







现在流行的监控框架和技术有很多,这里介绍和搭建一套监控体系,所使用的是prometheus监控采集监控指标数据,将数据保存到时序数据库中,使用grafana做监控指标数据可视化,告警使用的是alertmanager。接下来就一起来搭建一下这个监控系统吧。
实践环境:
| 主机名 | 主机ip | 用途 |
| master | 192.168.136.3 | 监控节点 |
| slave1 | 192.168.136.4 | 监控节点 |
| slave2 | 192.168.136.5 | 监控节点 |
这一套的监控体系可以有两种部署模式,一个是物理机上部署,另一个是容器化部署的模式;容器部署需要有容器部署的经验,对docker或者k8s有一定的了解,接下来两种模式都会部署介绍。
物理部署模式
这个就是直接在物理机上部署,先到官网上找到这个安装包,官网地址这里给了这个Download | Prometheus
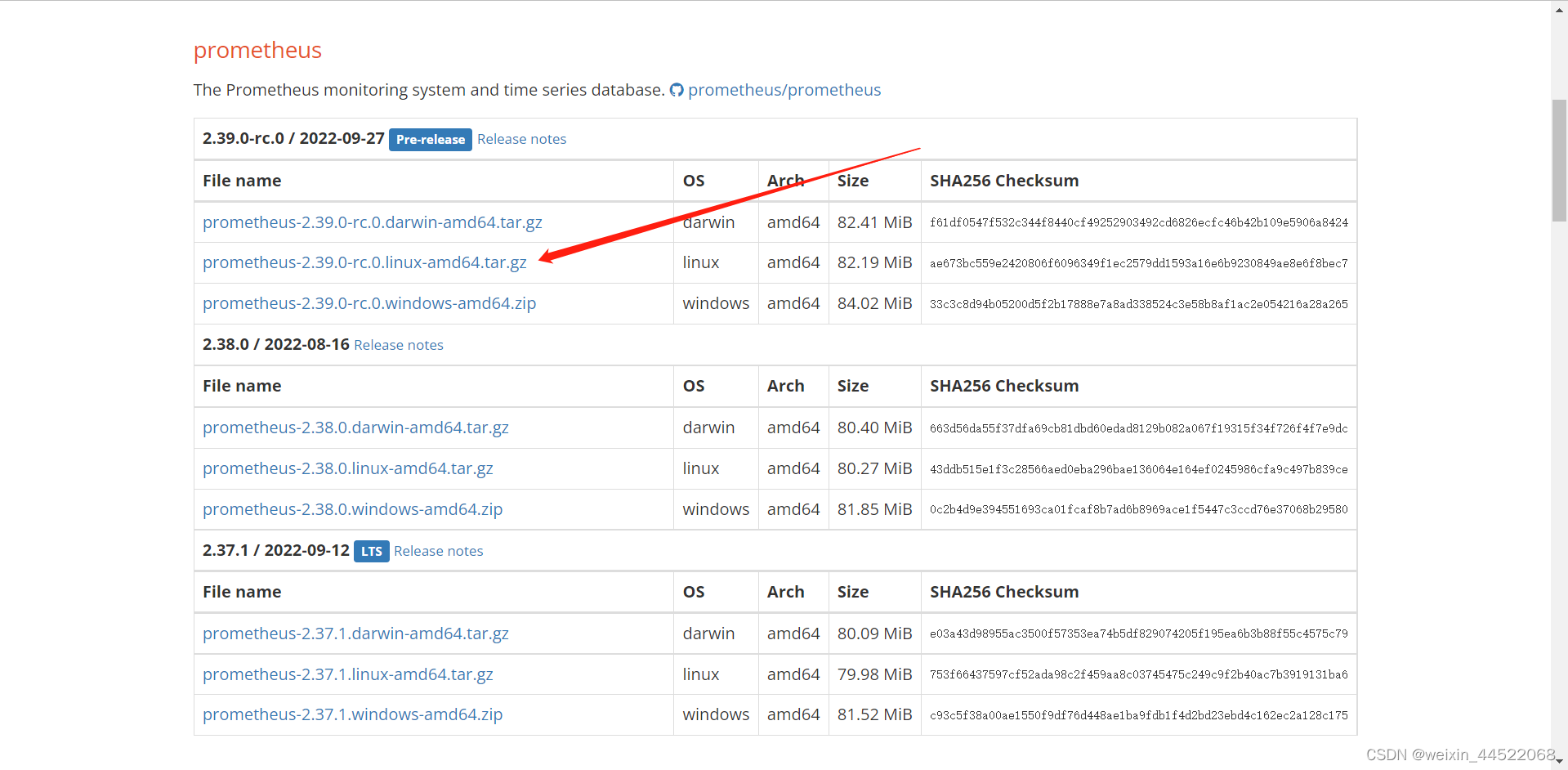

下载完成后上传到服务器上解压就可以用了,我们需要关注这个prometheus.yml文件,我们配置的这个监控源是在这个文件上区配置的。
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["10.0.20.10:9090"]
- job_name: "node"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["10.0.20.10:9100"]
