






-------------------------------------------------不可转载-----------------------------------------
Citation: 图片均来源于原文和文章的 repository,请看Repo link
文章题目:Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection (20 Mar 2023)
DINO → 是用来做目标检测的模型,模型repo: GitHub - IDEA-Research/DINO: [ICLR 2023] Official implementation of the paper “DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection”,感兴趣的可以看一下
一、模型结构🐒
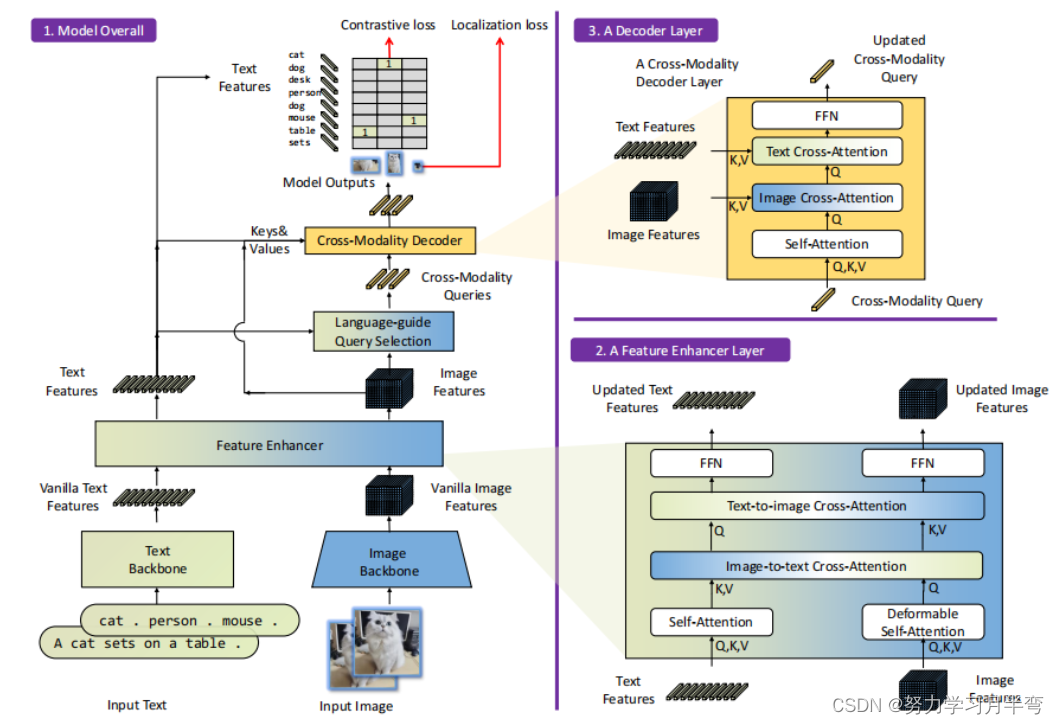
图1
模型示意图是从下到上看的,具体pipeline参考下文“训练细节”一段(注意左边到右边有淡淡的一个用来映射的色块,可以看到结构放大的细节)
输入 → [Image, Text] 对子,
输出 → bounding box (bbox) 以及各个框对应的名词短语(类别),就是多对 [bbox, label]
模型主要由三个部分组成:
- Image encoder\backbone, text encoder\backbone →用于提取图片和文本的特征
-> Image encoder 使用的是类似 Swin Trandsformer 的结构,提取 multi-scale image feature
-> text encoder 使用的是类似 BERT 的结构
-> 提取出来的特征叫做 vanila feature,平凡的特征(吃起来是香草味的,误🤭),有待进行特征融合处理 - Feature Enhancer → 用于融合图像和文本的特征,feature enhancer的具体结构如图1右下角
-> 先分别使用 deformable self-attention,self-attention 层来加强图像和文本特征
-> 然后紧接着是一个 image-to-text cross-attention (图像到文本交叉注意力) 和一个 text-to-image cross-attension (文本到图像交叉注意力)层,这两层受到 GLIP 结构的启发,是为了把不同的形式的特征 (multi-modalities features)融合在一起 - Cross-Modality Decoder → 结合文本和图像的特征,用来处理 query (之后会讲到),输出最终的 query
