






Explain使用与详解

show warnings的作用是可以看到mysql内部优化后的sql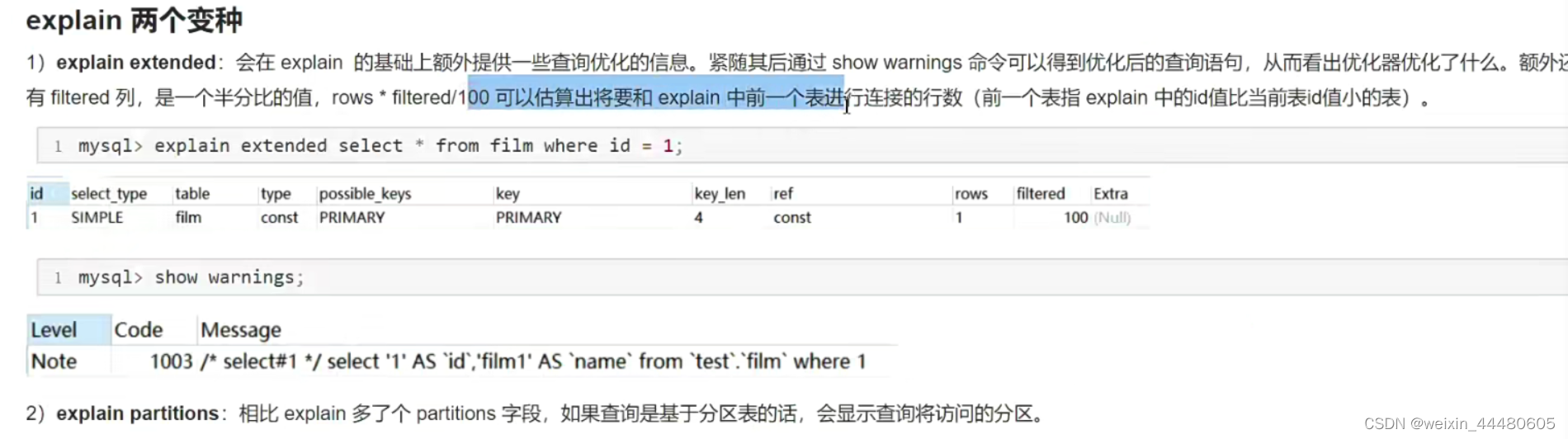
explain-id列
id越大越先执行,相同id靠前的先执行
explain-select_type数据列
- simple:简单查询,查询不包含子查询和union
- primary:复杂查询中最外层的select
- subquery:包含在select中的子查询,select后面的子查询只能是一列数据,且有筛选条件使之与from的数据一一对应。举例
"查询每个部门的平均工资,部门id和部门名字": select jo.*,( select 部门名字 # select后面的子查询不能多个列,只能一列且一行 from 部门表 where jo.部门id = 部门表.部门id #有筛选条件,就变成单个数据,没有where就变成一列是不对的,且slect只能查询一列 ) from ( select 部门id,avg(工资) avg from 员工表 group by 部门id - derived:包含在from子句的子查询。mysql会将结果存放在一个临时表中,也称为派生表
type列 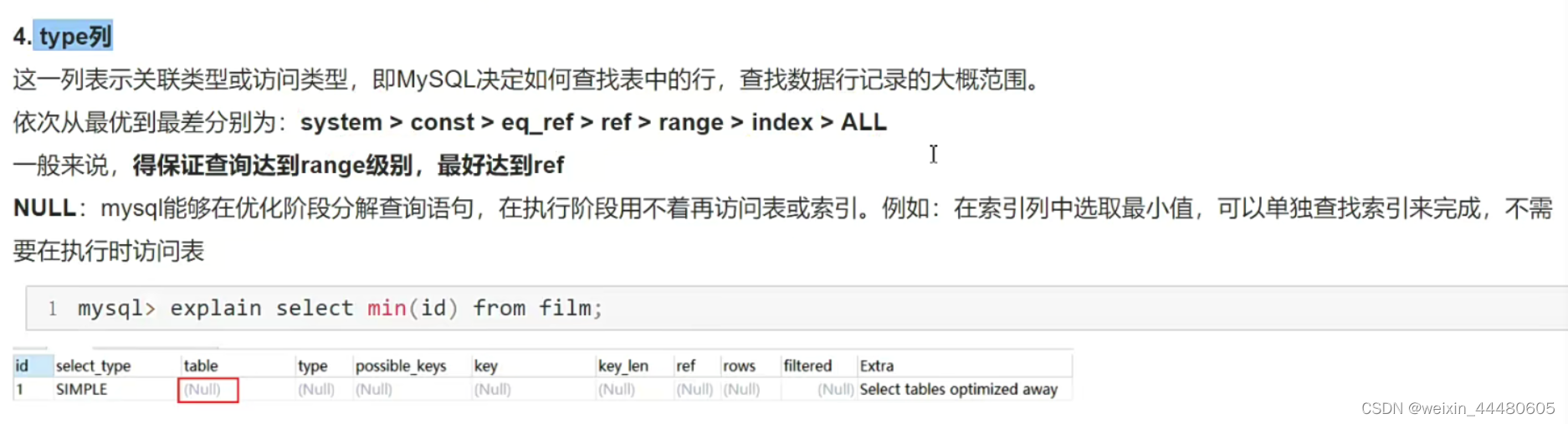
const:查询常量一样,效率很高
system:表只有一行数据
eq_ref: 主键关联,两个表关联查询,一个表先查出来,后一个表就是eq_ref
