




Redis系列文章
Redis(一)原理及基本命令(柔性数组)
Redis(二)网络协议和异步方式(乐观锁&悲观锁)
Redis(三)存储原理与数据模型(hash冲突、渐进式rehash)
Redis跳表
简介
Redis 中的有序集合(Sorted Set)是用跳表(Skip list)来实现的。这里就需要了解一下跳表的概念。
链表:链表插入,删除某一个节点的时间复杂度是O(1),但是查询的时间复杂度是O(n)。
跳表就是解决链表在有序节点场景下的查询时间复杂度高问题。时间复杂度能达到O(logn)。
跳表
跳表是有多个层级的链表组成。如下图的多级索引和原始链表,每层索引都是一条链表。
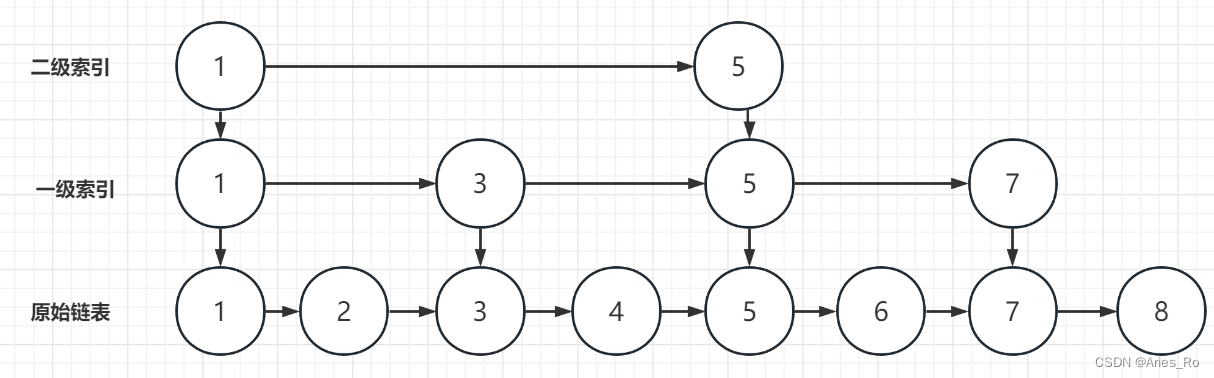
跳表每一层的链表都会随机包含一些原始链表的节点(通过跳表的动态更新策略实现)。层数越高,链表节点越少。
查询策略:
因此查询节点时,从最高层级向下查找,通过高层级索引节点的大小和待查找值大小比较,就能比较出查找值大小是在哪两个节点之间,或者就等于某个节点。再一步一步往低层级索引的链表上查找,最终总能找到相等的那个节点。
可以看出,跳表其实是一种空间换时间的策略来减少查询的时间复杂度。
动态更新策略
插入节点
- 在跳表中插入新元素时,需要先在底层链表中插入该元素,然后决定该元素是否要成为索引节点。
- 可以使用随机函数来决定该元素是否需要成为下一层的索引节点,如果需要,则在下一层都插入一个新的索引节点,该索引节点指向上一层中同一位置的元素。
删除节点
- 在跳表中删除元素时,需要先在底层链表中删除该元素,然后考虑是否需要删除对应的索引节点。
- 可以从顶层开始遍历跳表,如果某个索引节点指向的元素已经不存在了,则需要删除该索引节点,同时将上一层中相同位置的索引节点指向下一层中相同位置的元素。
- 如果最上层的索引节点被删除了,则需要将跳表的高度减少一层。
跳表的高度控制策略
跳表的高度控制策略通常是基于概率的可以定义一个概率p,每次插入元素时,以概率p(0<p<1)决定是否将该元素作为索引节点。查询时间复杂度就是log1/p(n)。
如果是以1/2概率决定是否添加链表,则跳表的高度最大为log2(n)。查询效率也就是log2(n)。
概率过大 vs 概率过小
概率过大,过小都不好。
概率过大会导致跳表中索引节点的数量增加,从而增加了查询时需要访问的节点数,降低了查询效率。因为跳表的查询效率取决于索引节点的数量,节点数量越多,查询效率就越低。
概率越小并不一定就越好。因为概率越小,索引节点的数量就会减少,从而节省了空间,但是查询效率也会降低。如果概率过小,跳表的高度可能无法达到预期的水平,从而失去了跳表的优势。
为什么使用跳表不使用B+树
Redis使用跳表(Skip List)而不是B+树来实现有序集合(Sorted Set)主要基于以下几个原因:
简单性和可读性: 跳表相对于B+树来说更简单,易于理解和实现。跳表的设计概念相对清晰,而B+树可能需要更多的复杂性和专业知识来正确实现。Redis一直以简单和易用性为设计原则之一。
内存局部性: 跳表在访问元素时具有较好的局部性,这有助于减少缓存未命中率。在实际使用中,内存局部性可以提高性能,而跳表的结构对于局部性的优化较为有利。
写入操作简单: 对于有序集合这样频繁进行插入和删除操作的场景,跳表的修改操作相对简单,而B+树可能需要更复杂的平衡和分裂操作。
无锁设计: 跳表的插入和删除操作不需要全局锁,这在并发场景下更为适用。Redis强调的单线程模型中,避免使用全局锁是一个重要的设计目标。
虽然B+树在某些情况下可能在查询性能上更优,但在Redis的使用场景下,对于有序集合的操作更加频繁,跳表的设计能够更好地适应这种特定的使用需求。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











