







数据类型
整数: int,有符号范围(-2147483648 ~2147483647),⽆符号(unsigned)范围(0 ~4294967295)
⼩数: decimal,例如:decimal(5,2) 表示共存5位数,⼩数占2位,整数占3位字符串:
varchar,范围(0~65533),例如:varchar(3) 表示最多存3个字符,⼀个中⽂或⼀个字⺟都占⼀个字符
⽇期时间: datetime,范围(1000-01-01 00:00:00 ~ 9999-12-3123:59:59),例如:'2020-01-01 12:29:59'
约束
主键(primary key): 能唯⼀标识表中的每⼀条记录的属性组
⾮空(not null): 此字段不允许填写空值
唯⼀(unique): 此字段的值不允许重复
默认值(default): 当不填写此值时会使⽤默认值,如果填写时以填写为准
外键(foreign key): ⼀个表中的⼀个字段引⽤另⼀个表的主键
数据表操作
-- 创建数据库
--create database 数据库名 charset=utf8 collate=utf8_general_ci;
create database python charset=utf8 collate=utf8_general_ci;
-- 查看数据库
--show create database 数据库名;
show create database python;
-- 使⽤数据库(切换数据库)
--use 数据库名;
use python;
-- 查看当前数据库: database() 是 SQL 的内置函数, 括号不能省略!
select database();
-- 修改数据库
-- 创建
create database testpython charset = gb2312;
-- 修改
-- alter database 数据库名
-- default character set 编码格式
-- default collate 排序规则;
alter database testpython
default character set utf8mb4
default collate utf8mb4_general_ci;
-- 删除数据库
-- drop database 数据库名;
drop database python;
-- 查看所有数据库
show databases;
数据库备份
说明: 在测试⼯作中, 为了防⽌对数据库产⽣错误操作, 或产⽣垃圾数据, 都需 要在操作前, 适当对数据库进⾏备份操作. 垃圾数据: 例如在⾃动化测试中, 对注册模块操作⽣成的所有数据, 属于典型的 垃圾数据, 应该清理
利用工具
步骤:数据库->转储SQL文件-> 数据+结构
使用命令
注意命令是不需要连接数据库的!
mysqldump -urrot -p test > test.sql
mysqldump -urrot -p 目标数据库 > 备份文件名.sql #备份命令
mysq -urrot -p test < test.sql
mysql -urrot -p 目标数据库 < 备份文件名.sql 数据表操作
创建表
-- 创建表
-- create table 表名(
-- 字段名 类型 约束,
-- 字段名 类型 约束
-- ...
-- );
-- 简单创建
create table stu(
name varchar(5)
);
-- 完整创建
-- unsigned : ⽆符号
-- primary key : 主键
-- auto_increment : ⾃动增⻓
create table students(
id int unsigned primary key auto_increment,
name varchar(20),
age int unsigned,
height decimal(5,2)
);
-- 查看表信息
-- show create table 表名;
show create table students;
--判断表是否存在,存在时先删除再创建
drop tables students:
if existis:
--
-- 执⾏结果
-- CREATE TABLE `students` (
-- `id` int(10) unsigned NOT NULL AUTO_INCREMENT,
-- `name` varchar(20) DEFAULT NULL,
-- `age` int(10) unsigned DEFAULT NULL,
-- `height` decimal(5,2) DEFAULT NULL,
-- PRIMARY KEY (`id`)
-- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
通过navicat工具获取创表语句的方法
查看表结构和删除表
-- 查看表结构(字段)
-- desc 表名;
desc students;
-- 删除表
-- drop table 表名;
drop table students;数据操作
增加数据
增加一行数据
-- 增加数据
-- 增加⼀⾏数据
-- insert into 表名 values(...)
-- 注意:
-- 1. 数据值需要和表的字段⼀⼀对应(数据个数及数据类型)
-- 2. 主键列是⾃动增⻓,插⼊时需要占位,通常使⽤ 0 或者 default 或者 null 来占位,插⼊成功后以实际数据为准
insert into students values(0, '张三', 28, 1.78);
-- 增加部分值
-- insert into 表名(字段1,...) values(值1,...)
