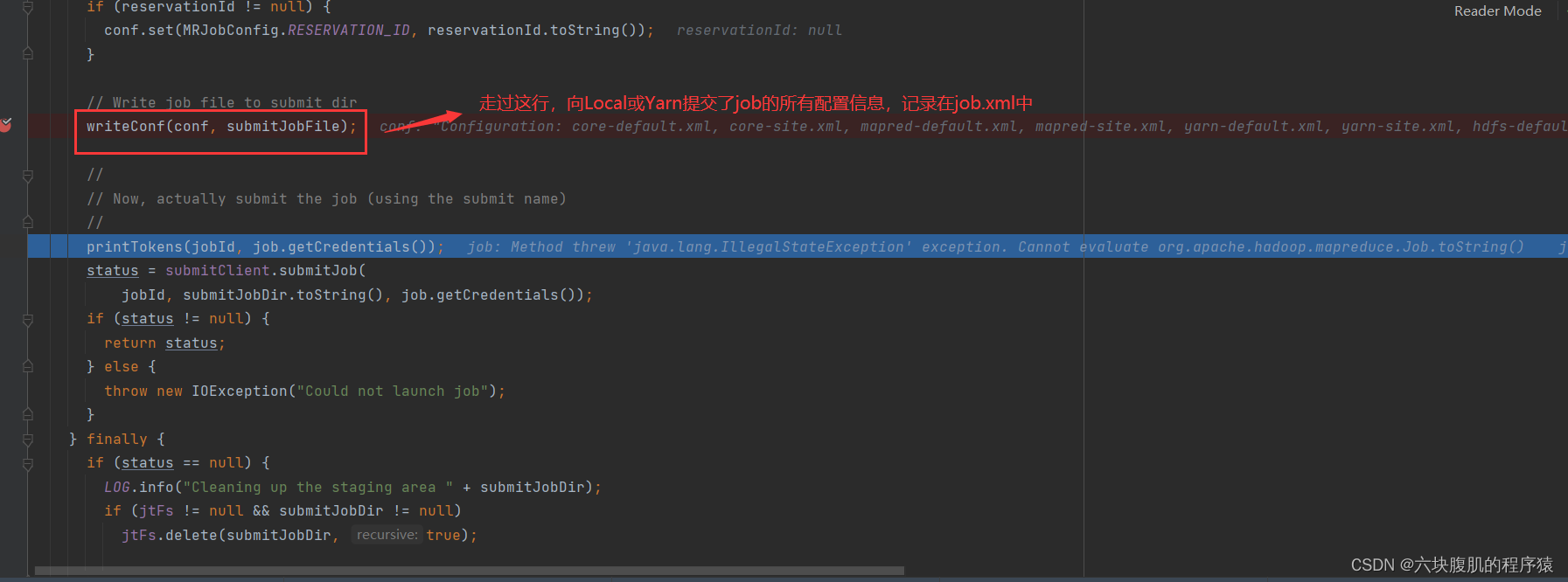
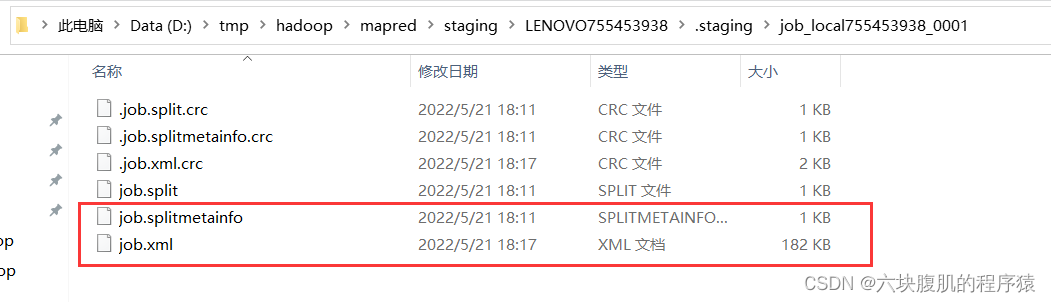
submitter.submitJobInternal(Job.this, cluster)方法继续往下走
该方法继续往下看:将job的任务创建的Application的appContext上下文信息发送到Yarn的ResourseManager
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









