







ElasticSearch概述
ElasticSearch是一个分布式、FESTful风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例,作为ElasticSearch的核心,它集中存储数据,帮助发现意料之外以及意料之中的情况,ElasticSearch的底层是开源库Lucene,但是,我们没法直接用lucene,必须自己写代码去调用它的接口,Elastic是Lucene的封装,提供了REST API,开箱即用。
ELK:ElastSearch、Logstash、Kibana
Elasticsearch 的 solr区别
1、es基本是开箱即用(解压就可以用!),非常简单。Solr安装略微复杂一丢丢!
2、Solr利用Zookeeper进行分布式管理,而 Elasticsearch自身带有分布式协调管理功能。3、Solr支持更多格式的数据,比如SON、XML、CSv,而Elasticsearch 仅支持json文件格式。
4、Solr官方提供的功能更多,而Elasticsearch本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑~!
5、Solr查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;。ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
。Solr是传统搜索应用的有力解决方案,但Elasticsearch更适用于新兴的实时搜索应用。
6、Solr比较成熟,有÷个更大,更成熟的用户、开发和贡献者社区,而Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。
ES安装
声明:jdk1.8 最低要求!ES客户端、界面。
ES7.6.1下载:https://blog.csdn.net/weixin_46024189/article/details/106736907
下载完成之后解压,进入bin,运行elasticsearch.bat文件。访问127.0.0.1:9300,

安装成功,
目录结构

bin 启动文件
config 配置文件
log4j2 日志配置文件
jvm.options java 虚拟机相关配置
elasticsearch.yml elasticsearch配置文件 默认9200端口,跨域
lib 相关jar包
logs 日志
modules 功能模块
plugins 插件,ik
下载ES客户端界面(ES head):https://search.gitee.com/?q=ElasticSearch+head+&skin=rec&type=repository
要运行客户端界面,必须要要有nodejs;需要先学习前端是哦
解压,进入文件主目录,cmd,运行cnpm install,之后再启动项目npm run start

运行成功,
连接测试,解决跨域问题:
打开es的elasticsearch.yml配置文件,添加跨域配置:;
http.cors.enabled: true
http.cors.allow-origin: “*”
重新连接

连接成功。
了解ELK
ELK是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。市面上也被成为Elastic Stack。其中Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es,Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等 )。Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。
Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Ktband ,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板( dashboard )实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
安装Kibana
下载地址:https://blog.csdn.net/qq_42449963/article/details/109357234
下载完成,解压即可,然后运行进入bin文件运行Kibana.bat文件

运行成功!
汉化需要修改Kibana.yml里面加入i18n.locale: “zh-CN”

ES讲解
ES是面向文档,关系行数据库和ES客观的对比,一切都是JSON
| Relaational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(table) | types |
| 行(rows) | documents |
| columns | fields |
ES(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又可以包含多个文档(行),每个文档中又可以包含多个字段(列)
物理设计
es在后台把每个索引划分成多个分片,每分分片都可以在集群中的不同服务器迁移
逻辑设计
每个索引类型中,包含多个文档,比如文档1、文档2.当我们索引一篇文档时,可以通过这样的一个顺序找到它:索引–>类型–>文档ID。通过这个组合我们就可以索引到某个具体的文档,注意:ID不必是证书,实际上它是字符串。
文档(就是一条条数据)
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中;
文档有几个重要属性:·自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value !可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的!灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么么蛾子。
索引(数据库)
索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
一个集群至少有一个节点,而一个节点就是一个ES进程,节点可以又多个索引默认的,如果传教索引,那么索引将会有五个分配(primary shard,又称为主分片)构成的,每一个主分片会有一个副本(replica shard),又称为复制分片。
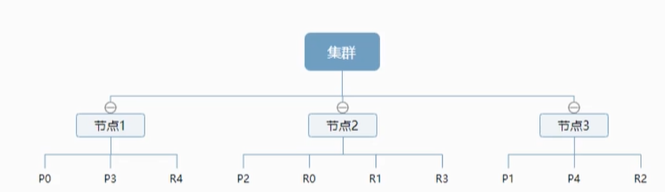
上图有三个节点的集群,可以看到主分片和对饮的复制分片都不会在同一节点内,这样有理由某个节点挂掉之后,倒排索引的结构是的es在不扫描全部文档的群看下,就会告诉你哪些文档包含特定的关键字。
倒排索引
ES使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。为了创建倒排索引。我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表。然后列出每个词条出现在哪个文档。
ES的索引和Lucene的索引对比
在ES中,索引(库)频繁被使用,这就是术语的使用。在ES中,索引被分为多个分片,每片时一个Lucene的索引。所以以恶搞ES索引是由多个Lucene索引组成的。。索引是指es的索引
IK分词器
分词︰即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱学习"会被分为"““我"∵爱”"学"∵"习”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法:ik_smart和ik_max_word,其中 ik_smart为最少切分,ik_max_word为最细粒度划分!一会我们测试 !
安装
下载地址:https://blog.csdn.net/qq_42449963/article/details/109357299
下载下来放入到ES目录下的plugins目录下即可 接着重启ES,观察

