







声明:本文仅供学习用,旨在分享
现在大型网站对selenium工具都会进行检测,若检测到selenium就判定为机器人,访问被拒或出现像淘宝一样的滑块验证等机制。基于多次失败的经验教训及探讨,为避免触发淘宝的反爬机制,此次通过利用 Chrome DevTools 协议及基于Python开发的自动化测试脚本模块Pywinauto进行淘宝的自动化登录操作,在登录后通过selenium获取登录后的cookies,再通过先前那篇《python项目实战:用多进程(multiprocessing)+多线程(threading)的方式并发爬取淘宝商品信息并存入MongoDB》中模拟发送请求的方式进行数据爬取。下面是程序的运行过程,整个过程中不能触碰鼠标和键盘,因为要让当前的句柄为所打开的浏览器。
以下是代码:
#-*-coding:UTF-8-*-
import random,os,time,requests
from pywinauto import keyboard
from selenium import webdriver
chrome_path=r'C:\Users\juzhang\AppData\Local\Google\Chrome\Application\chrome.exe'#浏览器的位置
chrome_info=r'C:\\selenium\\AutomationProfile'#新创建一个目录用于存储 Chrome 配置文件信息
chrome_driver = './mychromedriver.exe'#驱动版本根据浏览器的版本不同会有所不同,需要提前下载
port=9222#指定任何调试端口
def set_user_agent():
