






- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/rnFa-IeY93EpjVu0yzzjkw) 中的学习记录博客**
- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**
任务说明:数据集采用了来自澳大利亚许多地点的大约10年的每日天气观测数据。现在要根据这些数据对RainTomorrow进行一个预测。
一:导入数据
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_errordata = pd.read_csv("/content/drive/MyDrive/weatherAUS.csv")
df = data.copy()
data.head()
data.describe()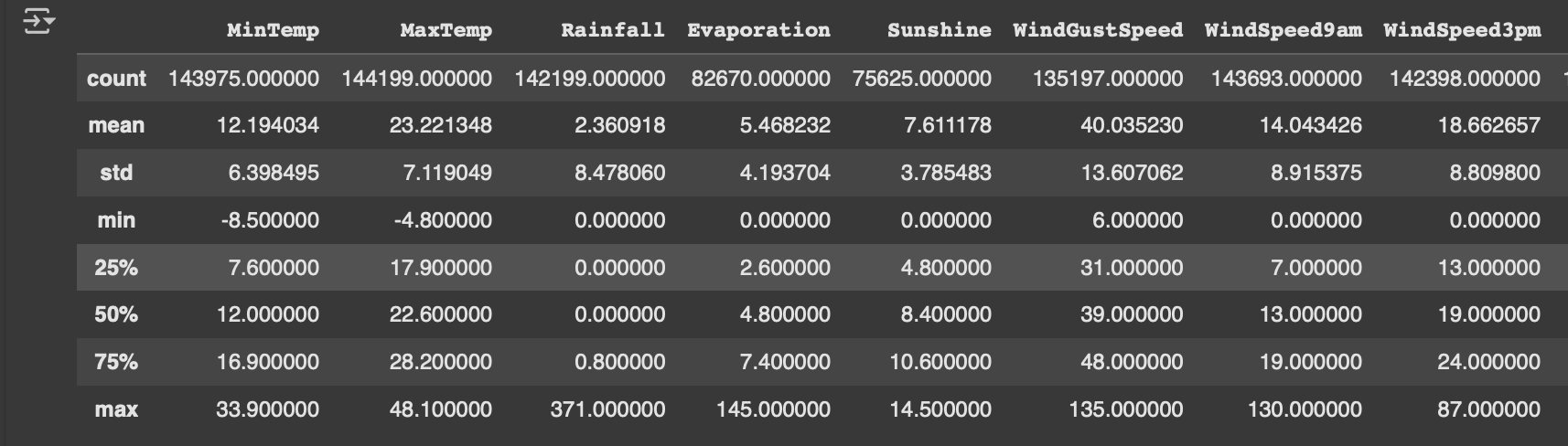
data.dtypes
#将数据转换为日期时间格式
data['Date'] = pd.to_datetime(data['Date'])
data['year'] = data['Date'].dt.year
data['month'] = data['Date'].dt.month
data['day'] = data['Date'].dt.day
data.head()
data.drop('Date',axis=1,inplace=True)
data.columns
二:探索式数据分析(EDA)
1.数据相关性探索
plt.figure(figsize=(15,13))
