







 本文详细解析了网易云音乐API的工作原理,包括如何解密请求参数以获取歌曲播放链接,以及如何利用requests-html库提取歌单信息,最终实现自动化下载歌曲。
本文详细解析了网易云音乐API的工作原理,包括如何解密请求参数以获取歌曲播放链接,以及如何利用requests-html库提取歌单信息,最终实现自动化下载歌曲。
**1、**首先我们打开歌单内的任意一首歌曲,在该页面下打开chrome的开发者工具后切换到Network后重新刷新页面,找到请求到该歌曲播放源的URL,如下图:
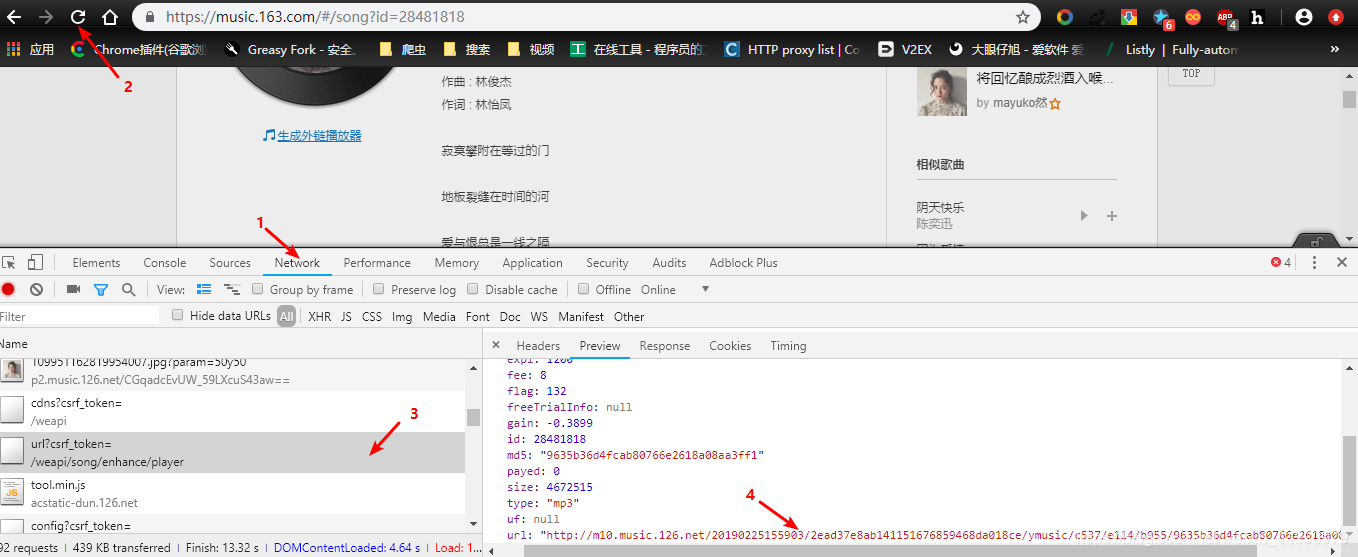
找到后切换到Headers,可以看到其为一个post请求,URL为:‘https://music.163.com/weapi/song/enhance/player/url?csrf_token=’ ,从上图可知这个URL返回的是json,里面包含的是歌曲的信息及其MP3播放链接,请求时携带的参数为params及encSecKey,为了找到该歌曲播放源的URL,我们需解密params及encSecKey。