IK分词器已被加载进来,
elasticsearch-plugin指令
elasticsearch-plugin list

IK分词器插件安装成功
使用kibana测试:

对于一些特殊的分词词组,自己取的专有名词,需要自己加入到IK分词器中,需要编写自己的dic文件,然后添加到配置文件中。

重启ES,查看过程,IK分词器和ty.dic自定义的词组加载进来。

自定义词组已经可以组合展示

RAST风格
一种软件架构风格,不是标准,只是提供了一组设计原则和约束条件。主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更加简洁,更有层次,更易于实现缓存等机制。
基本指令说明
| method | url地址 | 描述 |
|---|---|---|
| put | local host:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| post | local host:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| post | local host:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| deletet | local host:9200/索引名称/类型名称/文档id | 删除文档 |
| get | local host:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| post | local host:9200/索引名称/类型名称/_search | 查询所有数据 |
测试
创建一个索引 PUT
put /索引名称/文档类型/id


字段类型
字符串类型:test、keyword
数值类型:long、integer、short、byte、double、float、half float、scaled float
日期类型:date
te布尔类型:boolean
二进制类型:binary
指数字段类型 PUT

获取信息 GET

默认名称


如果没有的文档字段没有指定,那么es就会给我们默认配置字段类型。
扩展:通过get _cat/可以查看es当前配置的很多信息!

修改POST


删除 delete

文档的基本操作(重点)
基础操作
添加数据
PUT /ty/user/1
{
"name":"学习ES",
"age":22,
"desc":"学不死,就接着学",
"tigs":["学习","Java","编程"]
}

获取数据 GET

更新PUT

推荐使用POST /索引名称/ _update 
_update 更新方式

搜索
简单的条件查询,可以根据默认的映射规则,产生基本的查询

复杂操作 搜索
简单查询

select(排序、分页、高亮、模糊查询、精准查询!)
查询的参数体使用Json格式
query和match

hit

可以通过score分数的值来查看谁最符合结果。
_score
对于输出结果进行过滤:例如:只需要名字name和年龄age

排序 sort

分页查询(from 从第几条开始,size一页多少条数据)

布尔值查询 精确查询
must 相当于and

should 相当于or

must_not(not)

filter

gt 大于 gte 大于等于 lt 小于 lte小于等于
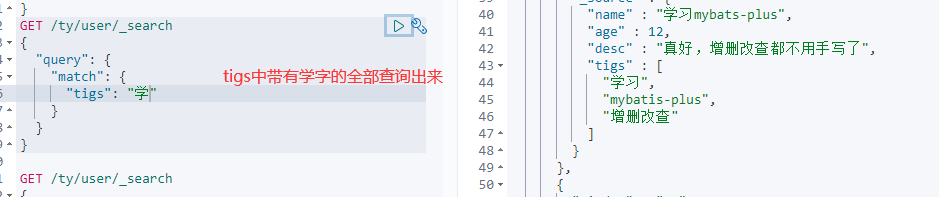

精确查找
term查询时直接通过倒排索引指定的词条进行精确查询
关于分词:
term是直接查询精确的
match回使用分词器解析!(先分析文档,然后会通过分析的文档进行查找)
standard 可以被拆分 keyword 不可以被拆分