global是全局的配置,这里默认数据采集的时间是15s;
alert是作为告警的模块,可以配置短信、邮件等的告警,具体的告警实现要结合这个rule_files来实现;
scrape_configs就是我们要配置的监控采集的指标源,通过job_name来对采集的数据源进行分组,这里的监控的话,要根据这个exporter对用的端口号来填写。
这里还没有安装exporter,但是prometheus会有一个自带的监控,端口就是9090,先将这个填入到配置里面,修改targets,可以参考上面的代码块的配置;接下来启动prometheus
nohup ./prometheus>>prometheus.log 2>&1 &访问主机+端口号,默认是9090端口号

选择这个查看当前自定义的标签分组情况
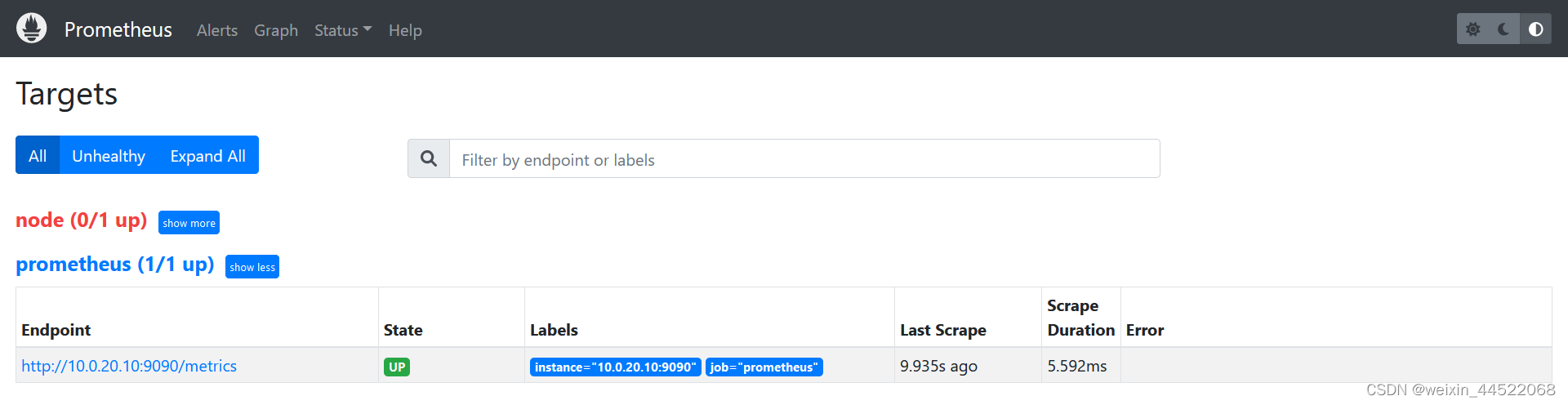 这里的prometheus已经安装完成了,监控的指标数据会定时采集到prometheus的时序数据库中。
这里的prometheus已经安装完成了,监控的指标数据会定时采集到prometheus的时序数据库中。
安装配置node_exporter
node_exporter是采集监控的指标,这里的主要是采集主机层次的指标监控,主要是cpu、内存、网络、磁盘等数据,主要是s层监控使用的,还有很多其他的exporter,安装方式大同小异,下载地址这里提供的官方的下载渠道Download | Prometheus和Exporters and integrations | Prometheus可以根据自己的需求来下载安装。