-- 注意: 值的顺序与给出的字段顺序对应
insert into students(name, height) values('李四', 1.68);增加多行数据
--⽅式1: 将单⾏插⼊语句, 多句执⾏, 每句分号隔开
insert into students values(0, '王五', 28, 1.78);
insert into students(name, height) values('赵六', 1.68);
-- ⽅式2: 在插⼊单⾏数据的语法基础上, 将 value 后边的数据进⾏多组化处
理
-- insert into 表名 values(...),(...)...
-- insert into 表名(列1,...) values(值1,...),(值1,...)...
insert into students values(0, '王五1', 29, 1.78),(0, '王五2',
30, 1.78);
insert into students(name, height) values('赵六1', 1.78),('赵六
2', 1.88);修改数据
--update 表名 set 列1=值1,列2=值2...where 条件
--注意:where不能省略,否则会修改整列数据
update students set age=18 where id=5;删除数据
--delete from 表名 where 条件;
--注意:where不能省略,否则会删除全部数据
delete from students where id=5;拓展1:逻辑删除
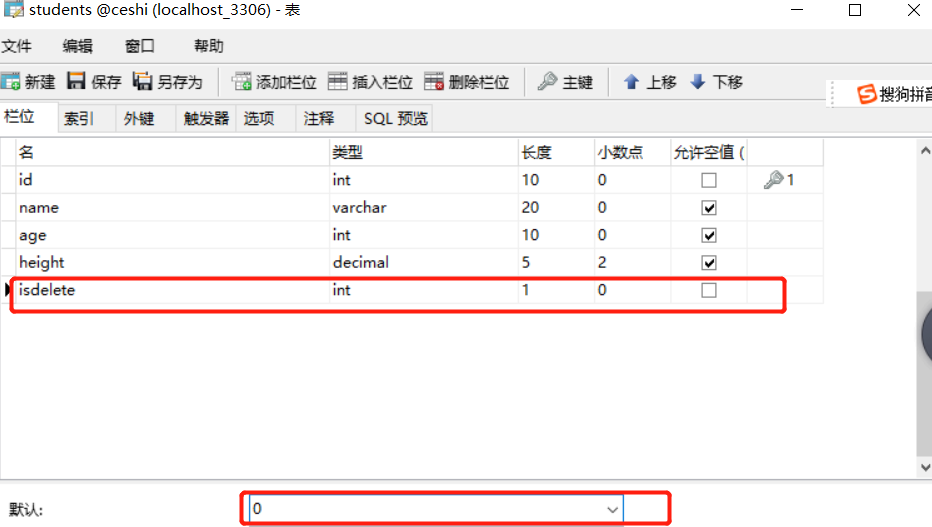
逻辑删除: 对于重要的数据,不能轻易执⾏ delete 语句进⾏删除。因为⼀旦删除,数据⽆法恢复,这时可以进⾏逻辑删除。
1、 给表添加字段,代表数据是否删除,⼀般起名 isdelete,0代表未删除,1代表删除,默认值为0
2、当要删除某条数据时,只需要设置这条数据的 isdelete 字段为1
3、以后在查询数据时,只查询出 isdelete 为0的数据。
--将数据修改为删除状态
update students set isdelete=1 where id=2;
--查询所有isdelete为0的数据
select * from students where isdelete=0;拓展2:其他方法
-- delete from 表名 : 删除所有数据, 但是不重置主键字段的计数
-- truncate table 表名 : 删除所有数据, 并重置主键字段的计数
-- drop table 表名 : 删掉表(字段和数据均不再存在)
delete from students;
truncate table students;
drop table students;查询语句
基本查询
select * from goods; --查询所有数据: select * from 表名
SELECT goodsName,price from goods; --查询部分字段: select 字段名1, 字段名2 from goods;
-- 起字段别名: select 字段名 as '别名' from goods;
select goodsName as '商品名称', price as '价格' from goods;
select goodsName as 商品名称, price as 价格 from goods;
select goodsName 商品名称, price 价格 from goods;
--注意:别名的引号可以省略
-- as 也可以省略
-- 去重: select distinct(字段名) from goods;
-- 效果: 将⽬标字段内重复出现的数据只保留⼀份显示
-- ⼩需求: 显示所有的公司名称
SELECT distinct(company) from goods;起别名的作⽤:
1> 美化数据结果的显示效果
2> 可以起到隐藏真正字段名的 作⽤ 另:除了可以给字段起别名以外, 还可以给数据表起别名(连接查询时使⽤)
条件查询
比较运算符
大于等于:>=
小于等于:<=
不等于:!=或<>
逻辑运算符
与:and
或:or
非:not
-- 需求2: 查询价格等于30并且出⾃并夕夕的所有商品信息
select * from goods;
-- 查询价格等于30 :
select * from goods where price=30;
-- 并且出⾃并夕夕的所有商品信息 : 逻辑运算符(and(与)/or(或)/not(⾮))
-- 注意: 作为查询条件使⽤的字符串必须带引号!