所以keyword类型的字段不会被分词器解析
多值匹配的精确查询

高亮查询


MySQL也可以做,只是它的效率比较低
匹配
按照条件查询
精确匹配
区间范围匹配
匹配字段过滤
多条件查询
高亮查询
SpringBoot集成ES
配置基本项目
问题:一定要保证 导入的依赖和本地的es版本一致

配置类
@Configuration
public class ElasticSearchConfig {
// beans id=restHighLevelClient class = RestHighLevelClient
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost",9200,"http")
)
);
return restHighLevelClient;
}
}
索引操作
//索引的创建 Request
@Test
void testCreateIndexRequest() throws IOException {
//创建索引请求
CreateIndexRequest request = new CreateIndexRequest("ty_index");
//执行请求
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(response);
}
//获取索引,只能判断是否存在
@Test
void testGetExistsIndexRequest() throws IOException {
GetIndexRequest index = new GetIndexRequest("ty_index");
boolean exists = client.indices().exists(index, RequestOptions.DEFAULT);
System.out.println(exists);
}
//删除索引
@Test
void testDeleteIndexRequest() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("ty_index");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
文档操作
//创建文档
@Test
void testAddDocument() throws IOException {
User user = new User("ty", 3); //创建对象
IndexRequest request = new IndexRequest("ty_index");//创建请求
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
//将数据放入请求中
request.source(JSON.toJSONString(user), XContentType.JSON);
IndexResponse index = client.index(request, RequestOptions.DEFAULT); //执行请求
System.out.println(index.toString());
System.out.println(index.status()); //对应命令返回
}
//获取文档 判断是否存在, 保证效率
@Test
void testIsExists() throws IOException {
GetRequest request = new GetRequest("ty_index", "1");
//不获取上下文的_source
request.fetchSourceContext(new FetchSourceContext(false));
request.storedFields("_none");
boolean exists = client.exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
//获取文档的信息
@Test
void testGetDocument() throws IOException {
GetRequest request = new GetRequest("ty_index","1");
GetResponse documentFields = client.get(request, RequestOptions.DEFAULT);
System.out.println(documentFields.getSourceAsString());
System.out.println(documentFields);
}
//更新文档的信息
@Test
void testUpdateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("ty_index", "1");
updateRequest.timeout("1s");
User user = new User("ty---", 22);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse);
System.out.println(updateResponse.status());
}
//删除文档
@Test
void testDeleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("ty_index","1");
request.timeout("1s");
DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
System.out.println(deleteResponse);
System.out.println(deleteResponse.status());
}
//批量插入
@Test
void testBulkDocument() throws IOException {
BulkRequest request = new BulkRequest();
request.timeout();
ArrayList<User> list = new ArrayList<>();
list.add(new User("ty1",1));
list.add(new User("ty2",2));
list.add(new User("ty3",1));
list.add(new User("ty4",2));
list.add(new User("ty5",1));
list.add(new User("ty6",2));
for (int i = 0; i < list.size(); i++) {
//批量删除和更新修改这里即可
request.add(new IndexRequest("ty_index")
.id(""+(i+1))
.source(JSON.toJSONString(list.get(i)),XContentType.JSON));
}
BulkResponse bulk = client.bulk(request, RequestOptions.DEFAULT);
System.out.println(bulk.toString());
System.out.println(bulk.hasFailures()); //是否失败
}
//查询
@Test
void testSearchDocument() throws IOException {
SearchRequest searchRequest = new SearchRequest("ty_index");
//构建搜索查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// termQuery 精确查询
//matchAllQuery 查询所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "ty1");
//MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
SearchSourceBuilder query = searchSourceBuilder.query(termQueryBuilder);
searchRequest.source(searchSourceBuilder);
query.timeout(new TimeValue(60,TimeUnit.SECONDS));
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(search.getHits()));
System.out.println("------------------");
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
System.out.println("------------------");
for (SearchHit hit : search.getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
实战
爬虫
数据如何获取:数据库获取、消息队列、爬虫
爬取数据:获取请求返回的页面信息,筛选自己需要的即可
jsoup包!
前后端分离
搜索高亮
京东案例:















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