ax = sns.heatmap(data.corr(numeric_only=True),square=True,annot=True,fmt=' .2f')
ax.set_xticklabels(ax.get_xticklabels(),rotation=90)
plt.show()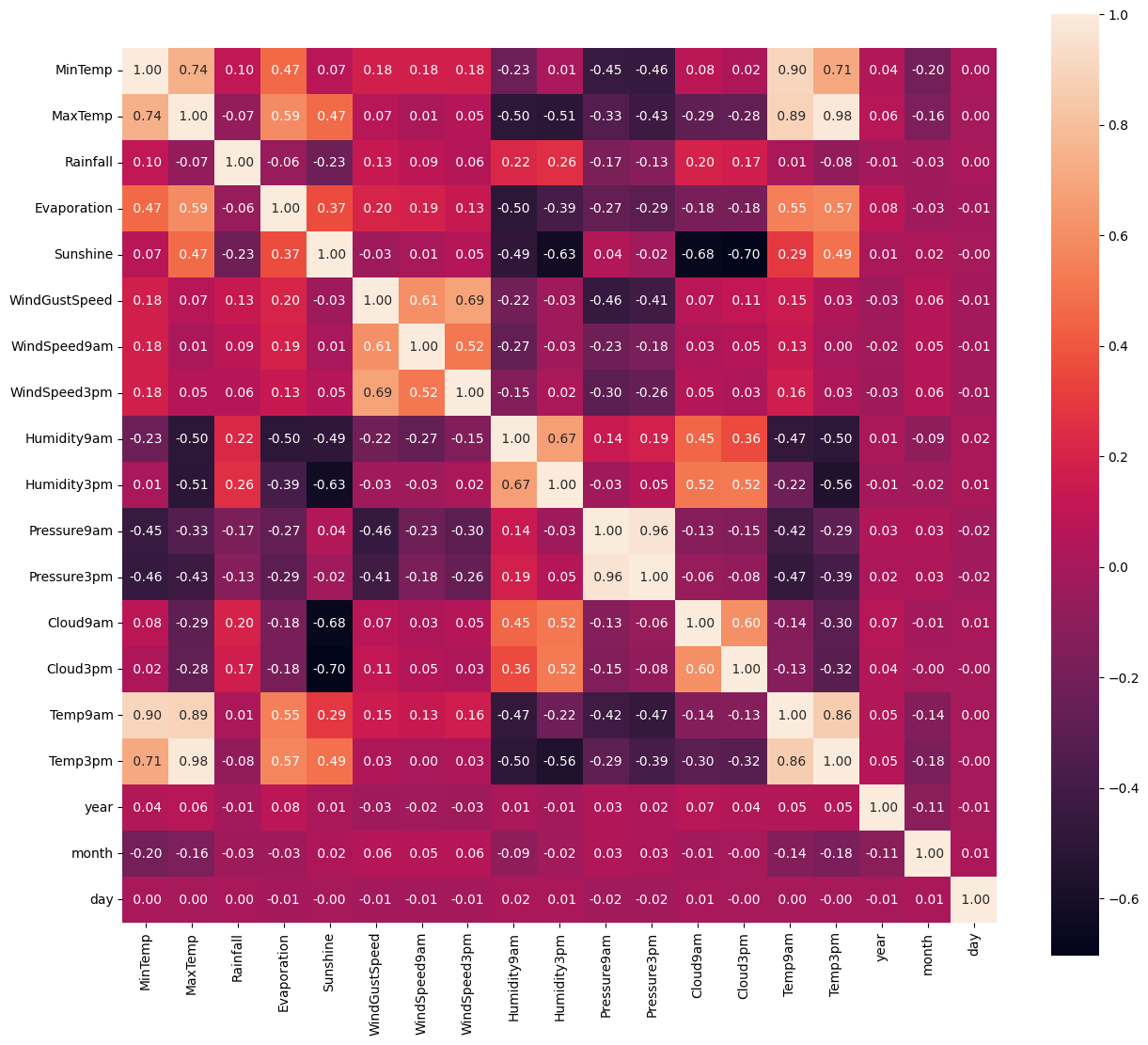
2.是否会下雨
sns.set(style="whitegrid",palette="Set2")
fig,axes = plt.subplots(1,2,figsize=(10,4))
title_font = {'fontsize':14,'fontweight':'bold','color':'darkblue'}
#第一张图:RainTomorrow
sns.countplot(x='RainTomorrow',data=data,ax=axes[0],edgecolor='black')
axes[0].set_title('RainTomorrow',fontdict=title_font)
axes[0].set_xlabel('Will it Rain Tomorrow?', fontsize=12)
axes[0].set_ylabel('Count',fontsize=12)
axes[0].tick_params(axis='x',labelsize=11)
axes[0].tick_params(axis='y',labelsize=11)
#第二张图:RainToday
sns.countplot(x='RainToday',data=data,ax=axes[1],edgecolor='black')
axes[1].set_title('RainToday',fontdict=title_font)