select * from goods where price=30 and company='并夕夕';
-- 补充需求: 查询价格等于30但不出⾃并夕夕的所有商品信息
select * from goods where not company='并夕夕' and price=30;
-- 注意: not 与 and 和 or (左右两边连接条件)不同之处在于, not 只对⾃
⼰右侧的条件有作⽤(右边连接条件)
select * from goods where price=30 and not company='并夕夕';
模糊查询
模糊查询:like和符号%或者_
%:任意多个字符
_ :任意一个字符
注意:
作为查询条件的字符串必须带引号
如果需要控制字符数量,需要使用_,有几个字符就使用几个_
--查询全部一次性口罩的商品信息
--%关键词%:关键词在中间
select *from goods where remark like '%一次性%';
--%关键词:关键词在末尾
select *from goods where remark like '%一次性';
--关键词%:关键词在开头
select *from goods where remark like '一次性%';范围查询
1.非连续范围:in
2. 连续范围:between....and.....(范围必须是从小到大)
--查询所有价格在30-100的商品信息
select * from goods where price between 30 and 100;判断空
1.为空:is null
2.不为空: is not null
注意:在mysql中,只有显示NULL的才为空!
--查询没有描述信息的商品信息
select * from goods where remark is null;
--查询有描述信息的所有商品信息
select * from goods where remark is not null;复杂查询
排序
select * from 表名 order by 列1 asc | desc,列2 asc | desc,...
asc:升序
desc:降序
--查询所有商品信息,按照价格从大到小排序,价格相同时,按照数量由少到多排序
select * from goods order by price desc,count asc;
--默认排序为升序,asc可以省略
select * from goods order by price desc,count;聚合函数
聚合函数:系统提供的一些可以直接用来获取统计数据的函数
--查询商品信息总条数;最高商品价格;最低商品价格;商品平均价格;一次性口罩的总数量
--count(字段):查询总记录数
select count(*) from goods;
select count(remark) from goods;
--max:查询最大值
select max(price) from goods;
select min(price) from goods;
--avg:求平均值
select avg(price) from goods;
select sum(count) from goods where remark like '%⼀次性%';
-- 扩展: 在需求允许的情况下, 可以⼀次性在⼀条 SQL语句中, 使⽤所有的聚
合函数
select count(*), max(price), min(price), avg(price) from goods;分组
-- 需求8: 查询每家公司的商品信息数量
-- 分组: select 字段1,字段2,聚合... from 表名 group by 字段1,字段
-- 说明: group by : 分组
-- 注意:
-- 1> ⼀般情况, 使⽤哪个字段进⾏分组, 那么只有该字段可以在 * 的位置处
使⽤, 其他字段没有实际意义(只要⼀组数据中的⼀条)
-- 2> 分组操作多和聚合函数配合使⽤
select count(*) from goods group by company;
select * from goods;
select company, count(*) from goods group by company;
-- 说明: 其他字段没有实际意义(只要⼀组数据中的⼀条)
select price, count(*) from goods group by company;
-- 扩充: 分组后条件过滤
-- 说明: group by 后增加过滤条件时, 需要使⽤ having 关键字
-- 注意:
-- 1. group by 和 having ⼀般情况下需要配合使⽤
-- 2. group by 后边不推荐使⽤ where 进⾏条件过滤
-- 3. having 关键字后侧可以使⽤的内容与 where 完全⼀致(⽐较运算符/逻
辑运算符/模糊查询/判断空)
-- 3. having 关键字后侧允许使⽤聚合函数
-- where 和 having 的区别:
- where 是对 from 后⾯指定的表进⾏数据筛选,属于对原始数据的筛选
-- having 是对 group by 的结果进⾏筛选
-- having 后⾯的条件中可以⽤聚合函数,where 后⾯不可以分页查询
-- 需求9: 查询当前表当中第5-10⾏的所有数据
-- 分⻚查询: select * from 表名 limit start,count
-- 说明: limit 分⻚; start : 起始⾏号; count : 数据⾏数
-- 注意: 计算机的计数从 0 开始, 因此 start 默认的第⼀条数据应该为 0,
后续数据依次减1
-- 过渡需求: 获取前 5 条数据
select * from goods limit 0, 5;
-- 注意: 如果默认从第⼀条数据开始获取, 则 0 可以省略!