-> 有 image cross-attention 和 text cross-attention 层分别结合图像和文本的信息
-> 旨在让不同形式的特征有更好的互相匹配(alignment) (暂且这样子翻译,还没想到更好的翻译。。。
(挽尊😅)这里写的关于模型的内容都是从文章第三部分 Grounding DINO 过来的,但是有一章 3.2 Language-Guided Query Selection 没写进来。因为我觉得这部分是一个逻辑,不算结构,这部分我会写在“训练细节”一段里。
二、文章成就🐒
-
DINO原来是一个closed-set的识别器 (detector),Grounding DINO 延展了 DINO 在 open-set tags 上的识别表现能力,
-
提出了把对 open-set 目标检测的评价指标放到 REC 数据集上。REC 全称是 Reffering Expression Comprehension,强调理解能力,下图的右边一栏是REC的一个例子
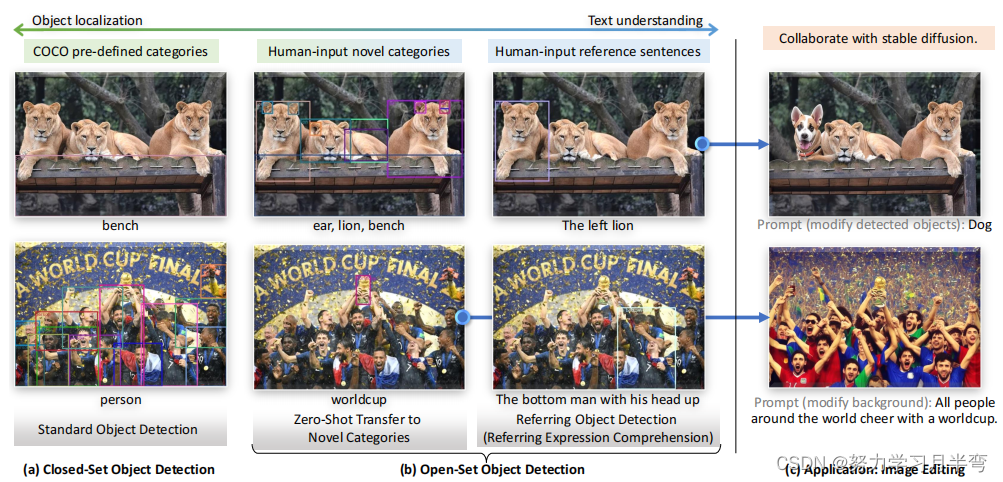
-
实验验证了 Grounding DINO 模型在开放集目标检测任务上的有效性
三、 Pipeline描述🐒
-
输入 → (Image, Text) pair,分别送入 image encode 和 text encoder,得到各自的 vanilla feature
-
随后使用 feature enhancer 来对两种特征进行深度融合,特征提取到这一步完毕
-
对融合后的特征 (在图中标为 text/image feature),网络用一个 Language-guide Query Selection 逻辑模块来对特征进行筛选
i. 这个模块的目的是为了高效地使用输入文本来引导网络进行目标检测
ii. 做法:选出那些跟输入文本更加有关的特征来来作为网络后面那个 cross-modality decoder 的 queries (Note: 具体做法是和DINO一样,并不是直接使用特征来当query而是用某种手段吧 query 混合起来,至于细节文中没有讲,但是cite了一下DINO,可以去DINO原文中找相关内容)
iii. Encoder 使用到的 query 包含两个部分,(content, positinal), 即内容和位置 (Note: 文章中说到 query 关于位置信息的部分被形式化成 dynamic anchor boxes)
iiii. 这一部分使用到的算法放在下图了,
-> 其中 num_query 是参与 cross-modality decoder 决策的 query 的数量 (作者用了900个)
-> bs 是 batch size,ndim 是特征的维度
-> num_img_tokens 和 num_text_tokens 是图片、文本 tokenize 后采用的 token 的个数