axes[1].set_xlabel('Will it Rain Today?', fontsize=12)
axes[1].set_ylabel('Count',fontsize=12)
axes[1].tick_params(axis='x',labelsize=11)
axes[1].tick_params(axis='y',labelsize=11)
sns.despine()
plt.tight_layout()
plt.show()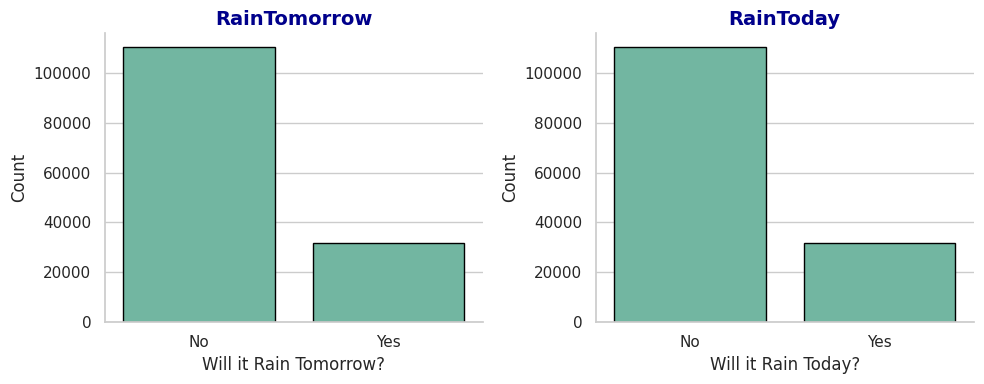
x=pd.crosstab(data['RainTomorrow'],data['RainToday'])
x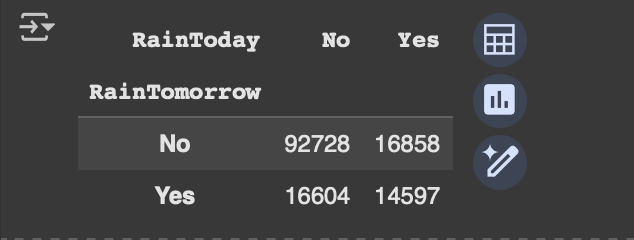
y=x/x.transpose().sum().values.reshape(2,1)*100
y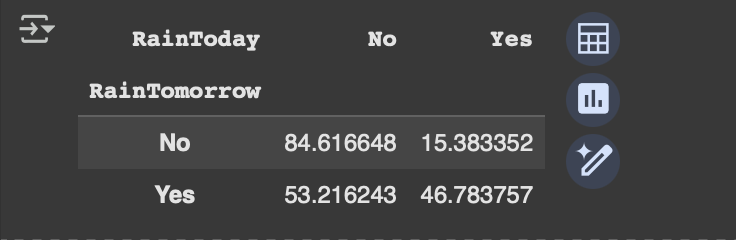
- 如果今天不下雨,那么明天下雨的机会=53.22%
- 如果今天下雨,明天下雨的机会=46.78%
y.plot(kind="bar",figsize=(4,3),color=['#006666','#d279a6'])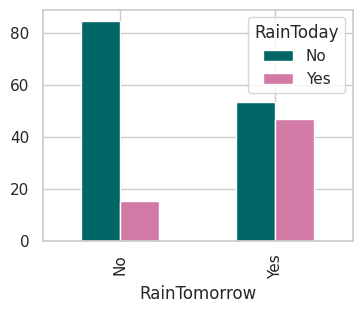
3.地理位置与下雨的关系
x=pd.crosstab(data['Location'],data['RainToday'])
y = x/x.transpose().sum().values.reshape(-1,1)*100
y = y.sort_values(by='Yes',ascending=True)
