









在 Doris 数据库的运行过程中,Compaction 作为一项关键机制,对数据的存储和查询性能有着巨大影响。然而,如同任何复杂的系统,Compaction 过程也可能遭遇各类问题,影响数据库的正常运行和性能表现。本文将详细探讨一些常见的 Compaction 问题,包括 Compaction score 高、Compaction 失败、Compaction 占用资源多以及 Compaction 导致 BE core 等情况,并提供相应的排查思路和处理手段。

Compaction score 居高不下,咋回事?
1. 持续失败拖后腿
Compaction 持续失败,score 就容易升高。那该如何定位是compaction失败了呢?
-
对于 2.1.7 之后的版本,可用查询 top score 的 api(https://github.com/apache/doris/pull/38489)找高分 tablet;
-
对于2.1.7之前的之前版本,可以用 “grep permits” 查看日志,或者直接问用户高频导入表,再通过 “FE show tablets from table” 看 tablet 的 version 数量。
进一步确认,用 “grep ${tablet_id} be.INFO | grep compaction”看失败日志,
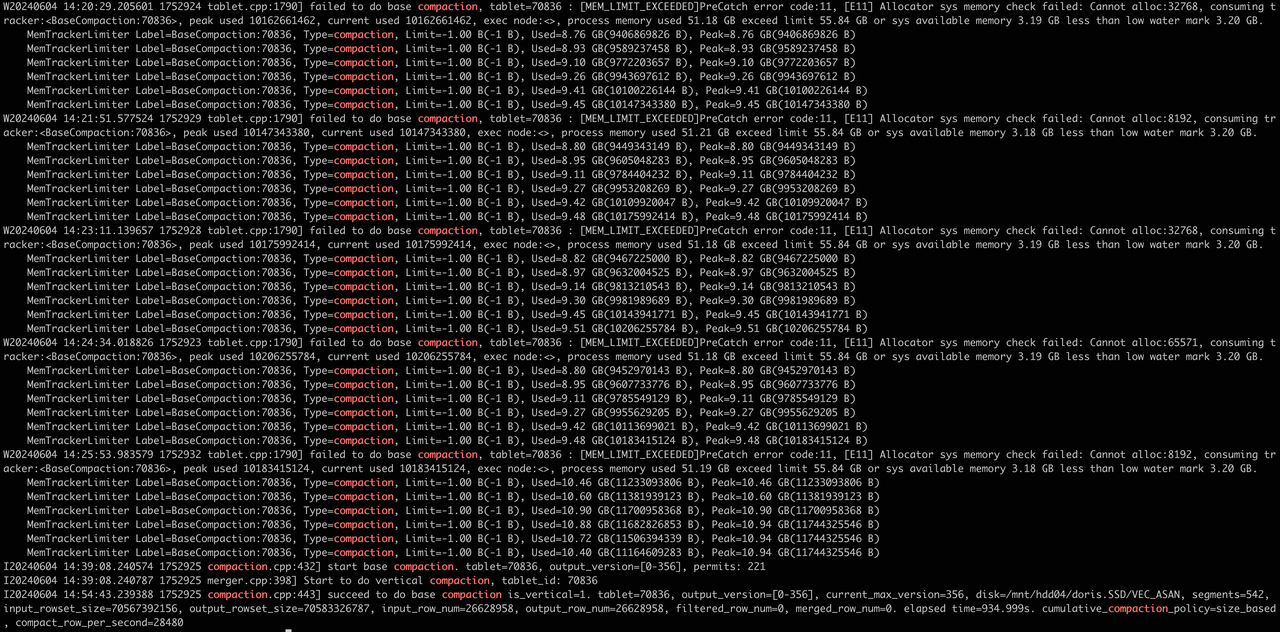
“curl ip:port/api/compaction/show?tablet_id=${tablet_id}” 查 compaction 状态。
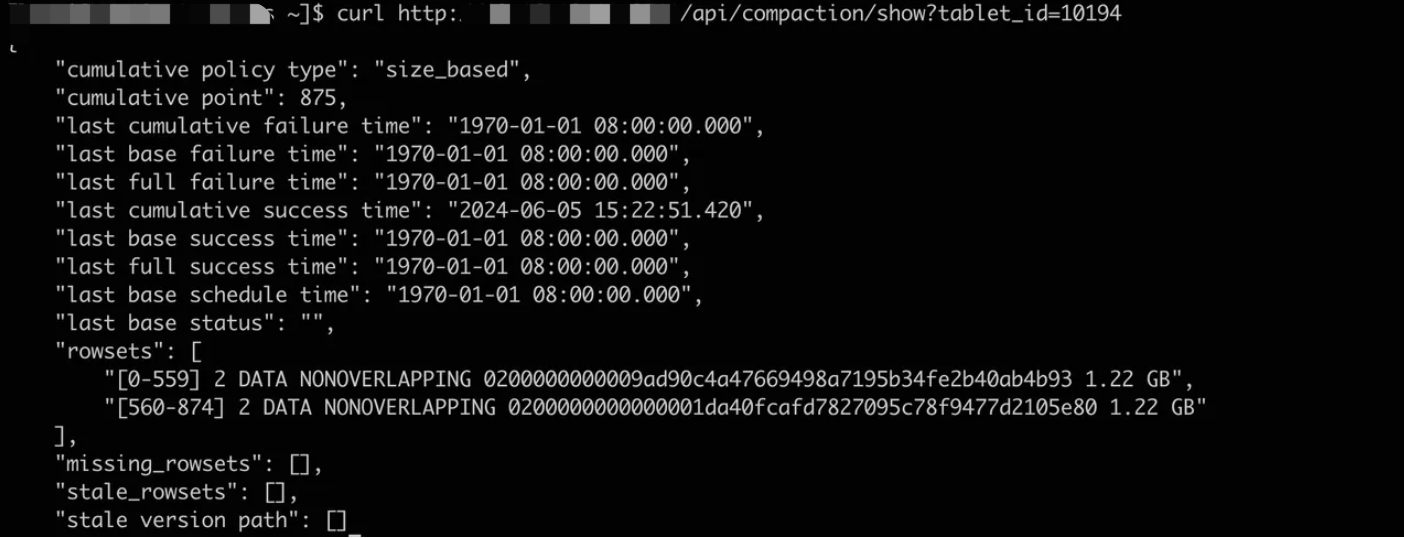
2. 用户操作 “小失误”
bucket 数量没设置好
bucket 数量设得太小,compaction 无法充分并发;设得太大,任务调度又过多。一般建议按 tablet 1GB - 10GB 的最佳实践来设置。
delete 操作太频繁:
查看 compaction status,若有大量 delete,就可能是这问题。比如电商交易数据分析场景,用户频繁删无效订单,compaction 处理大量 delete 标记,score 升高,性能下降。
3. Compaction 执行 “不给力”
当 compaction 消费者线程满负荷,score 还高,就得找找原因了。
判断方法:使用下面的方式来查看compaction 一段时间内的平均并发数
cat be/log/be.INFO | grep -E "succeed to do base compaction|succeed to do cumulative compaction" | awk '{print $23}' | awk -F= '{print $2}' | awk -Fs '{sum+=$1} END {print sum}'