下载的node_exporter解压启动就可以了,默认的端口号是9100
nohup ./node_exporter>>node_export.log 2>&1 &配置prometheus.yml文件,将这个node监控起来
- job_name: "node"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["10.0.20.10:9100"]重启一下prometheus使配置生效
ps -ef |grep prometheus
kill 进程号
nohup ./prometheus>>prometheus.log 2>&1 &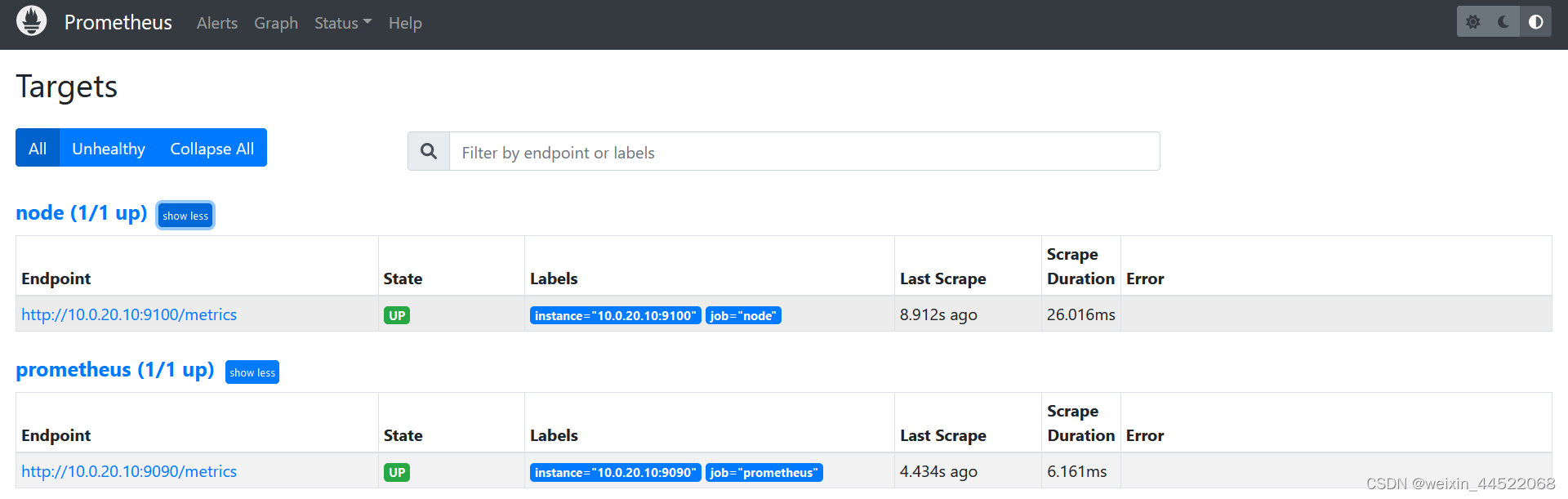
