







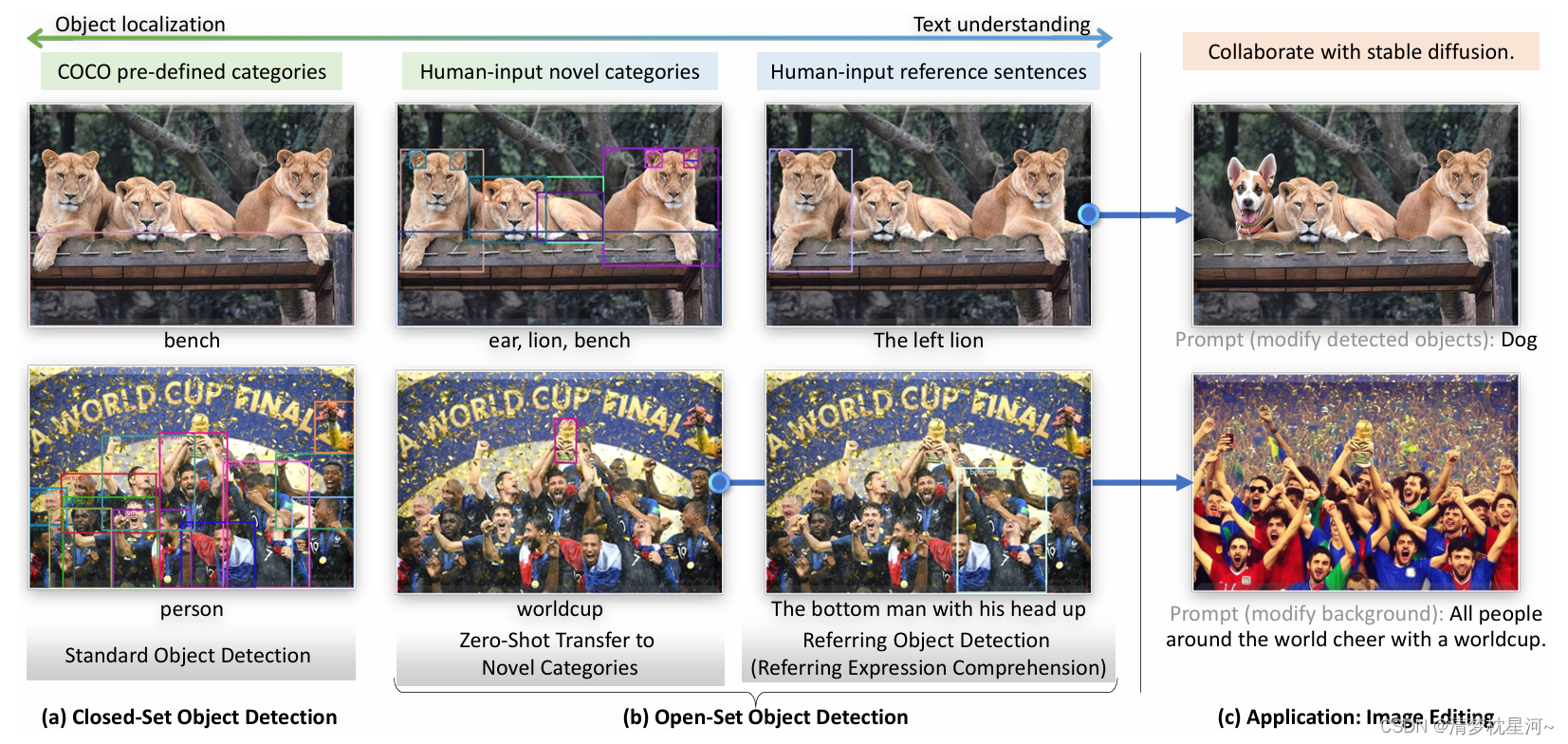
1、简单介绍
GroundingDino是一个多模态检测模型,可以输入文本提示输出视觉目标的位置,实现了文本和图像的匹配。相比较于一众的OVD算法,GroundingDino在文本处理上的灵活度高,因为大多OVD算法是采用clip文本编码器,这个编码器对文本的处理有限,只能是某些单词,一些特殊的名称在clip的预训练模型中没有对应的文本向量。而GroundingDino及部分采用 bert 的模型,可以处理单词、短语和句子等文本,在数据集迁移上更加友好。

Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection,这是GroundingDino的论文标题,大概意思是 把DINO和文本预训练模型结合用于开集目标检测。
官方的GroundingDino只开源了推理的代码,没有给出训练代码,数据集格式也未知,而Open-GroundingDino是作为GroundingDino的第三方实现训练的开源代码,所以关注GroundingDino的工作是否适合迁移到个人数据集中。
GroundingDino的论文地址:https://arxiv.org/pdf/2303.05499.pdf
GroundingDino的Github网址:https://github.com/IDEA-Research/GroundingDINO
Open-GroundingDino的Github网址:https://github.com/longzw1997/Open-GroundingDino
文本提示的预测功能:
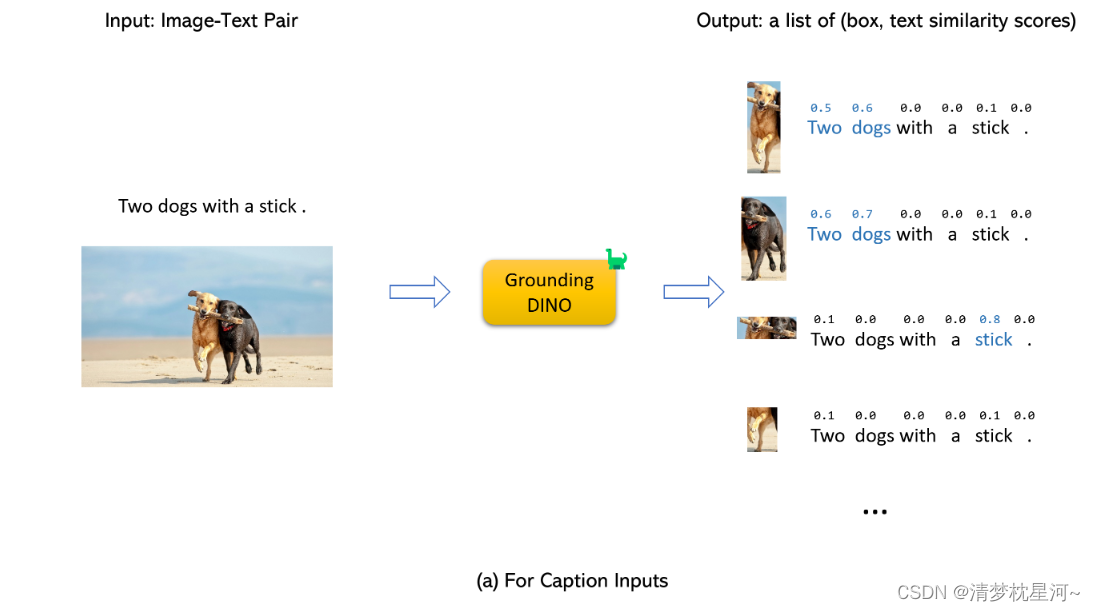
2、推理实现
我是首先想跑通Open-GroundingDino,因为Open-GroundingDino给出了训练代码,同时给出了数据集格式,如果可以跑通非常适合进行迁移。于是我安装了相关环境进行测试。
基本的环境安装跟着requirements.txt走基本上就够了,后面是编译 GroundingDino,给出的操作方法是:
pip install -r requirements.txt
cd models/GroundingDINO/ops
python setup.py build install
python test.py
cd ../../..
跑 test.py 我的也正常执行完了