- 用上述的命令统计一段时间内compaction的总耗时。
- 计算统计的clock time,比如统计的日志文件包含14:00 到 14:20日志,那clock time = 20min * 60 = 1200秒
- compaction的平均并发 4000 / 1200 = 3.3 并发
- 然后获取BE的配置的并发限制和compaction线程数量,如果没有配置则为默认,如果实际的并发已经接近设置的并发,则是满负荷工作。
细分原因:
线程数不够:
-
2.0.x 版本,默认线程数:base compaction thread num = 4,Cumu compaction thread num = 10;
-
2.1.x 版本,默认线程数:Base compaction thread num = 4,Cumu compaction thread num = -1(每块盘一个)。
常见问题是用户在 be conf 里只配了 1 块盘,导致只有一个 cumu thread。因此只有一个cumu thread。
处理方式:调大线程数,下列为对应的配置名,支持动态修改。max_base_compaction_threads ,max_cumu_compaction_threads
注意:调整的时候,注意观察用户磁盘的cpu,io util等资源
稀疏宽表拖慢节奏:表列多但单行数据不大,比如上千列,一行几百字节,通过 “show tablets from table” 或 compaction 日志估算单行长度(input_rowset_size /input_row_num)

若符合这种情况,调整 BE 配置 “vertical_compaction_num_columns_per_group = 50” 即可。
4. Compaction 调度 “掉链子”
线程池没用满,score 却高,可能是调度问题。
total permits 限制:permits 限制 compaction 多路归并排序多路数来控制内存,但队列中的 task 也占 permits,导致任务多时有并发限制。
判断方法是:
- Mow 高频导入;
- top -H 显示 base compaction 有 3 - 4 在执行;
- cumu compaction 并发远未达线程池数量;
- score 较高;
- 版本小于 2.1.8(2.1.8 版本已调大默认值)。
处理方式是调大 BE 参数 “total_permits_for_compaction_score = 1000000” 。
tablet 太多调度慢:Compaction 生产者扫描磁盘生成 task,tablet 太多,扫描耗时久,任务生产就慢。
判断方法是:
- 通过 “Show backends” 看 BE 上的 tablet 数量,若单个 BE 的 tablet 达 10w 级别,可能是这原因。2.1.8 之后版本,设 BE 配置 “compaction_num_per_round = 4”(可按需调整),就能一次扫描产生多个 task。