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
return random.choice(USER_AGENTS)
class TaoBao():
def __init__(self):
self.user='你的账号'
self.password='你的密码'
self.login_url='https://login.taobao.com/member/login.jhtml?redirectURL=https%3A%2F%2Fwww.taobao.com%2F'
self.cookies_url='https://i.taobao.com/my_taobao.htm?'
self.test_url='https://s.taobao.com/search?q=%E7%BE%8E%E9%A3%9F&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20190221&ie=utf8'
self.session = requests.session()
self.headers = {"Origin": "https://login.taobao.com",
"Upgrade-Insecure-Requests": "1",
"Content-Type": "application/x-www-form-urlencoded",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Referer": "https://login.taobao.com/member/login.jhtml?redirectURL=https%3A%2F%2Fwww.taobao.com%2F",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"User-Agent": set_user_agent()}
def save_cookies(self,cookies):
with open('.//cookies.txt', "w", encoding="utf-8") as f:
str1=''
for cookie in cookies:
name=cookie['name']
value=cookie['value']
str1+=str(name+'='+value+';')
f.write(str1.strip(";"))
def get_mycookies(self):
with open('.//cookies.txt', "r", encoding="gb18030",errors= 'ignore') as f:
return f.read()
def run(self):
cookie = self.get_mycookies()
cookises = {i.split("=")[0]: i.split("=")[1] for i in cookie.split(";")}
cookiesjar = requests.utils.cookiejar_from_dict(cookises)
self.session.headers = self.headers
self.session.cookies = cookiesjar
response = self.session.get(self.test_url)
