







模型优点
1.更新Block(bneck)
2.使用NAS搜索参数(Neural Architecture Search)
3.重新设计耗时层结构
新的改变
相比于V2 提升了3.2%,更准确,更高效
注意力机制
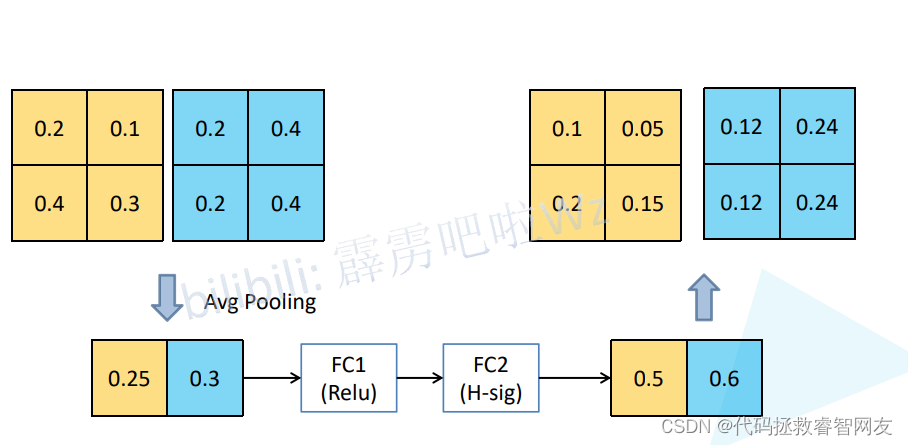
假设特征矩阵的Cannel=2,进行平均池化操作(针对每一个cannel求均值),得到一个有两个元素的特征向量,经过两个全连接层得到输出,针对FC1:节点个数是输入特征矩阵cannel的1/4,跟的是RELU激活函数,针对FC2:节点个数和输入特征矩阵一致,跟的是H-sig激活函数,之后得到两个元素的特征向量,每一个元素对应输入特征矩阵每一个cannel所对应的权重,元素的值与原特征矩阵每一个元素相乘(用0.5*(0.2,0.1,0.4,0.3)),第二个元素类似
更新Block
加入了SE模块(注意力机制)
更新了激活函数