color = ['#cc6699','#006699','#006666','#862d86','#ff9966']
y.Yes.plot(kind='barh',figsize=(15,20),color=color)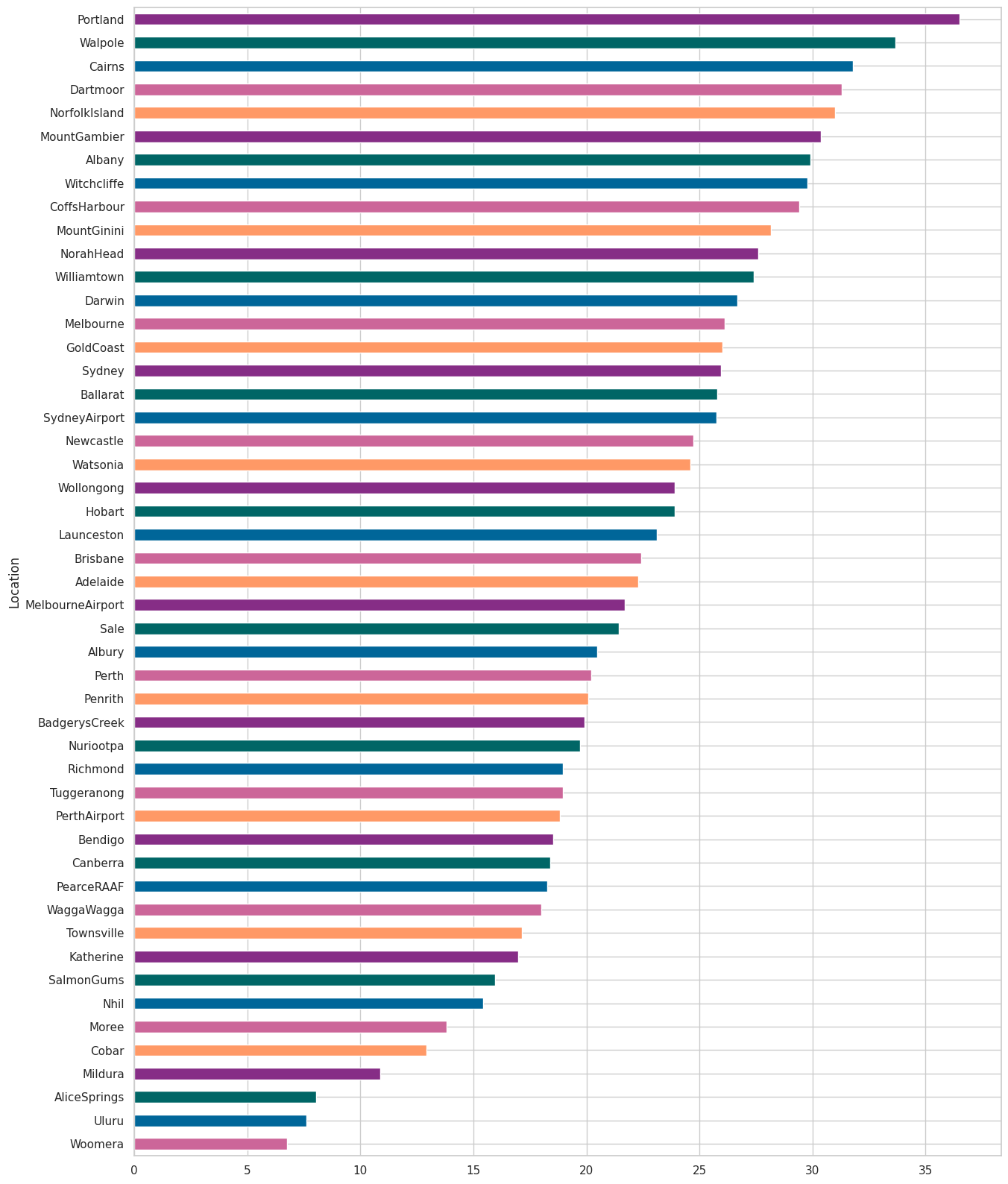
位置影响下雨,对于portland来说,有36%的时间在下雨,而对于woomers来说,只有6%的时间在下雨
4.湿度和压力对下雨的影响
#湿度和压力对下雨的影响
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='Pressure9am',y='Pressure3pm',hue='RainTomorrow')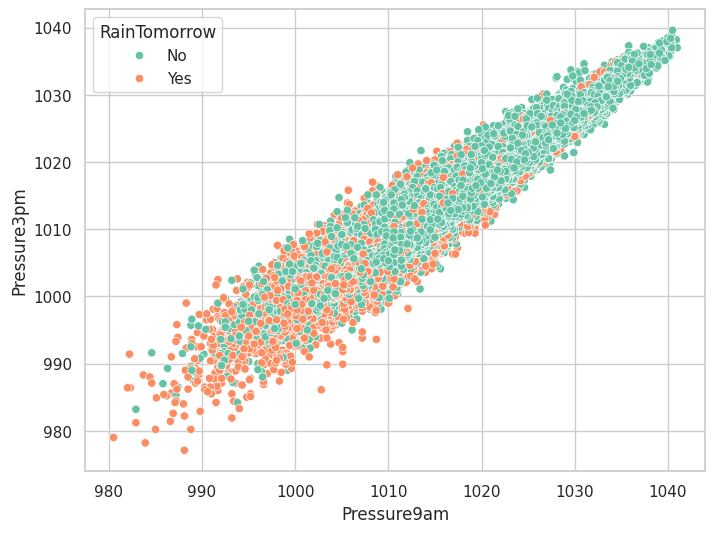
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='Humidity9am',y='Humidity3pm',hue='RainTomorrow')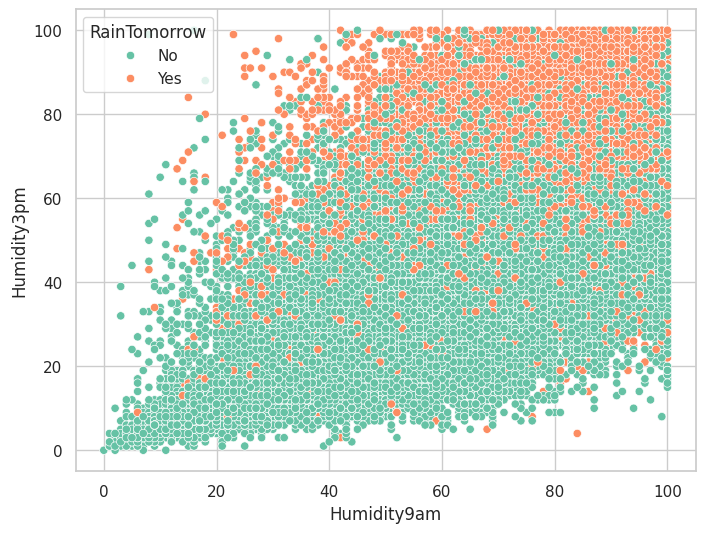
低压与高湿度会增加第二天下雨的概率
5.气温对下雨的影响
#气温对下雨的影响
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='MaxTemp',y='MinTemp',hue='RainTomorrow')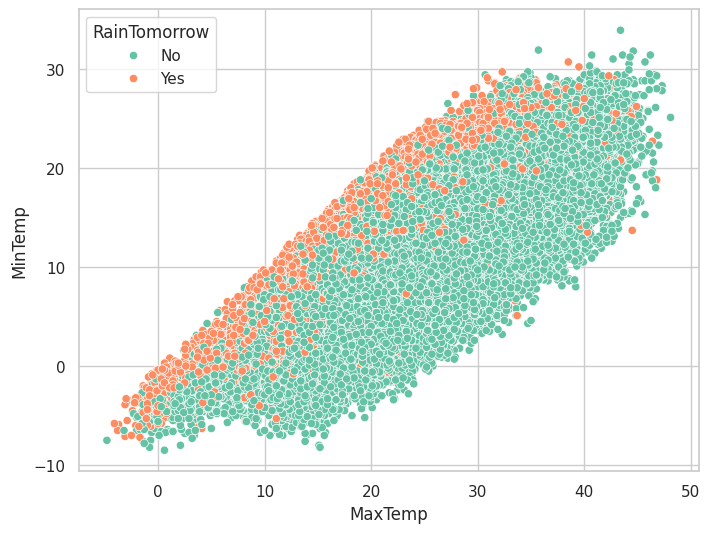
结论:当一天的最高气温和最低气温接近时,第二天下雨的概率会增加
三:数据预处理
1.处理缺失值