print(response.text)#response.content.decode()
def auto(self):
os.popen(chrome_path+" --remote-debugging-port=%s --user-data-dir=%s"%(port,chrome_info))#执行命令启动浏览器DBUG模式
time.sleep(3)
##############
keyboard.send_keys(self.login_url)
keyboard.send_keys('{VK_RETURN}')
time.sleep(2)
#切换到密码登录
keyboard.send_keys('{VK_TAB}{VK_TAB}{VK_TAB}{VK_TAB}{VK_TAB}{VK_TAB}')
keyboard.send_keys('{VK_RETURN}')
keyboard.send_keys(self.user)
#输入账号
keyboard.send_keys('{VK_TAB}')
time.sleep(2)
keyboard.send_keys(self.password)
#输入密码
keyboard.send_keys('{VK_TAB}')
time.sleep(2)
keyboard.send_keys('{VK_RETURN}')
time.sleep(15)
##############
options = webdriver.ChromeOptions()
options.debugger_address = "127.0.0.1:%s"%port
options.binary_location = chrome_path # 有多个浏览器时设置路径
options.add_argument("user-data-dir=%s" % chrome_info) # 使用自己设置的浏览器信息
browser = webdriver.Chrome(executable_path=chrome_driver, chrome_options=options)
print("当前打开页面的标题是: " + browser.title)
print('获取cookies')
cookies = browser.get_cookies()
self.save_cookies(cookies)
browser.minimize_window()
self.run()
browser.quit()
if __name__ == '__main__':
taobao = TaoBao()
taobao.auto()
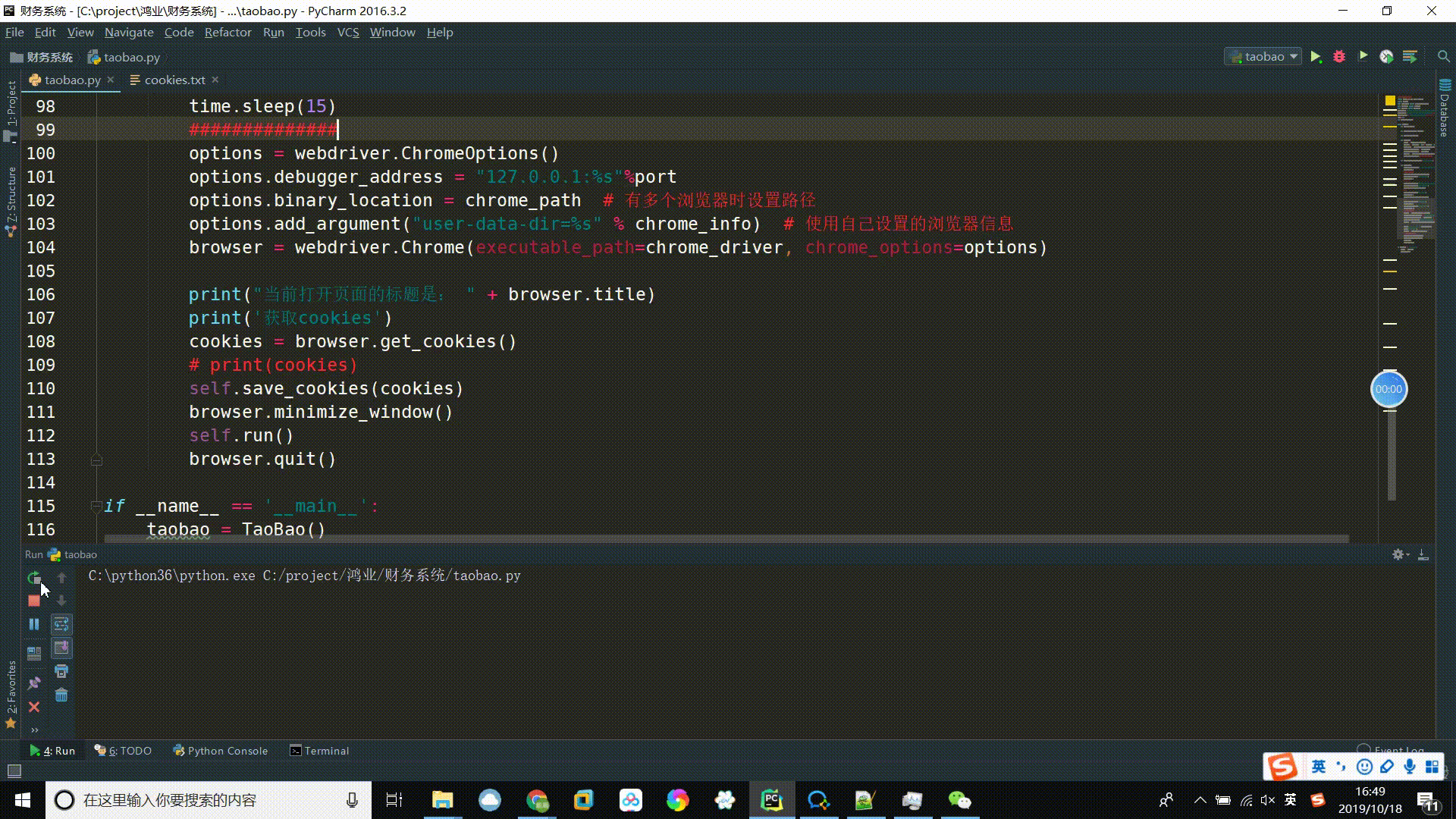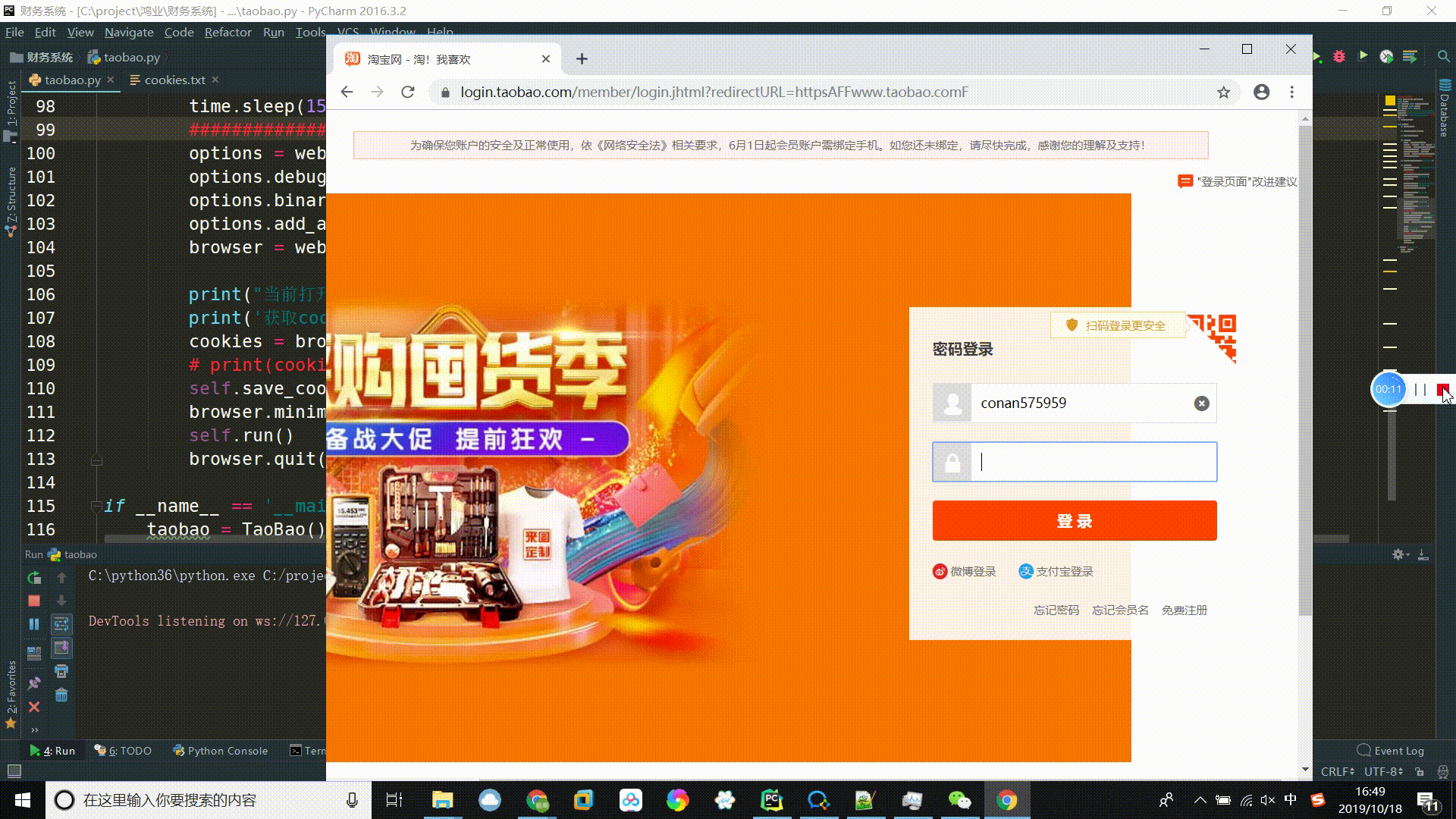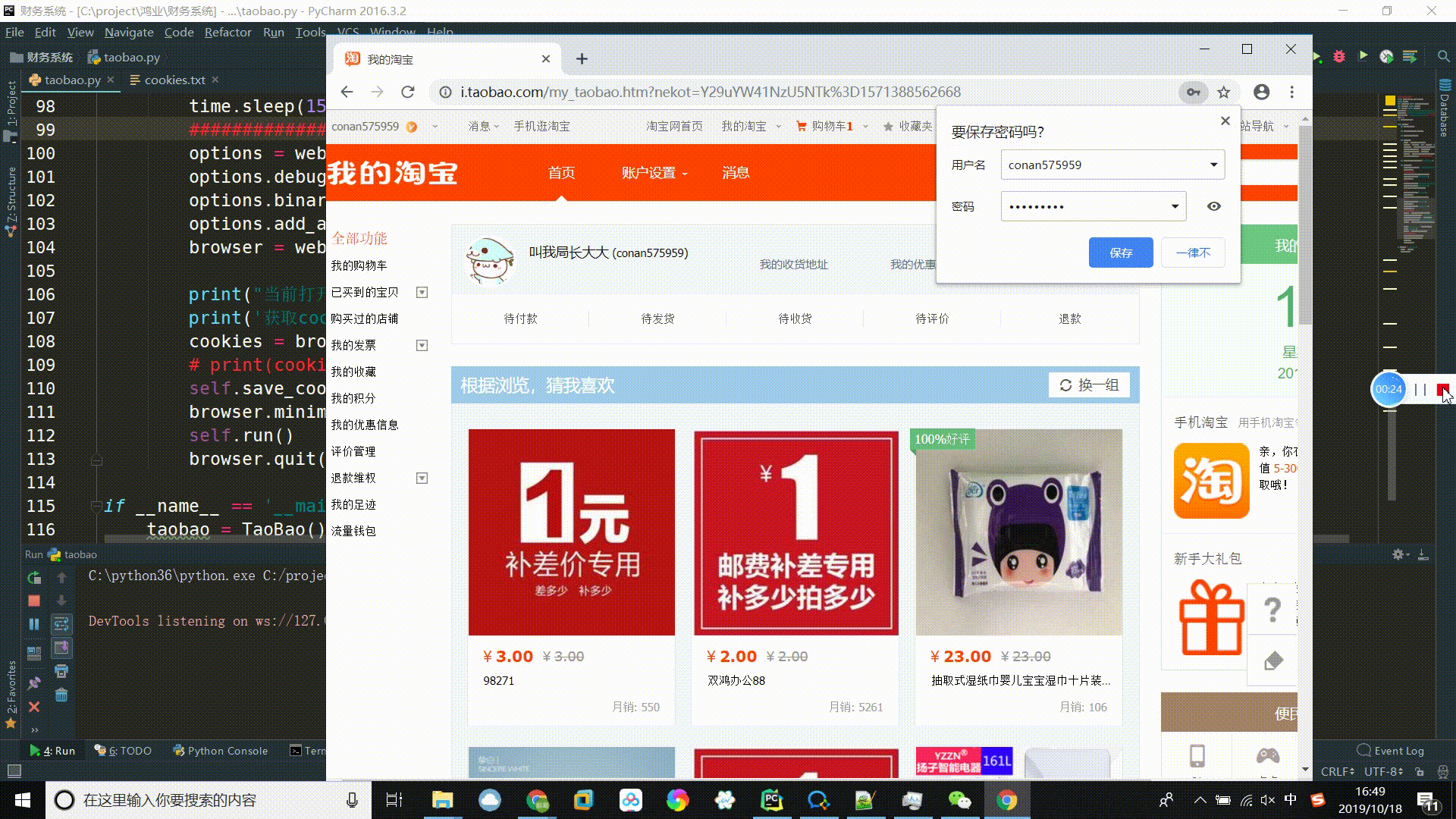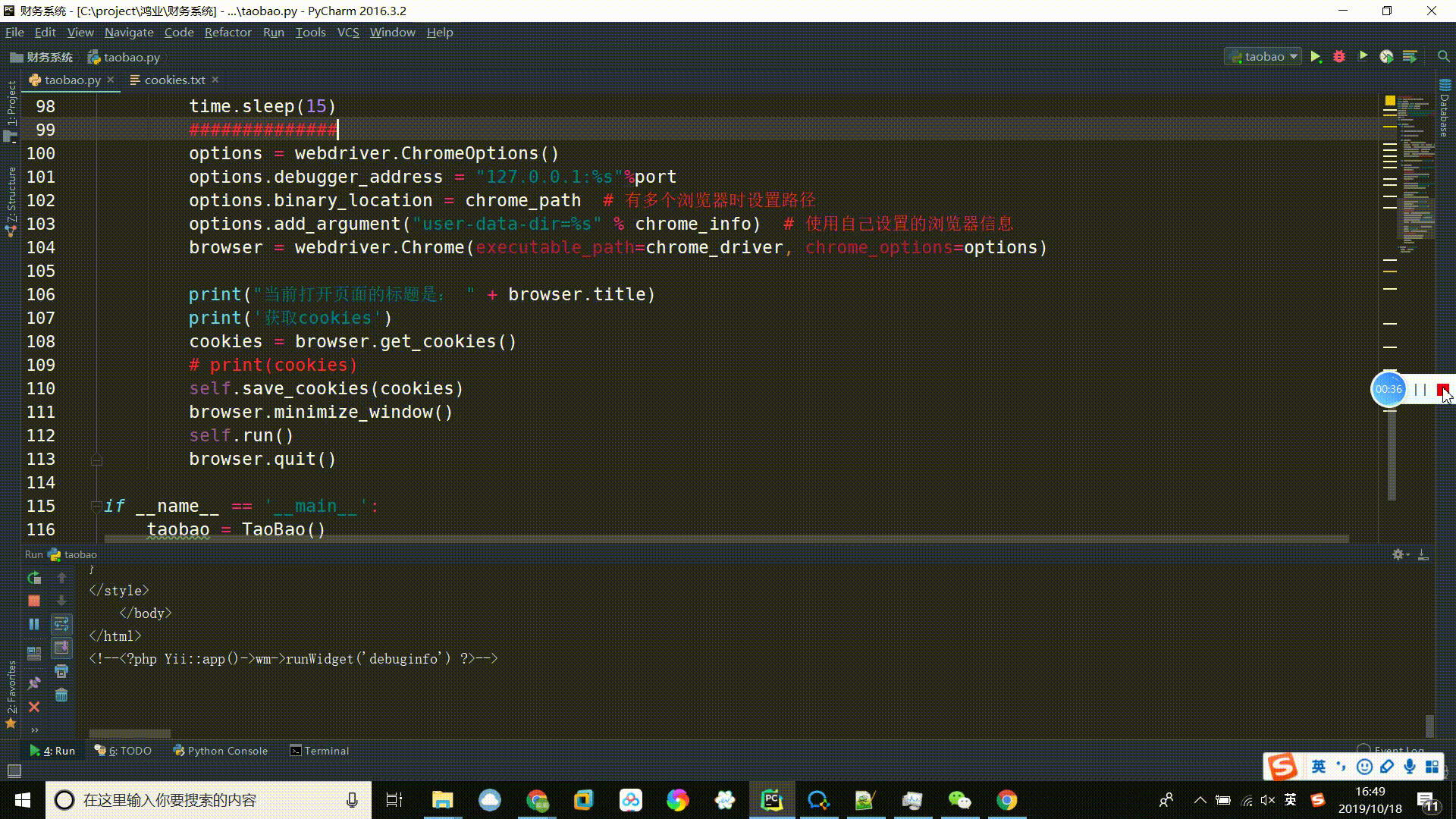
运行结果(此处只打印页面源代码,后续的信息提取按照先前那篇《python项目实战:用多进程(multiprocessing)+多线程(threading)的方式并发爬取淘宝商品信息并存入MongoDB》执行):
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