首先是1X1的卷积层进行升维处理,后跟BN和RELU6激活函数,紧接着是3X3的DW卷积(卷积核个数=输入的深度=输出的深度),后跟BN和RELU6激活函数,再进行1X1的卷积层进行降维,后面只跟了RELU6激活函数,没有BN
捷径分支条件:stride=1且input_c=output_c
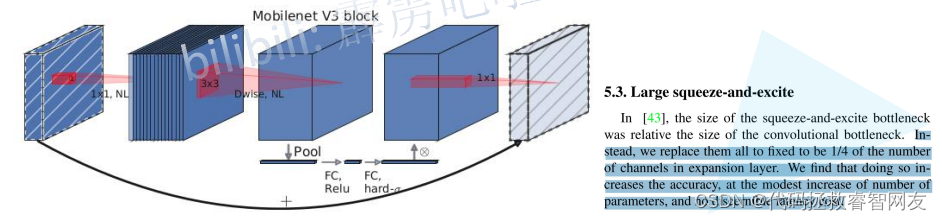
更新了激活函数:NL(非线性激活函数,笼统概述),每层激活函数不同
首先是1X1的卷积层进行升维处理,后跟BN和非线性激活函数,紧接着是3X3的DW卷积(卷积核个数=输入的深度=输出的深度),后跟BN和非线性激活函数,再经过SE模块(注意力机制模块),再经过1X1的卷积进行降维处理,没有跟激活函数和BN
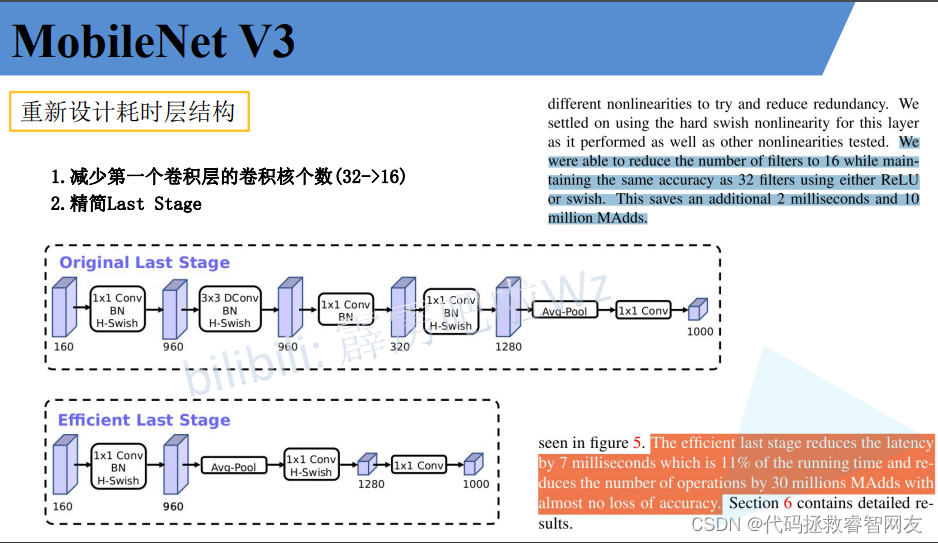
重新设计耗时层结构
1.减少第一个卷积层的卷积核个数(32->16),实验表明计算时间相同,但是参数数量变少了
2.精简Last Stage
重新设计激活函数
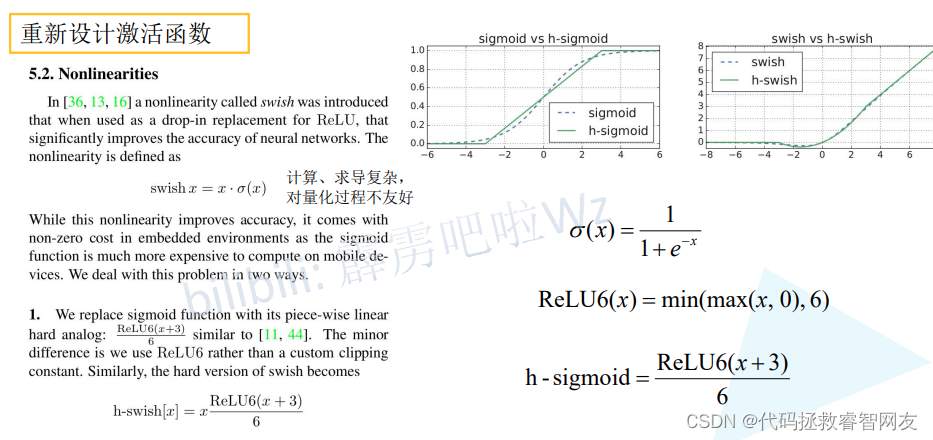
缺点:计算、求导复杂,对量化过程不友好(量化就是将模型部署到硬件设备上)
针对问题提出了以下激活函数
H-sigmoid
H-swish
V3-Large网络结构
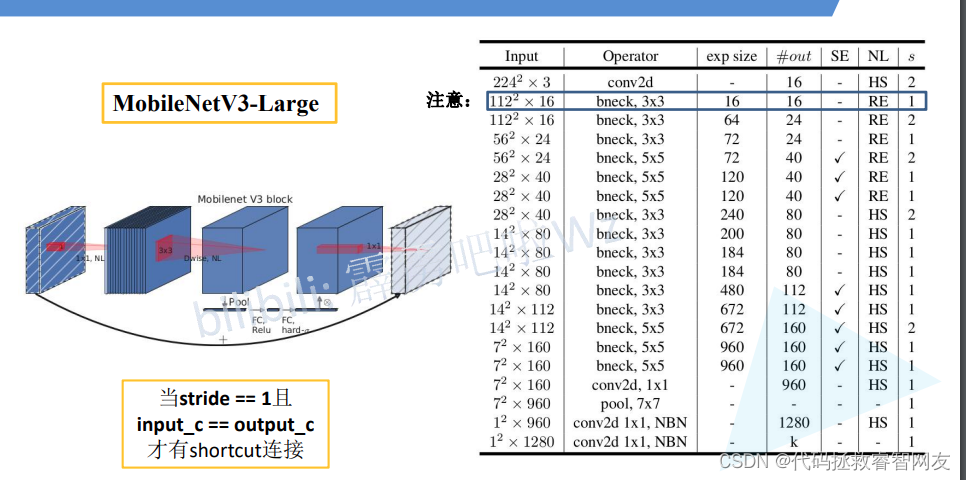
第一个倒残差结构的卷积核大小变为16,优化
NBN:不使用BN结构
后两个卷积=全连接层















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