tablet skip 机制出问题:频繁的元信息扫描会导致大量的 CPU 资源浪费。因此在 Doris 2.0.0 版本中引入了 Tablet 休眠机制,来降低元数据扫描带来的 CPU 开销。通过对长时间没有 Compaction 任务的 Tablet 设置休眠时间,一段时间内不再对该 Tablet 进行扫描,能够大幅降低任务扫描的压力。同时如果休眠的 Tablet 有突发的导入,通过主动触发的方式也能顾唤醒 Compaction 任务,不会对任务的实时性有任何影响。
通过上述的主动扫描+被动触发+休眠机制,使用最小的资源消耗,保证了 Compaction 任务触发的实时性。2.1 版本修改主动扫描机制后,此休眠机制在高频导入场景有问题。
判断方法是:
- 高频导入场景;
- “grep {tablet id} be.INFO | grep compaction | grep -i start” 发现 start 日志间隔两分钟。
处理方式是设 BE 配置 “enable_skip_tablet_compaction = false”(不支持动态修改)。
内存超限不触发:内存使用唱过软限,导致没有触发compaction
判断方法是:
- BE 内存使用率超 soft limit
- compaction 不执行(“grep compaction be.INFO | grep -i start” 无日志)。
处理办法是降低 BE 内存使用。
单盘并发受限:Compaction 生产者线程判断磁盘并发 compaction 是否超限制,超了就不再产生该盘 task。
判断方法是:
- 检查单盘并发是否达 BE 配置值(默认值:compaction_task_num_per_disk,hdd 盘默认 4;compaction_task_num_per_fast_disk,ssd 盘默认 8),若超了,调整 “compaction_task_num_per_disk” 或 “compaction_task_num_per_fast_disk”。
5. 通用处理小妙招
对于 Compaction score 高的问题,可调整 “max_tablet_version_num”(默认 2000),还能手动触发 compaction,临时处理用 “curl -X POST http://be_host:webserver_port/api/compaction/run?tablet_id=xxxx&compact_type=cumulative”。同时,要收集 Compaction score 监控、BE 日志、tablet 的 rowset 布局(“curl be_ip:webserver_port/api/compaction/show?tablet_id=${tablet_id}” 获取)等信息。
Compaction 失败,别慌!