**2、**以encSecKey为关键词进行全局搜索,找到加密该参数的文件,如下图:
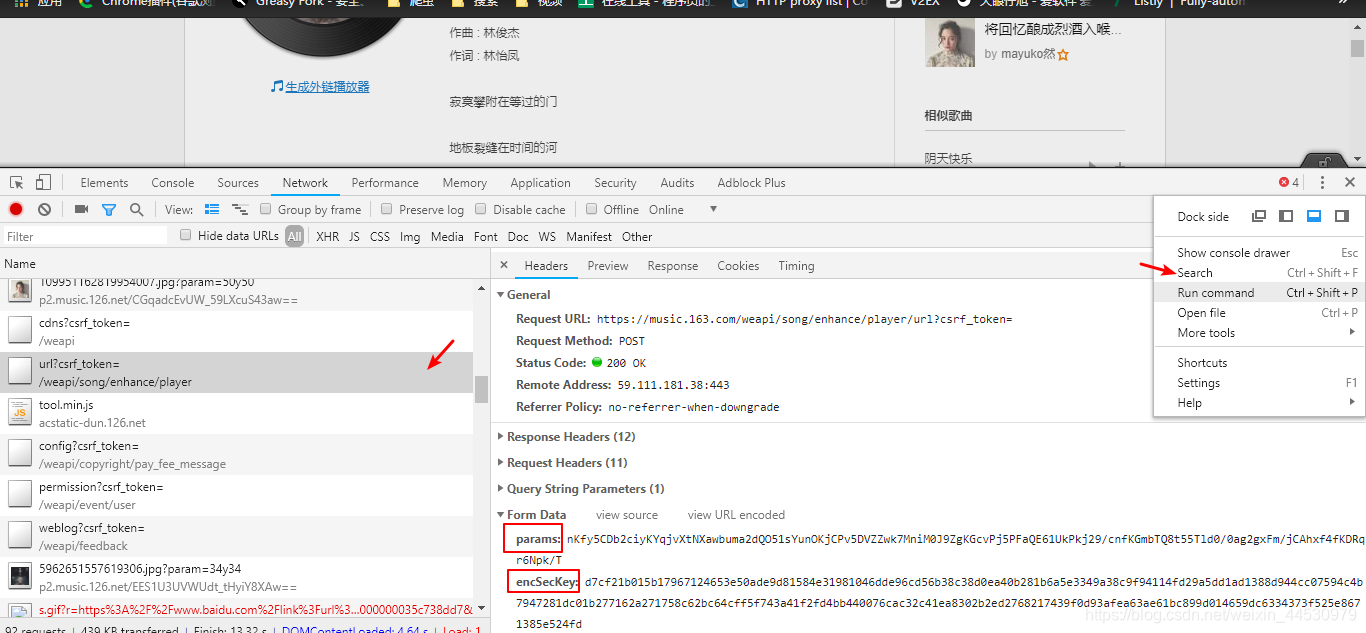
接着找到该参数是如何生成的,从下图可以看到其与bYd2x有关,为了得到该encSecKey我们需知道bYd2x这个值是如何生成的,所以我们按下图的操作设置断点,然后重新刷新页面进行调试。
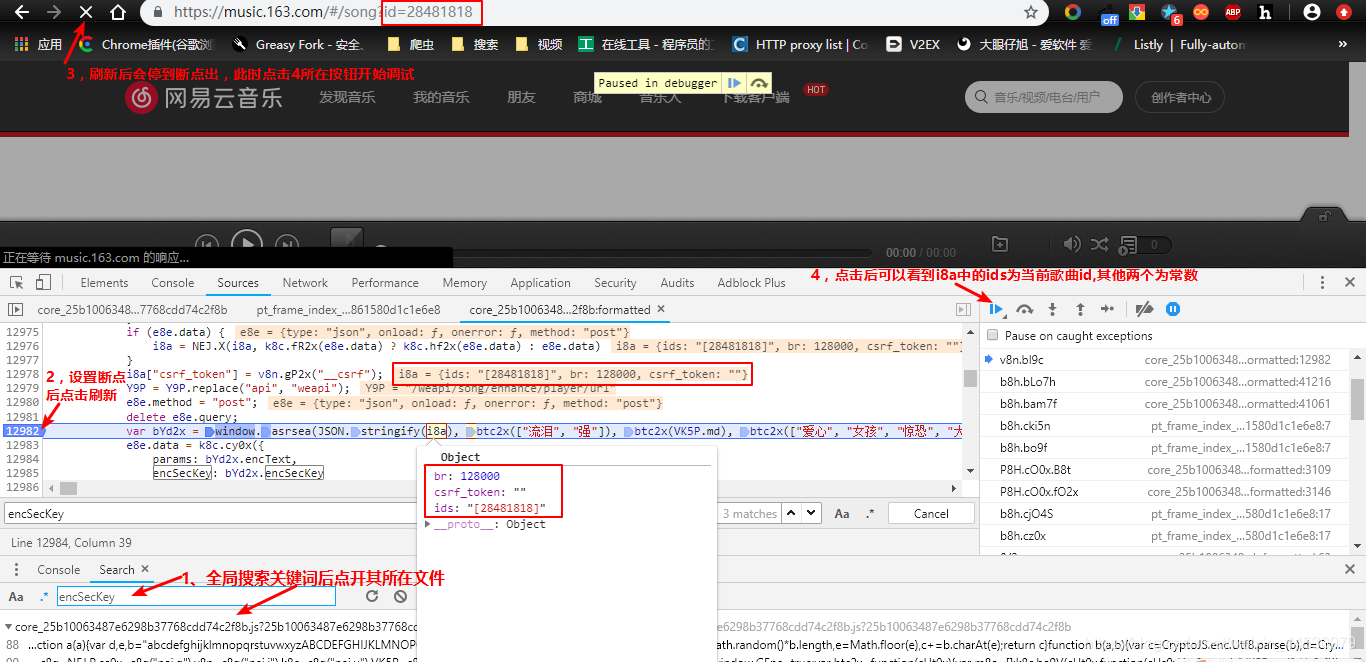
按上图操作后,我们可以看到bYd2x这个函数中有四个参数,其中i8a与我们的歌曲id有关,另外三个参数我们也需要找出来,通过多次调试后可以看到其返回的值其实都是固定值,调试结果如下图:
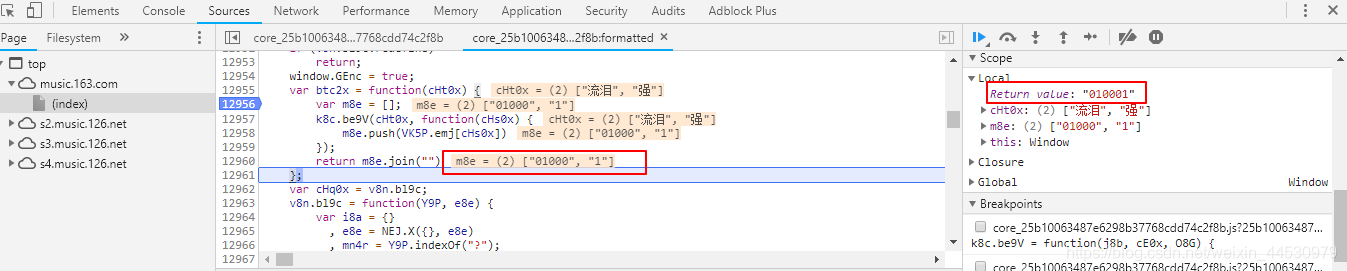