ref:相比eq_ref,不使用唯一索引,而是使用普通索引或者唯一索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。
rang: 走索引,但是是范围查询(大于小于等于)
index:扫描全索引就能拿到结果,一般是扫描某个二级索引,不是从根查找,是直接扫描二级索引的叶子节点
All:扫描全索引就能拿到结果,一般是扫描某个主键索引,不是从根查找,是直接扫描主键索引的叶子节点
插播:为什么要二级索引,因为一级索引包含了所有数据,占用内存会比较大,二级索引如果包含结果集,就走二级索引,如果不包含的话可能会有回表操作,效率会变低
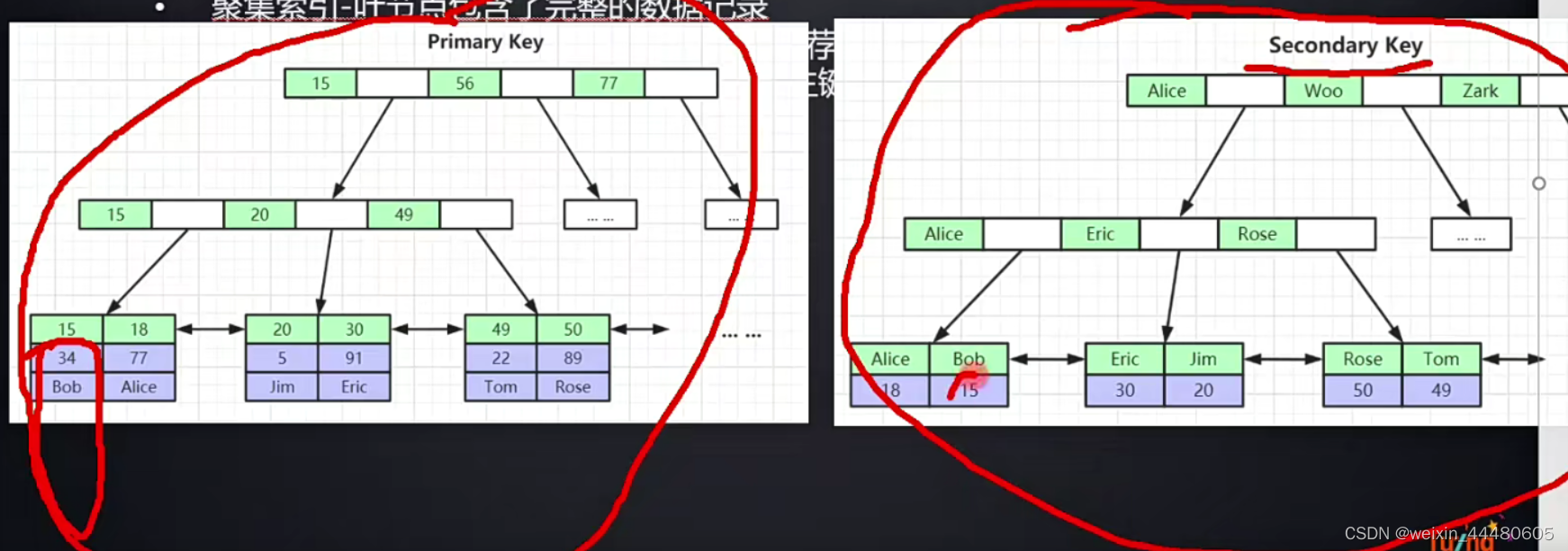
key_len
可以在有联合索引的场景下看看走的是哪个索引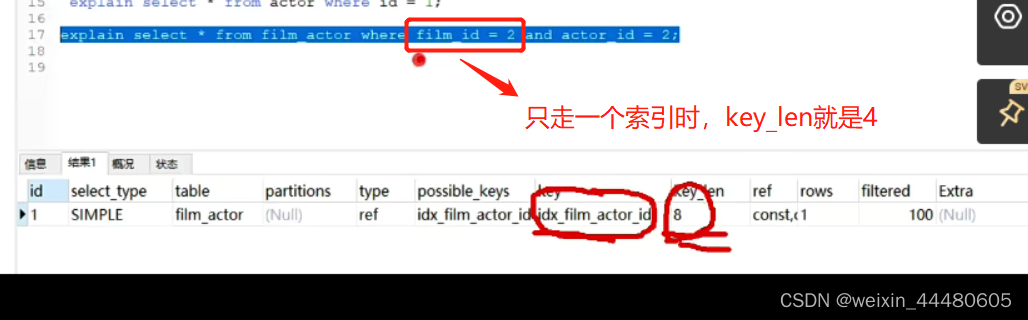

rows列
这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数
extra列
这一列展示的是额外信息。常见的重要值如下:
- using index:使用覆盖索引,刚刚上文提及的type的index就是这种情况,具有二级索引的时候,先查二级索引,且select的字段在二级索引树上都有,不用回表
- using where: 使用where语句来处理,并且查询的列未被索引覆盖,即ALL,需要回表
- using inde condition:查询的列不完全被索引覆盖,where条件是一个前导列的范围,rang。用到了联合索引的第一个索引,且是范围查询
- using temporary: mysql需要创建一张临时表来处理查询,出现这种情况是需要优化的
- using filesort: 使用order by的时候排序,如果空间太大就要用磁盘排序(文件),不然就是内存。如果是用索引来order by就不会有这种情况
- select tables optimized away:使用某些聚合函数(比如max min)来访问存在索引的某个字段是
从B+树底层分析常见索引优化原则
全值索引
我们最好就是要把联合索引的全部作为条件查询,这样效率会高一点,可以通过观察key_len的字节数来看是否满足。
不在索引列上做任何操作(计算,函数,自动或者手动的类型转换),会导致索引失效而转向全表扫描
尽量少用select *,尽量使用覆盖索引(只访问索引的查询(索引列包含查询列))
不等于的条件搜索也可能会使索引失效(并非100%生效)
is null, is not null一般情况下也无法使用索引,null的非主键索引会放在左边或者右边,叶结点连接起来
模糊查询中。百分号在前是使用不了索引,百分号在后能做索引。(left函数在底层是等于号连接,不是这种模糊查询)这种情况可以用覆盖索引优化
字符串不加单引号索引失效
or,in可能不会走索引















 7437
7437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