select * from goods limit 5;
-- 需求:
select * from goods limit 4, 6;
-- 扩展 1: 根据公式计算显示某⻚的数据
-- 已知:每⻚显示m条数据,求:显示第n⻚的数据
-- select * from 表名 limit (n-1)*m, m
-- 示例: 每⻚显示 4 条数据, 求展示第 2 ⻚的数据内容
select * from goods limit 0, 4; -- 第1⻚(有数据)
select * from goods limit 4, 4; -- 第2⻚(有数据)
select * from goods limit 8, 4; -- 第3⻚(有数据)
select * from goods limit 12, 4; -- 第4⻚(⼀共 12 条数据, 每⻚显示
4 条, 没有第 4 ⻚数据)
-- 扩展 2: 分⻚的其他应⽤
-- 需求: 要求查询商品价格最贵的数据信息
select * from goods order by price desc limit 1;
-- 进阶需求: 要求查询商品价格最贵的前三条数据信息
elect * from goods order by price desc limit 3;连接查询

内连接
内连接:select * from 表1 inner join 表2 on 表1.列=表2.列
显示效果:两张表中有对应关系的数据都会显示出来,没有对应关系的均不显示。
select * from goods
inner join category on goods.typeId=category.typeId;
-- 扩充: 给表起别名(1> 缩短表名利于编写 2> ⽤别名给表创建副本)
select * from goods go
inner join category ca on go.typeId=ca.typeId;
-- 扩展: 内连接的另⼀种写法(旧式写法)
-- select * from 表1, 表2 where 表1.字段名=表2.字段名;
select * from goods, category where
goods.typeId=category.typeId;左连接/右连接
左连接: select * from 表1 left join 表2 on 表1.列=表2.列
注意: 如果要保证⼀张数据表的全部数据都存在, 则⼀定不能选择内连接,
可以选择左连接或右连接
说明:以 left join 关键字为界, 关键字左侧表为主表(都显示), ⽽关键字右侧
的表为从表(对应内容显示, 不对应为 null)
右连接: select * from 表1 right join 表2 on 表1.列=表2.列
说明:以 right join 关键字为界, 关键字右侧表为主表(都显示), ⽽关键字左侧
的表为从表(对应内容显示, 不对应为 null)
-- 需求2: 查询所有商品信息,包含商品分类
select * from goods go
left join category ca on go.typeId=ca.typeId;
-- 扩充需求: 以分类为主展示所有内容(以哪张表为主表, 显示结果上是有区别
的!)
select * from category ca
left join goods go on ca.typeId=go.typeId;
-- 需求3: 查询所有商品分类及其对应的商品的信息
select * from goods go
right join category ca on go.typeId=ca.typeId;
-- 扩充需求: 查询所有商品信息及其对应分类信息
select * from category ca
right join goods go on ca.typeId=go.typeId;















 2547
2547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