但是后面准备跑推理代码的时候:
python tools/inference_on_a_image.py \
-c tools/GroundingDINO_SwinT_OGC.py \
-p path/to/your/ckpt.pth \
-i ./figs/dog.jpeg \
-t "dog" \
-o output
结果报错了,说找不到 grounddino这个模块,我看代码目录里有这个文件夹,以为只要修改进行引用就行,结果修改后仍然不行。后面是卡在了 模型加载的地方:
load_res = model.load_state_dict()
出现报错:
AttributeError:tuple object has no attribute load_state_dict
显然模型加载出现了问题,而且很不好解决。
于是我想到 Open-GroundingDino的推理代码应该和 GroundingDino应该差不多,因为Open-GroundingDino是一个第三方实现,是基于原版来匹配的。于是我尝试跑GroundingDino的推理代码。
我把代码下载之后,按照要求进行操作:
git clone https://github.com/IDEA-Research/GroundingDINO.git
cd GroundingDINO/
pip install -e .
mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..
操作之后环境里编译生成了一个groundingdino库,显然这个才是正确的要调的库。我随后开始测试,执行命令:
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py \
-c groundingdino/config/GroundingDINO_SwinT_OGC.py \
-p weights/groundingdino_swint_ogc.pth \
-i image_you_want_to_detect.jpg \
-o "dir you want to save the output" \
-t "chair"
[--cpu-only] # open it for cpu mode
结果,却没结果。代码正常跑完了,但是打开保存的预测结果,发现还是原图,并没有加上预测的框。我想肯定是输入的文本提示有问题,导致无法解析要检测的类别。
其实,在执行命令之前,我已经在 GroundingDINO_SwinT_OGC.py 把 text_encoder_type = "bert-base-uncased"改成 text_encoder_type = "./local/xx/bert-base-uncased" ,因为之前跑过类似的,我就把本地bert文本编码的模型路径加进去了,所以推理代码可以正常执行完毕,但是却没有输出结果。
我不太熟悉 GroundingDINO需要加载bert的文件位置,所以我之间搜索 bert-base-uncased 和 text_encoder_type 找出如下位置处代码 :
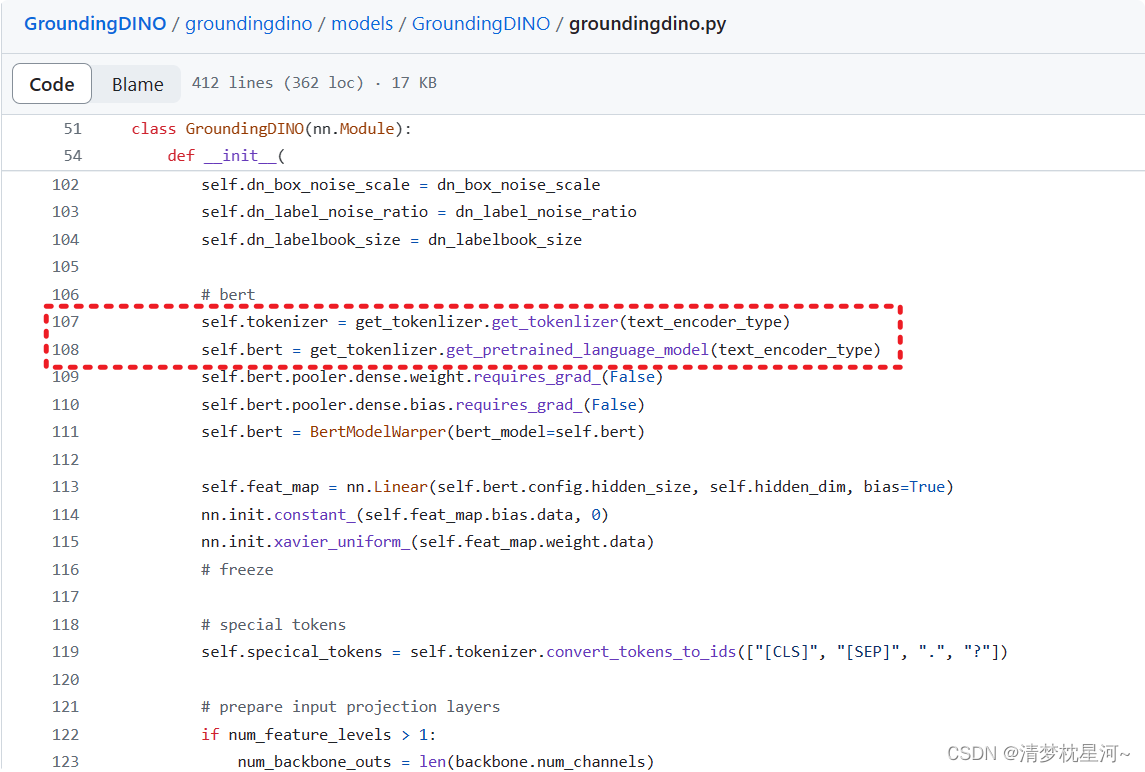
我分别把里面的两个 text_encoder_type 换成 本地的bert-base-cased 的路径,再进行测试,进入结果文件夹,打开图片查看,发现上面就画了提示的目标,如下图所示。

如上就完成了 Open-GroundingDino和GroundingDino的推理流程实现
相关问题解决也可以具体看官方GitHub:https://github.com/IDEA-Research/GroundingDINO/issues/218





















 2241
2241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