1. 内存问题 “捣鬼”
通过 “grep compaction be.INFO | grep {tablet_id}” 看失败原因,内存分配失败日志类似。
W0427 19:40:58.254163 7873 compaction.cpp:372] fail to do CloudBaseCompaction. res=[MEM_LIMIT_EXCEEDED] PreCatch error code:11, [E11] Allocator sys memory check failed: Cannot alloc:5148, consuming tracker:[BaseCompaction:135202205](BaseCompaction:135202205), peak used 1435738416, current used 1164740816, exec node:<>, process memory used 105.03 GB exceed limit 109.63 GB or sys available memory 11.71 GB less than low water mark 12.18 GB. no enable stack, _FILE:/home/ec2-user/selectdb-core/be/src/olap/rowset/segment_v2/segment_iterator.cpp, __LINE:2000, _*FUNCTION*:auto doris::segment_v2::SegmentIterator::next_batch (vectorized::Block *)::(anonymous class)::operator ()() const, tablet=135202205.758764227.6e8b36c0cc1b4ac2-9f14bb5b6d058fe6, output_version=[2-8237]
细分有以下几种情况:
-
其他请求抢内存,compaction 偶发失败:若不是持续失败且 compaction score 没明显升高,可先观察。
-
单个 compaction 内存占用多:调节 BE 的 “cumulative_compaction_max_deltas” 配置值(默认 1000),限制参与 compaction 的 rowset 个数来控制内存。
-
多个 compaction 内存占用多:同样调节 “cumulative_compaction_max_deltas”,或者限制 compaction 线程个数,调整 “max_base_compaction_threads” 和 “max_cumu_compaction_threads” 配置。
对于上述细分的原因需要查看memtracker,当前compaction内存使用的情况来定位。
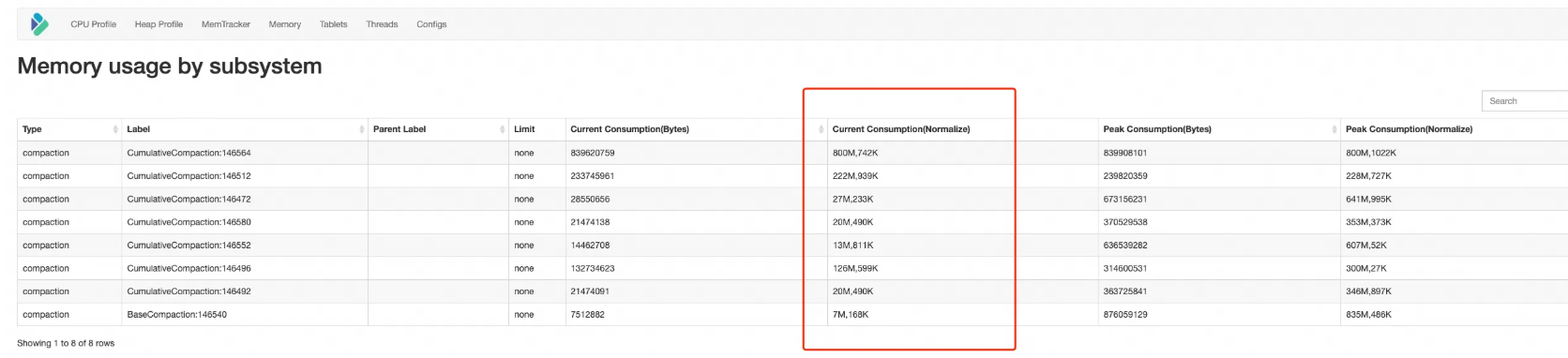
2. missing rowset 来 “捣乱”
通过日志判断,
W0319 16:13:58.449980 1221594 cumulative_compaction.cpp:113] There are missed versions among rowsets. prev rowset verison=[2-209], next rowset version=[218-218], tablet=143405174.1524602546.e44ef3f8419888cf-c1c834105ff8d0b3
解决办法是处理 missing rowset 问题。 解决办法参考文档:Doris Tablet 损坏如何应对?能恢复数据吗?
Compaction 占用资源过多,如何应对?