到这里监控方面的数据,我们已经获取到了,接下来就是配置告警和将监控采集到的数据进行可是化的操作。接下我们先搭建grafana来做数据可视化。
安装grafana配置数据源
grafana主要使用来在数据可视化面板的,里面有很多这个图标模板可以选择,能比较好的展示了监控到的情况。这里提供官方的下载连接Download Grafana | Grafana Labs

默认情况下使不需要修改,进入bin目录启动grafana-server,启动后的访问端口是3000,默认的登录用户和密码是admin/admin,登录后再去此需改登录密码,因为正常的生产环境的是不允许使用这种弱密码的
登录之后添加prometheus数据源
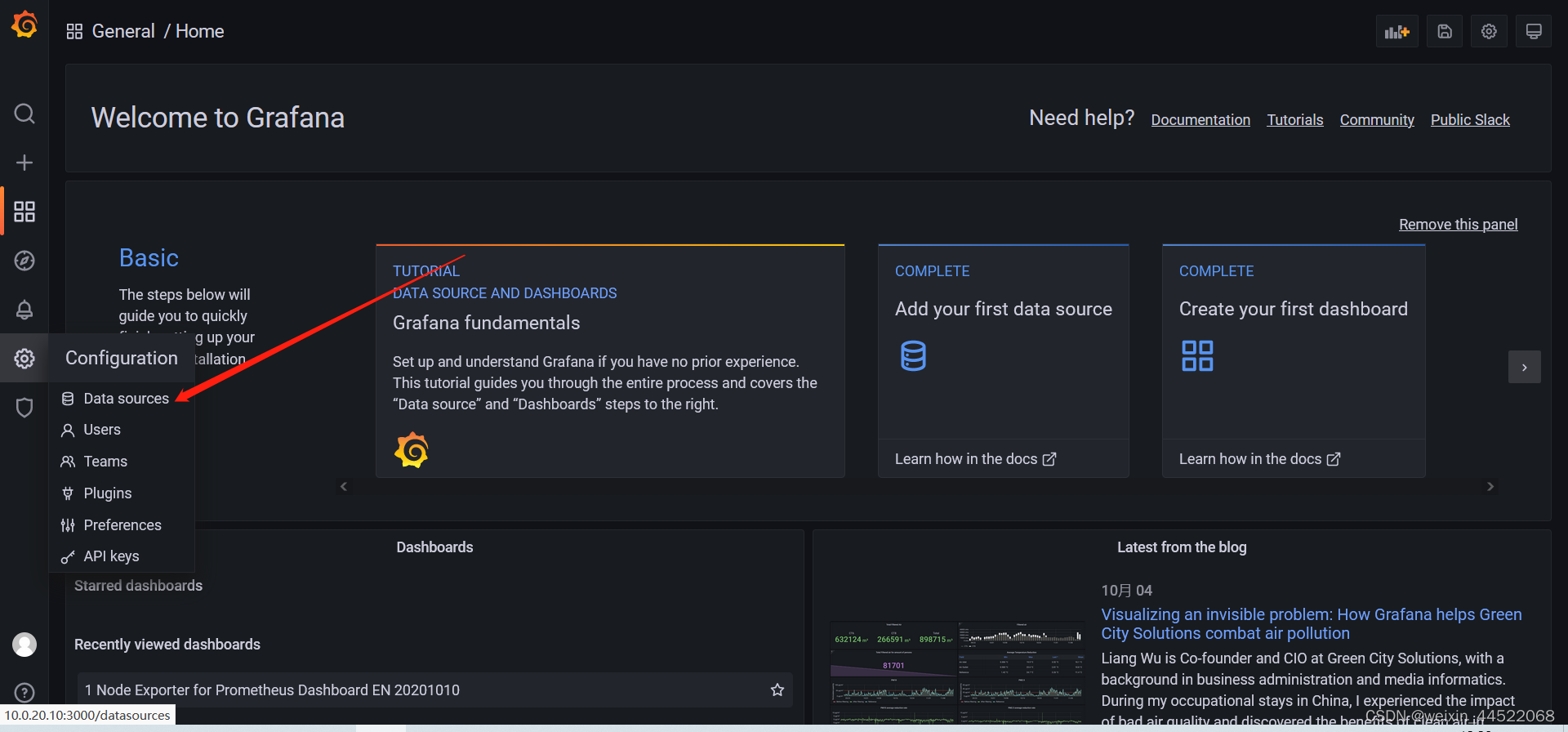 没有其他的加密操作什么的,直接填写prometheus的url地址就可以了,save保存一下
没有其他的加密操作什么的,直接填写prometheus的url地址就可以了,save保存一下
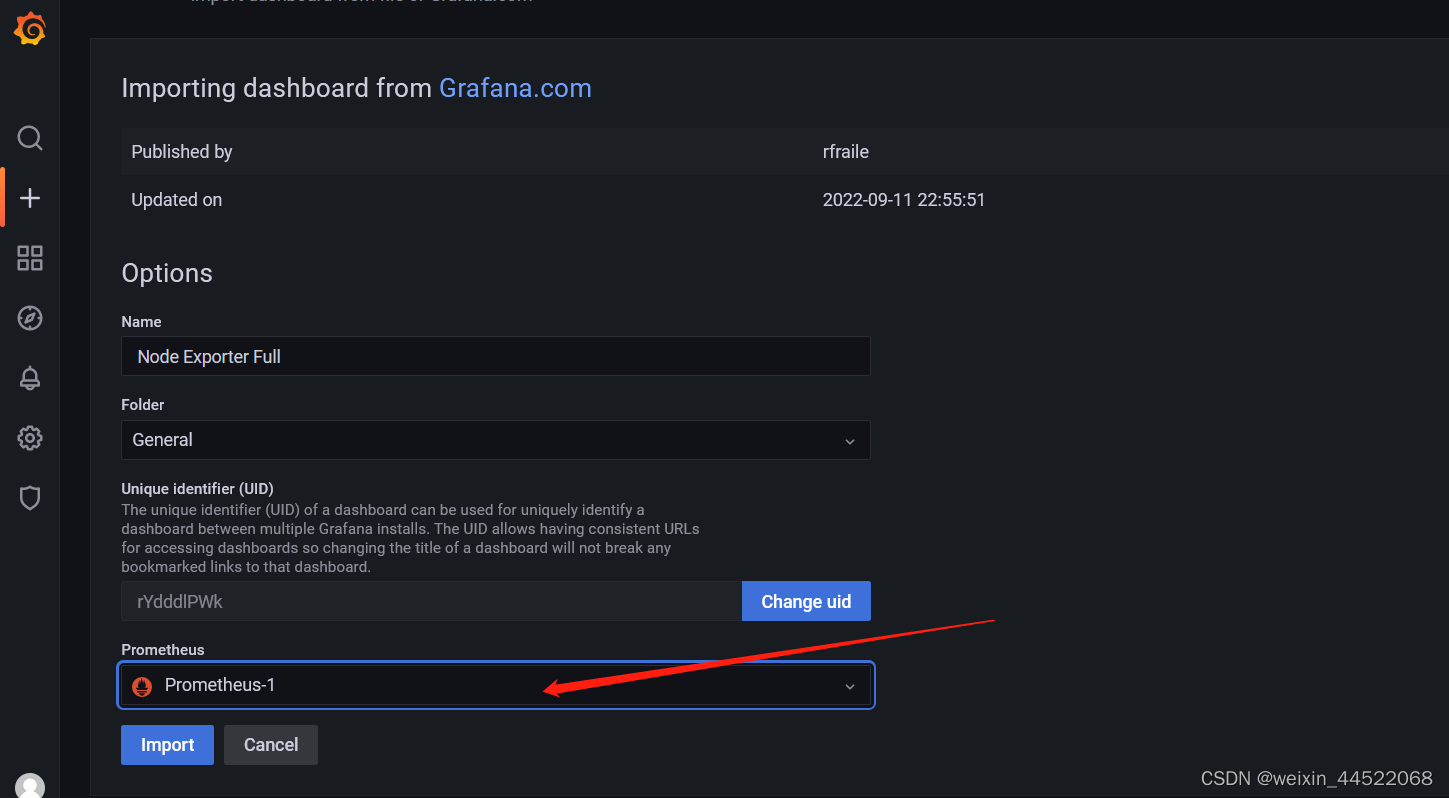
 添加prometheus的可视化面板,这里的面板我们可以通过官网去找,也可以自定义,前提是自己能懂怎么去配置,不懂的话直接就用官网上面的模板就好,模板地址是Dashboards | Grafana Labs
添加prometheus的可视化面板,这里的面板我们可以通过官网去找,也可以自定义,前提是自己能懂怎么去配置,不懂的话直接就用官网上面的模板就好,模板地址是Dashboards | Grafana Labs
