







背景
本文将以雪球网为例,教你快速爬取你要的数据。不论是不懂爬虫的python玩家、还是刚入坑爬虫新人,下面这方法都可大大提升一些简单爬虫的开发效率。大佬就见笑了。
另,如下方法,仅对无过多反爬机制的网页有效。
流程
1、进入你想要爬取的网页,找个空白的地方,右键->“检查”。然后如下面流程,找到我们需要的接口。一般来说,像这种网页类似于Excel结构的数据,一般都是采用动态加载,可使用此方法。
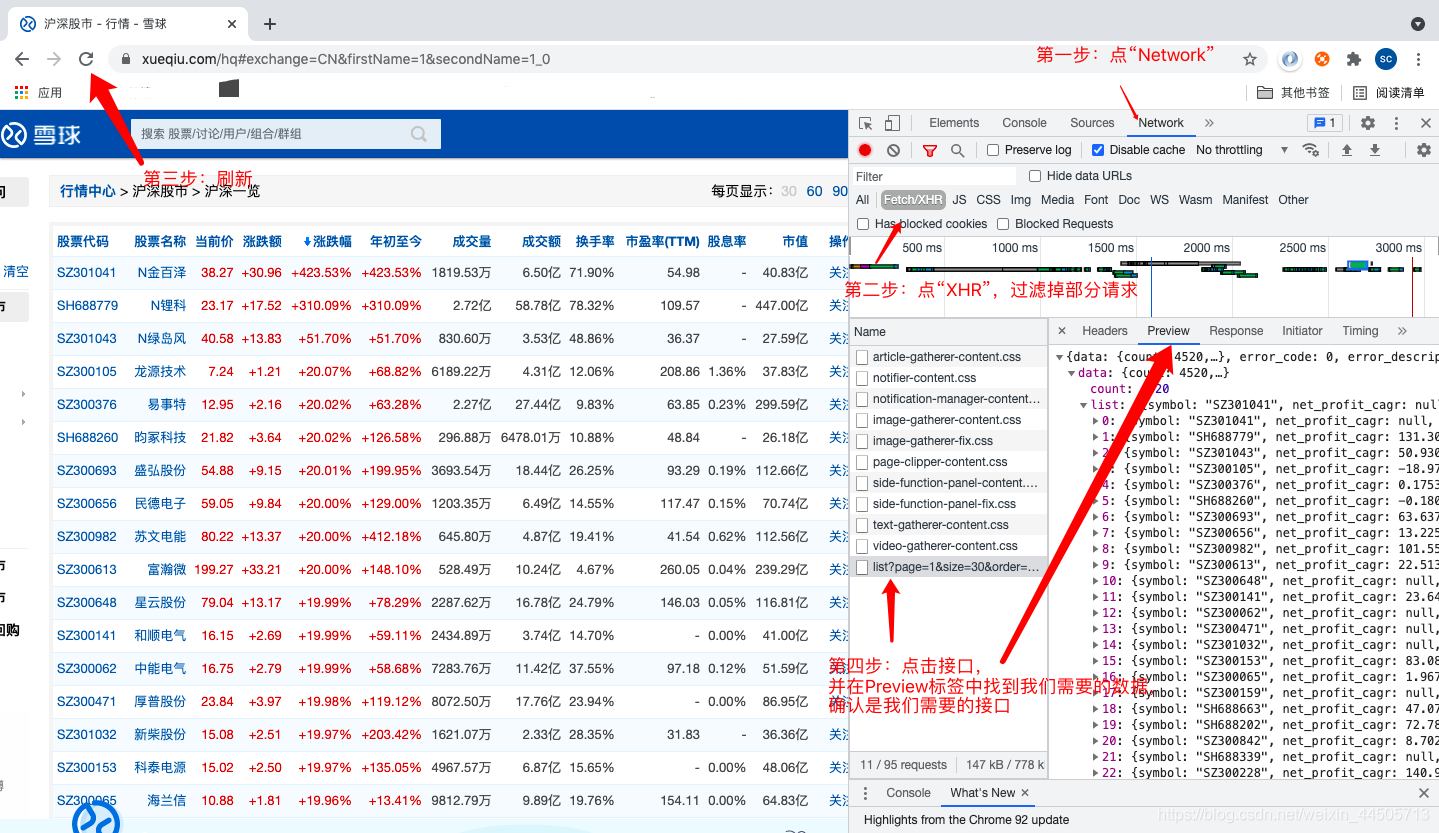
2、选择需要的接口,如下图,copy as cURL。