#处理缺失值
data.isnull().sum()/data.shape[0]*100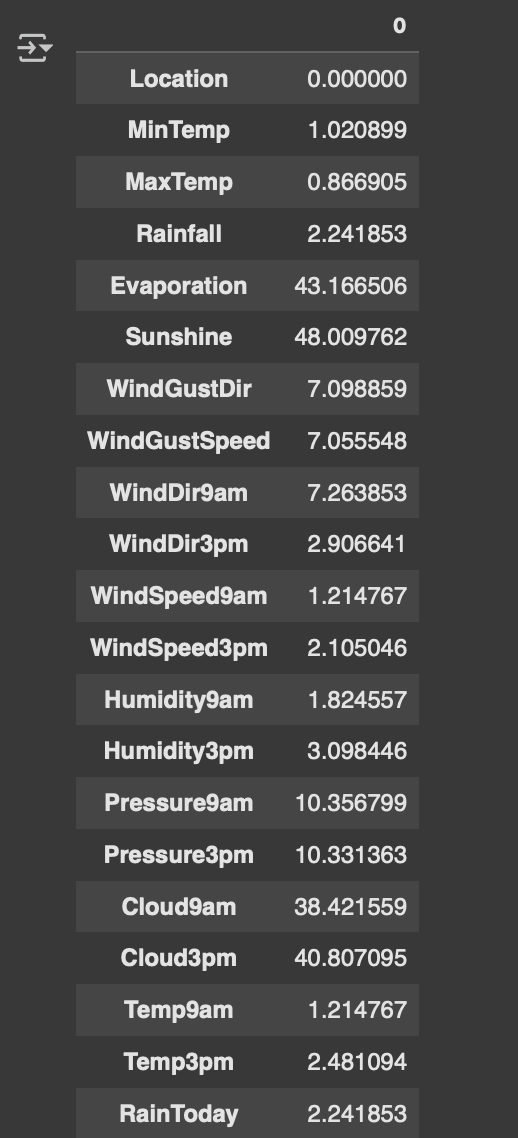
lst = ['Evaporation','Sunshine','Cloud9am','Cloud3pm']
for i in lst:
fill_list = data[i].dropna()
data[i] = data[i].fillna(pd.Series(np.random.choice(fill_list,size=len(data.index))))s=(data.dtypes == "object")
object_cols = list(s[s].index)
print("Categorical variables:")
print(object_cols)
for i in object_cols:
data[i].fillna(data[i].mode()[0],inplace=True)t = (data.dtypes == "float64")
float_cols = list(t[t].index)
print("Float variables:")
print(float_cols)
for i in float_cols:
data[i].fillna(data[i].median(),inplace=True)
data.isnull().sum()
2.构建数据集
#构建数据集
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
for i in object_cols:
data[i] = le.fit_transform(data[i])X = data.drop(['RainTomorrow','day'],axis=1).values
y = data['RainTomorrow'].valuesX_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=101)scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)四:预测是否下雨
1.搭建神经网络
#搭建神经网络
model = Sequential()
model.add(Dense(24,activation='tanh'))
model.add(Dense(18,activation='tanh'))
model.add(Dense(23,activation='tanh'))
model.add(Dropout(0.5))
model.add(Dense(12,activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(1,activation='sigmoid'))
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(optimizer,loss='binary_crossentropy',metrics=['accuracy'])early_stop = EarlyStopping(monitor='val_loss',mode='min',verbose=1,patience=25,restore_best_weights=True)2.模型训练
model.fit(x=X_train,y=y_train,epochs=10,validation_data=(X_test,y_test),verbose=1,callbacks=[early_stop],batch_size = 32)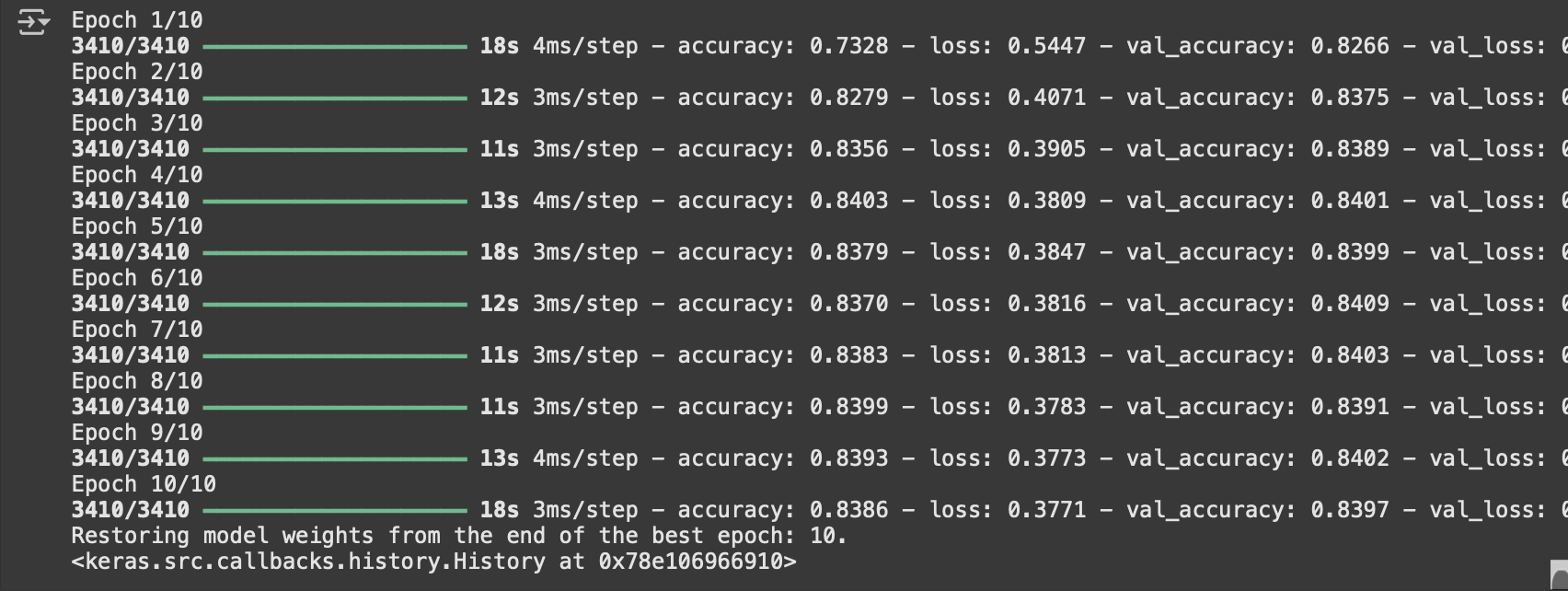
3.结果可视化
acc = model.history.history['accuracy']
val_acc = model.history.history['val_accuracy']
loss = model.history.history['loss']
val_loss = model.history.history['val_loss']
epochs_range = range(10)
plt.figure(figsize=(14,4))
plt.subplot(1,2,1)
plt.plot(epochs_range,acc,label='Training Accuracy')
plt.plot(epochs_range,val_acc,label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1,2,2)
plt.plot(epochs_range,loss,label='Training Loss')
plt.plot(epochs_range,val_loss,label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()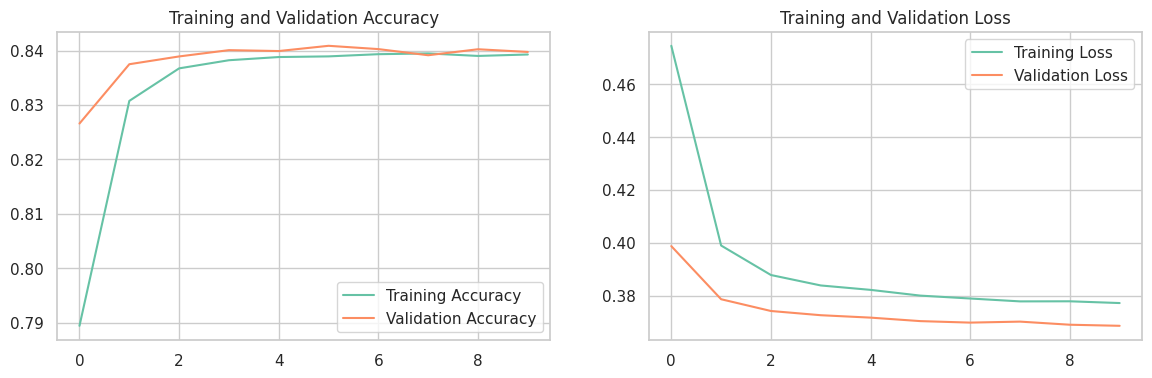


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