-
最后送进 decoder ,结果再与 text features 进行匹配,计算 contrastive loss, localization loss 用以更新参数
四、 Inference🐒
我用的是 linux系统,python=3.8,cuda=10.1, torch=1.8.0, torchvision=0.9.0
python >= 3.8是很重要的一点,因为作者代码里面用到的依赖里面有一个叫supervision的包如果和其他低于3.8的python版本不兼容。
关于checkpoint: 作者文中说到训练了两种backbone的版本,一个叫Grounding-DINO-T,用的是 Swin-T 作为主干,另一个是 Groungind-DINO-L, 用的是 Swin-L 主干。两个版本用的 text encoder 都是 huggingface 的 BERT-base。但是repo里面给的是 Swin-T 和 Swin-B 的

可以看到 GroundingDINO-B 在COCO数据集上是有更好的表现效果的 (但是没有说明是fine-tune还是zero-shot,或者是平均,我这里默认他们取平均了)
然后是具体的步骤:
一定要做这一步-——检查CUDA_HOME
要不然会出现报错:
NameError: name '_C' is not defined
这个是他们放在setup.py里面的一个自定义的包,所以说这一步不做的话之后你安好了所有东西都白安装了,你就需要从头再装一遍、
在 teminal 里面运行:
echo $CUDA_HOME
如果没有 print 什么东西就说明你还没有设置path,这样就需要运行下面的指令:
export CUDA_HOME=/path/to/cuda-11.3
之后依次做:
克隆库
git clone https://github.com/IDEA-Research/GroundingDINO.git
进入下载好的库,安装所有需要的依赖
cd GroundingDINO/
pip install -e .
之后下载他们训练好的模型,这里下载的是 SwinT 作为骨干网络的版本,你也可以不在 terminal 里面下载,自己下载到本地(或者是自己上传到服务器)。
mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..
想用 GroundingDINO-B (用 SwinB的版本) 的可以把上面👆的地址替换成:
https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha2/groundingdino_swinb_cogcoor.pth
然后就可以运行一个demo看一下效果(单张图片),指令如下,记得替换成自己的地址
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py \
-c groundingdino/config/GroundingDINO_SwinT_OGC.py \
-p weights/groundingdino_swint_ogc.pth \
-i image_you_want_to_detect.jpg \
-o "dir you want to save the output" \
-t "chair"
[--cpu-only] # open it for cpu mode
如果不用gpu,只用cpu,可以把那个 [–cpu-only] 的方括号去掉。这个 “-t” 后面跟的是 text prompt 的参数,简单的来说就是你跟这个模型沟通说的话(string类型),一般效果比较好的输入是用点隔开的目标标签,例如:
“dog . chairs . person ."
也可以换成对图片的描述句子,但是想要效果好一点需要再输入一个参数 ”–token-spans“来标注句子里面需要识别的 token 的位置,所以需要执行下面这个指令:
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py \
-c groundingdino/config/GroundingDINO_SwinT_OGC.py \
-p ./groundingdino_swint_ogc.pth \
-i .asset/cat_dog.jpeg \
-o logs/1111 \
-t "There is a cat and a dog in the image ." \
--token_spans "[[[9, 10], [11, 14]], [[19, 20], [21, 24]]]"
[--cpu-only] # open it for cpu mode
Note: 以防有人没有听懂,token-spans输入的是从text第几位到第几位是需要被识别的token,这样做的好处是模型不会识别一些抽象的标签,像在上面这个例子里,图片就不会将 ‘there’ 作为识别的对象(如果你输入句子而没有指定token_span,模型会很大可能把 there 的范围也框出来,基本上就是框住整张图片)。
输出的例子如下:

会生成一个test_output文件夹,下面存着原图和预测图。这里预测图看起来大小跟原图不一样是因为我放的是放大版的截图,为了更清晰地观察到 bounding box (bbox)。可以看到标签后面还带了框内的目标属于这个类别的置信度。















 575
575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