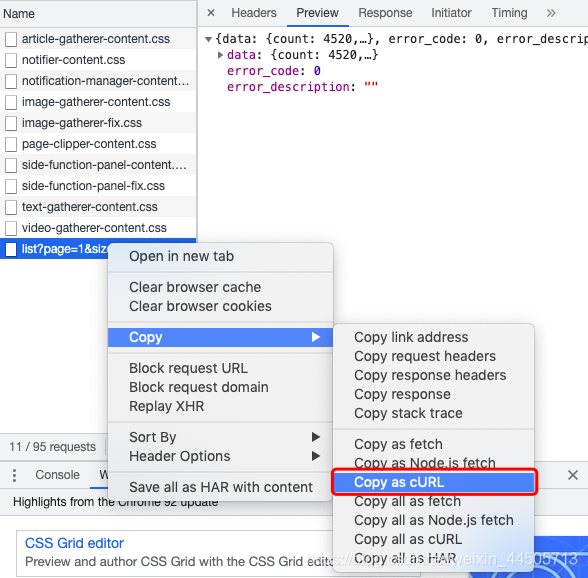
3、可以粘贴到Terminal中看看(红框部分),其实就是个curl命令,可以用来发送一些url请求,有点像python中的requests动作。这里可以在本地的Terminal中执行。如果是window的话,有copy as cURL(cmd)的选项,复制完去cmd窗口执行也一样。下面部分就是请求的结果,即我们需要的数据。
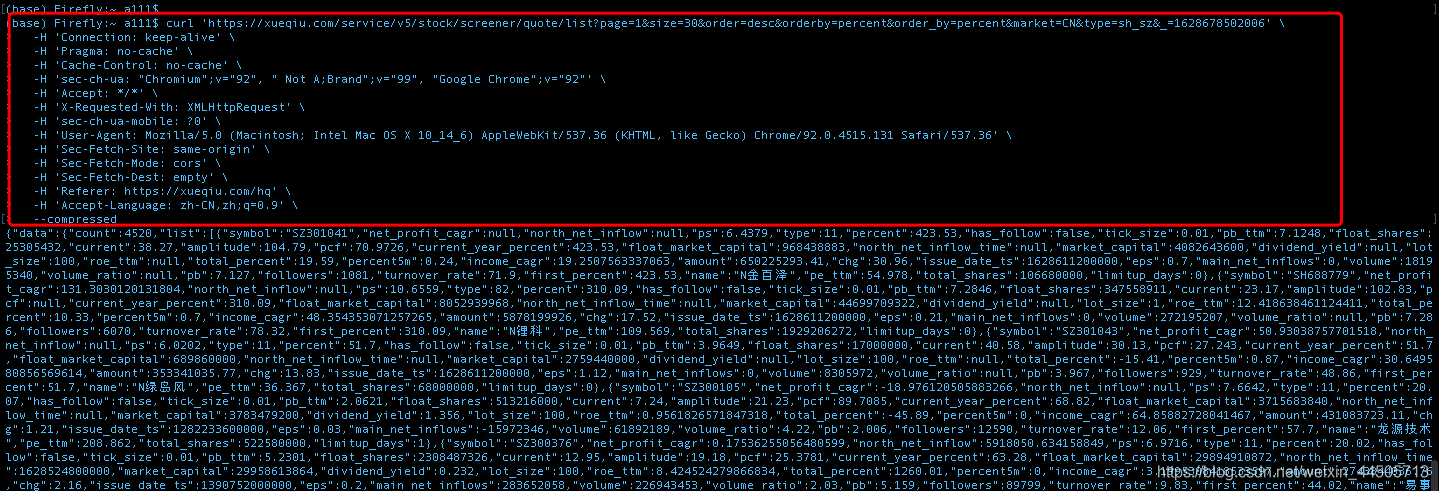