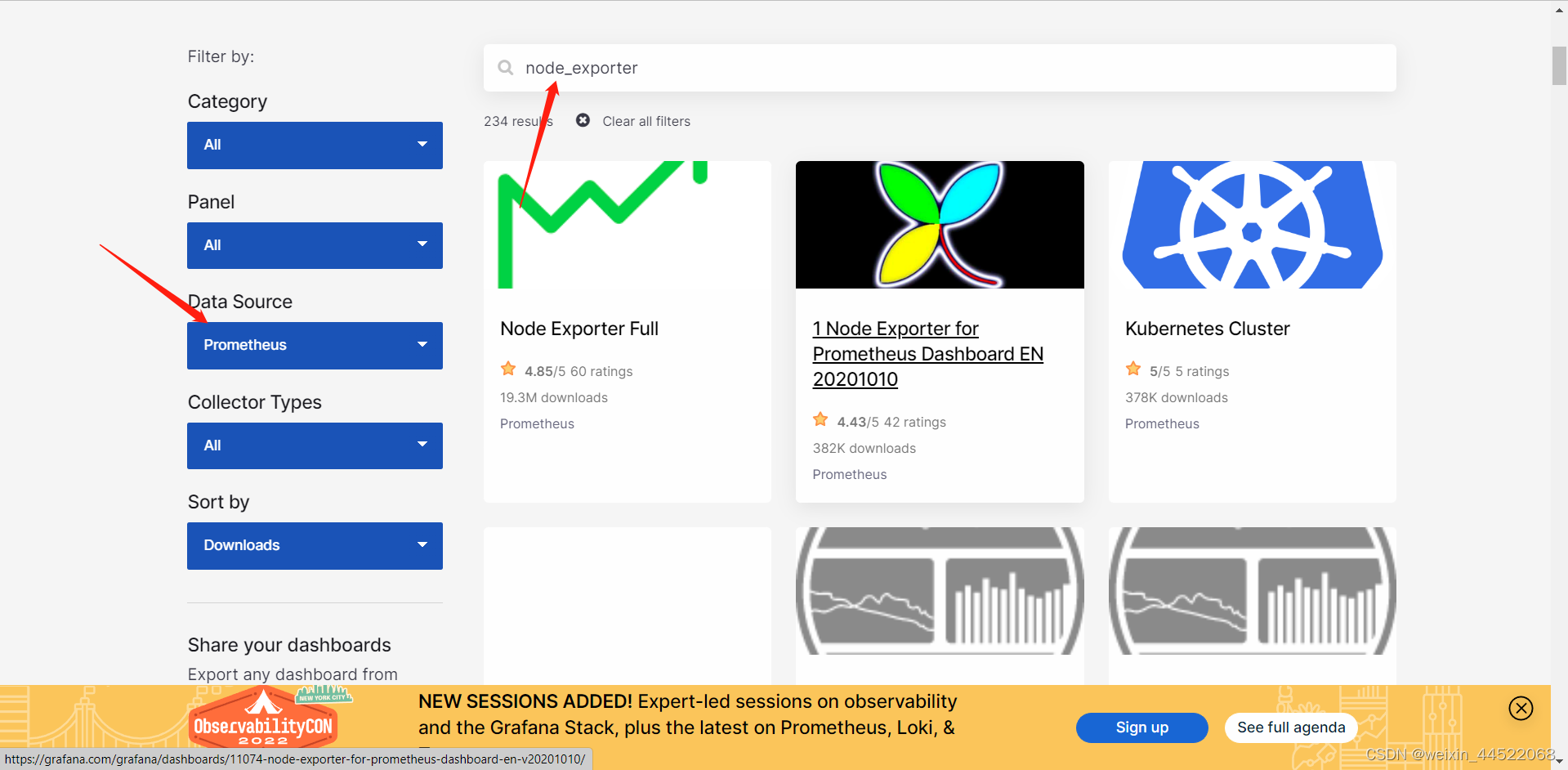
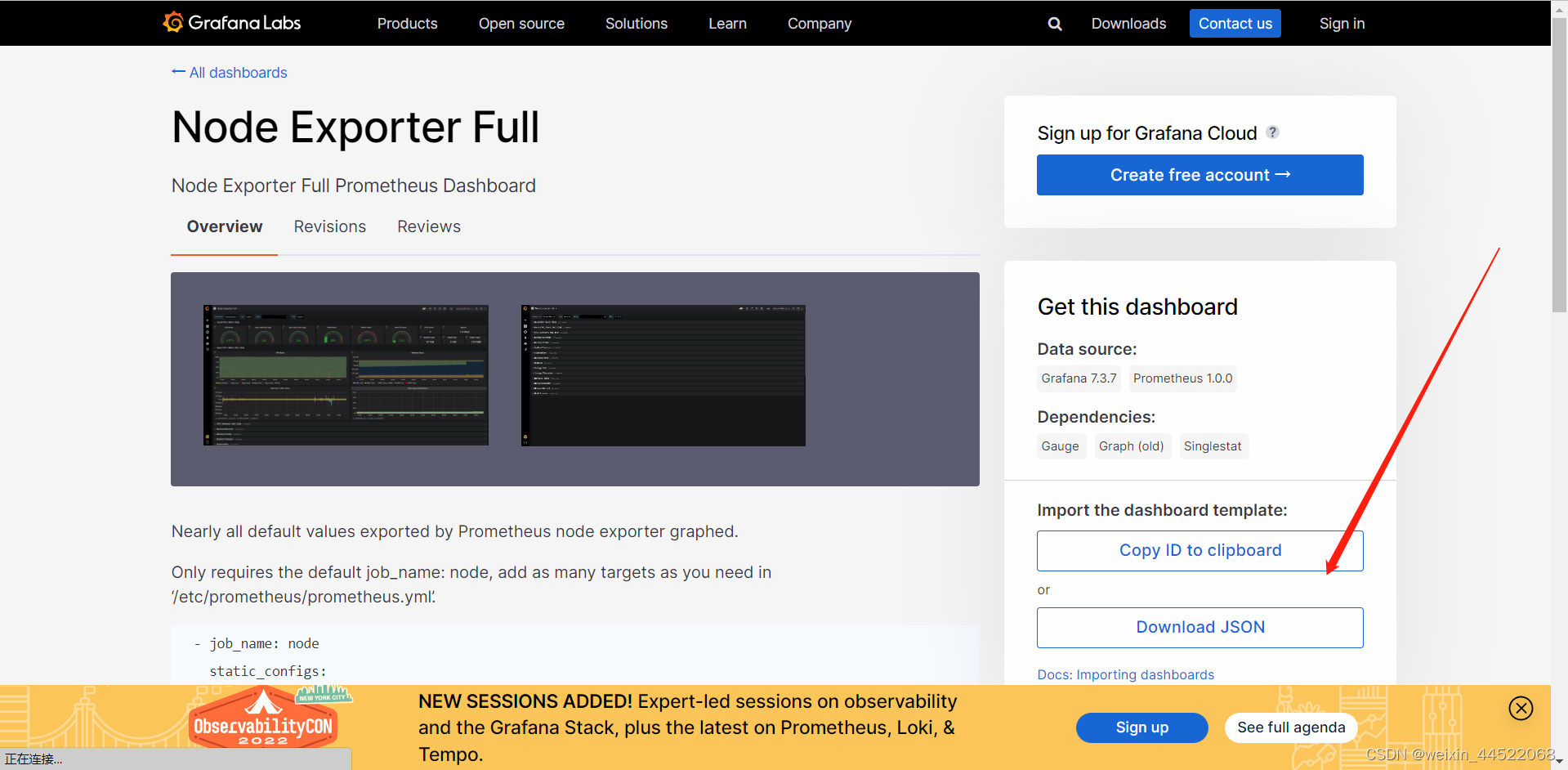
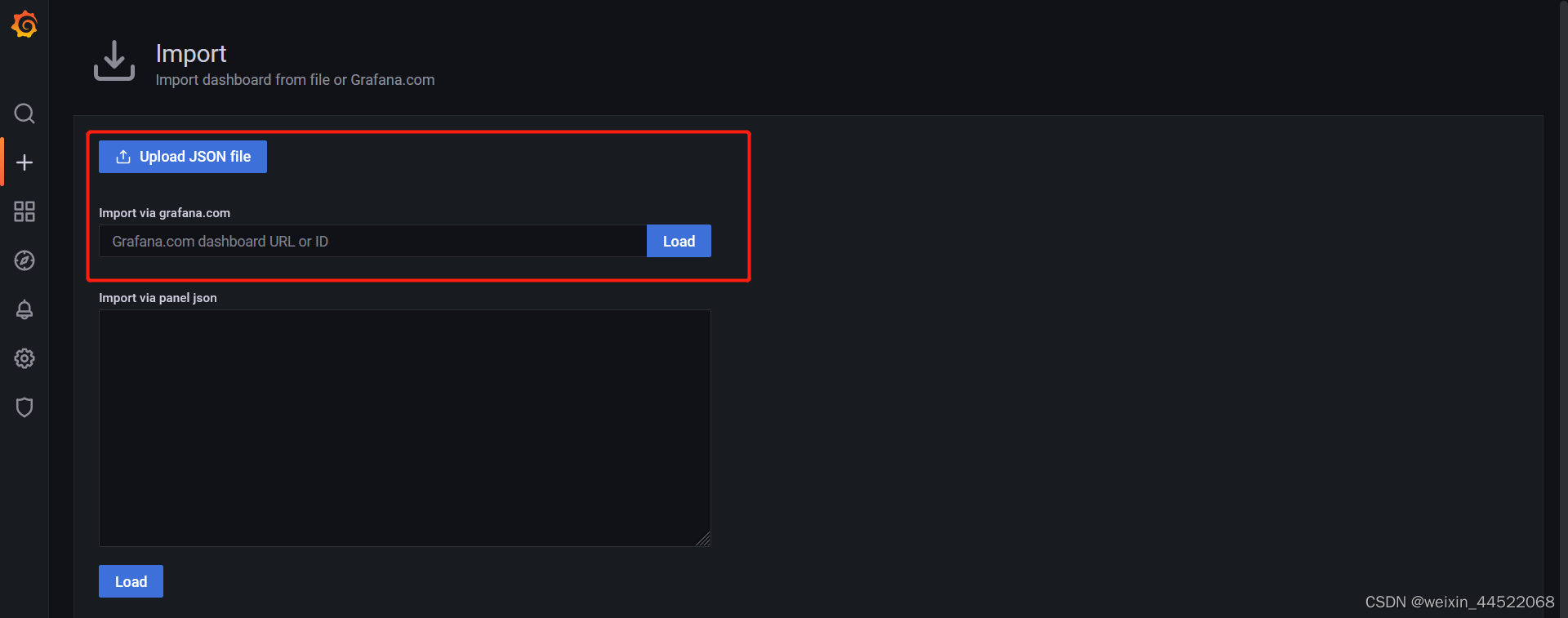
选着面板进入查看,这里的面板导入方式有两种,一个是服务器能联网的,直接通过id就可以导入了,服务器不能连接外网的可以下载面板的json文件,通过json文件导入。
















 3383
3383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