通过上面分析得知其需要的参数值后,我们需找到window.asrsea这个函数是如何执行的,这样才能从其返回值里得到encText(即params)和encSecKey。在调试模式下我们按下图将鼠标悬浮到这个函数上可知它其实就是d函数,因此我们需找到d函数的定义。
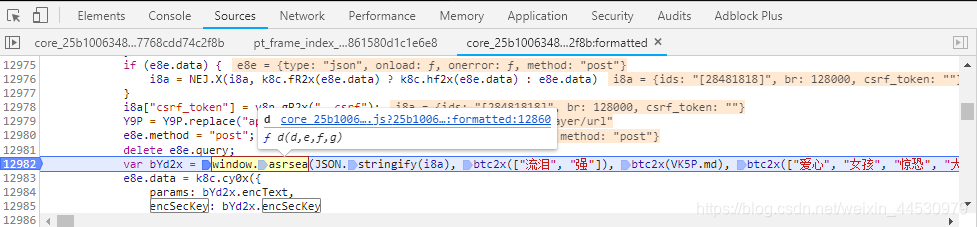
**3、**按上图将鼠标悬浮到这个函数上后我们点击悬浮框上的蓝色字体可以到达定义d函数的位置,如下图所示:

从上图可知d函数与a函数,b函数及c函数有关,且excText的值由b函数加密了两次,因此我们要分别找到这些函数的定义并写成python语言,同样的我们在var h={}这行打上断点后重新刷新页面。首先我们找到a函数,其定义如下图:

可以看到它其实是在一堆字符串中随机找出16个字符串,将其写成python为:
get_i=execjs.compile(r"""
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