4、神器: curl转化成python语法链接:代码转换链接。如下图,复制粘贴,就可以生成了我们需要的python代码,太无敌了。
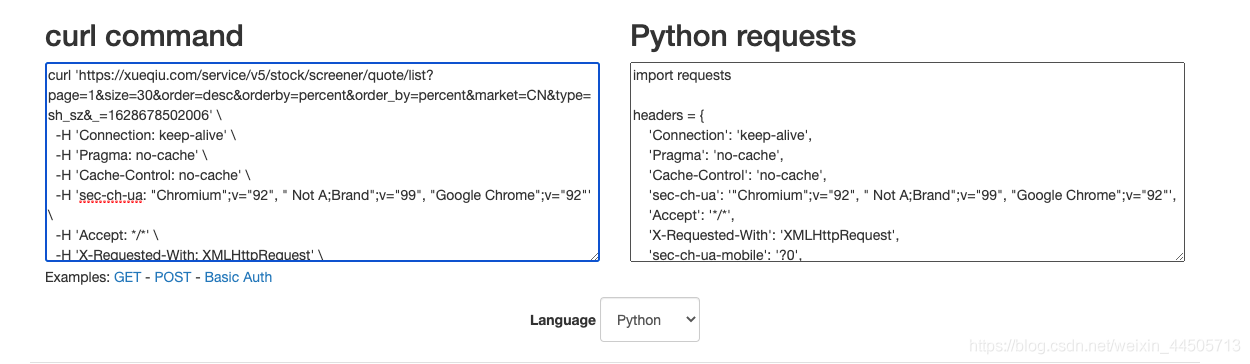
5、将生成的代码复制到编译器,可修改data里面的参数,再执行,就能以json的形式,获得我们需要的数据。
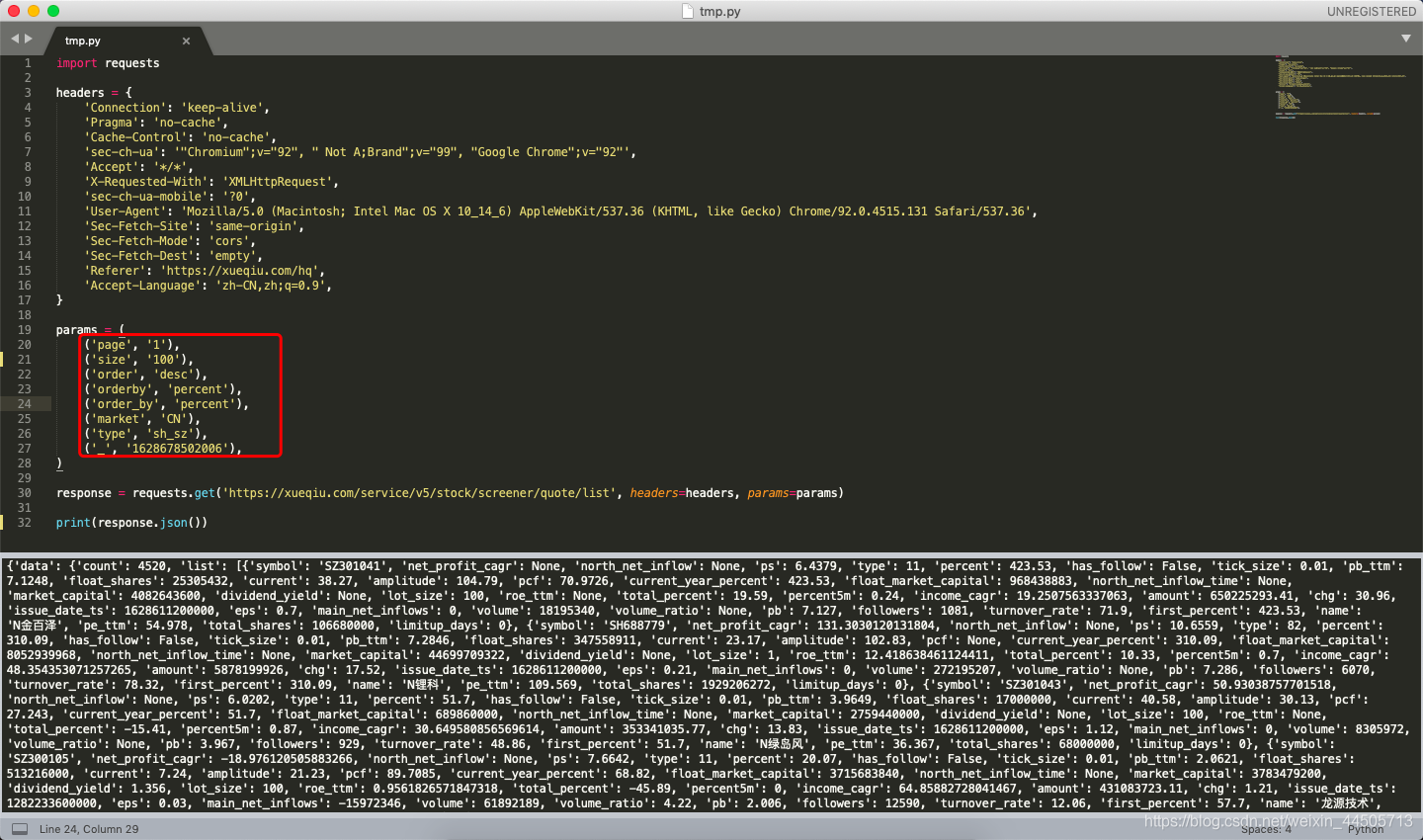
至此,over!














 390
390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