1. cpu 资源被 “霸占”
用 “top -H” 确认是否是 compaction 线程导致。
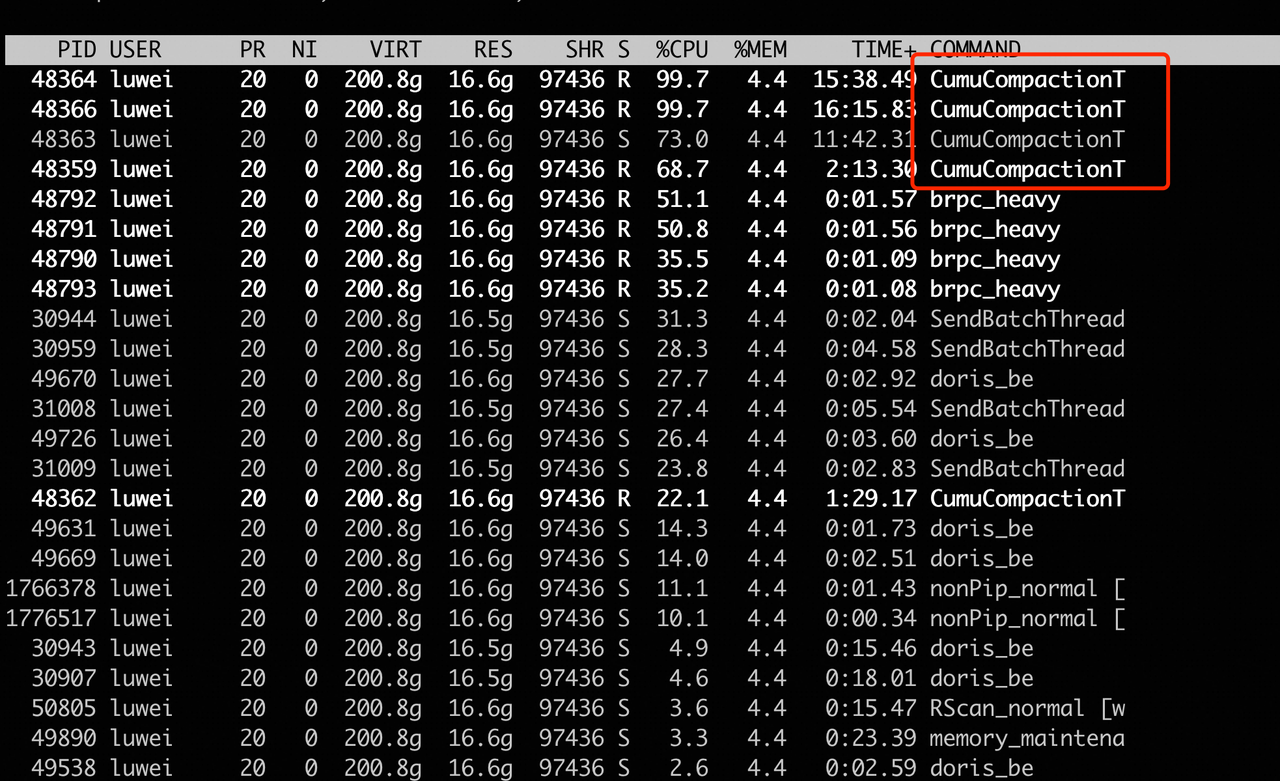
处理方法有两种:一是调做 compaction 的线程数量,“max_base_compaction_threads”(默认 4 )和 “max_cumu_compaction_threads”(默认每块盘 1 个);二是调每个盘上 compaction 的并发数量,HDD 盘调 “compaction_task_num_per_disk”(默认 4),SSD 盘调 “compaction_task_num_per_fast_disk”(默认 8)。调节后要盯着 compaction score 变化,防止并发限制过小导致 score 升高。
2. 内存资源 “告急”
参考 Compaction 失败中内存超限导致失败的处理方式。
Compaction 导致 BE core,怎么办?
1. 偶发一次别紧张
收集 be.out、BE.info、core dump、be 版本信息(含具体 commit id),备注特殊操作,比如 scheam change 等。然后提供信息找一下社区同学,辅助解决。
2. 持续失败要重视
这种情况可能影响使用,先止损。用 “show tablet {tablet_id}” 通过 tablet id 找到表,然后配置 BE.conf“disable_auto_compaction = true” 关闭 BE 的 compaction,再用 “alter table ${tableName} set (“disable_auto_compaction” = “true”)” 关掉表的 compaction,最后再打开 BE 的 compaction(配置 BE.conf“disable_auto_compaction = false”)。虽然 core 出现在 compaction 栈上,但不一定是 compaction 的问题,因为它是后台持续读写线程,查询也可能出现 core,只是没被发现。
今天关于 Doris 中 Compaction 问题的解析就到这里啦!大家在实际使用中遇到相关问题,不妨按照文中方法试试。要是还有疑问,欢迎在评论区留言,我们一起探讨。或者直接联系社区同学 OR me,也别忘了点赞、分享给更多有需要的小伙伴!


















 1543
1543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











