







本篇为Datawhale组队学习笔记,Datawhale推荐系统实践
天池比赛地址:零基础入门推荐系统
排序模型
通过召回的操作, 我们已经进行了问题规模的缩减, 对于每个用户, 选择出了N篇文章作为了候选集,并基于召回的候选集构建了与用户历史相关的特征,以及用户本身的属性特征,文章本省的属性特征,以及用户与文章之间的特征,下面就是使用机器学习模型来对构造好的特征进行学习,然后对测试集进行预测,得到测试集中的每个候选集用户点击的概率,返回点击概率最大的topk个文章,作为最终的结果。
排序阶段选择了三个比较有代表性的排序模型,它们分别是:
- LGB的排序模型
- LGB的分类模型
- 深度学习的分类模型DIN
得到了最终的排序模型输出的结果之后,还选择了两种比较经典的模型集成的方法:
- 输出结果加权融合
- Staking(将模型的输出结果再使用一个简单模型进行预测)
DIN模型简介
我们下面尝试使用DIN模型, DIN的全称是Deep Interest Network, 这是阿里2018年基于前面的深度学习模型无法表达用户多样化的兴趣而提出的一个模型, 它可以通过考虑【给定的候选广告】和【用户的历史行为】的相关性,来计算用户兴趣的表示向量。具体来说就是通过引入局部激活单元,通过软搜索历史行为的相关部分来关注相关的用户兴趣,并采用加权和来获得有关候选广告的用户兴趣的表示。与候选广告相关性较高的行为会获得较高的激活权重,并支配着用户兴趣。该表示向量在不同广告上有所不同,大大提高了模型的表达能力。所以该模型对于此次新闻推荐的任务也比较适合, 我们在这里通过当前的候选文章与用户历史点击文章的相关性来计算用户对于文章的兴趣。 该模型的结构如下:
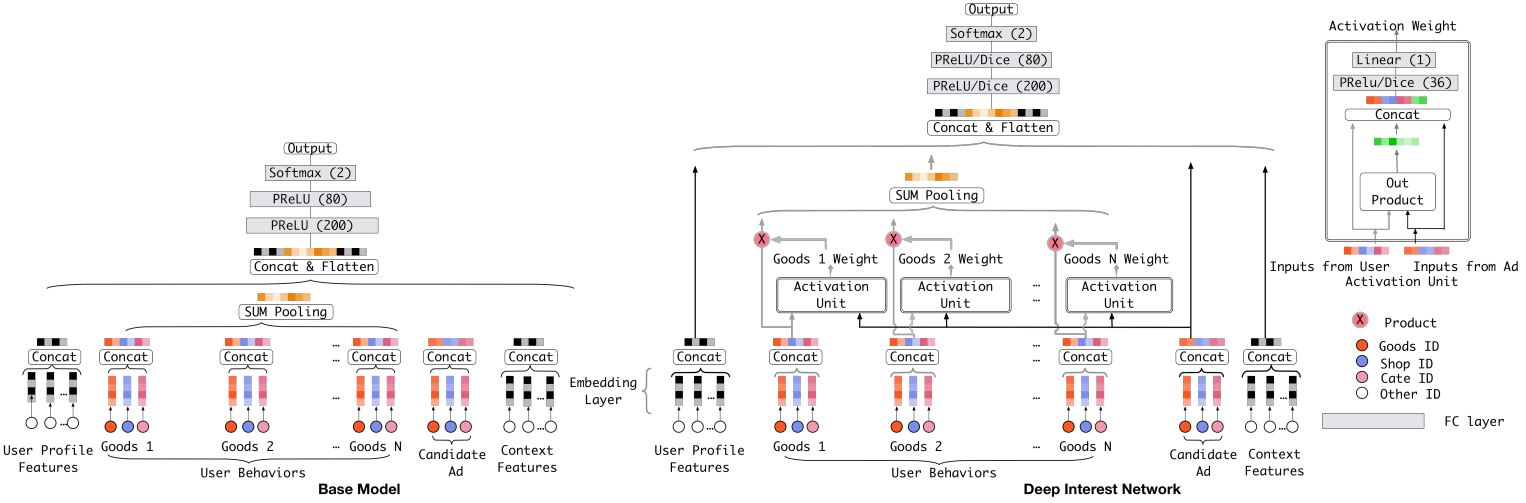
我们这里直接调包来使用这个模型, 关于这个模型的详细细节部分我们会在下一期的推荐系统组队学习中给出。下面说一下该模型如何具体使用:deepctr的函数原型如下:
def DIN(dnn_feature_columns, history_feature_list, dnn_use_bn=False,
dnn_hidden_units=(200, 80), dnn_activation=‘relu’, att_hidden_size=(80, 40), att_activation=“dice”,
att_weight_normalization=False, l2_reg_dnn=0, l2_reg_embedding=1e-6, dnn_dropout=0, seed=1024,
task=‘binary’):
- dnn_feature_columns: 特征列, 包含数据所有特征的列表
- history_feature_list: 用户历史行为列, 反应用户历史行为的特征的列表
- dnn_use_bn: 是否使用BatchNormalization
- dnn_hidden_units: 全连接层网络的层数和每一层神经元的个数, 一个列表或者元组
- dnn_activation_relu: 全连接网络的激活单元类型
- att_hidden_size: 注意力层的全连接网络的层数和每一层神经元的个数
- att_activation: 注意力层的激活单元类型
- att_weight_normalization: 是否归一化注意力得分
- l2_reg_dnn: 全连接网络的正则化系数
- l2_reg_embedding: embedding向量的正则化稀疏
- dnn_dropout: 全连接网络的神经元的失活概率
- task: 任务, 可以是分类, 也可是是回归
在具体使用的时候, 我们必须要传入特征列和历史行为列, 但是再传入之前, 我们需要进行一下特征列的预处理。具体如下:
- 首先,我们要处理数据集, 得到数据, 由于我们是基于用户过去的行为去预测用户是否点击当前文章, 所以我们需要把数据的特征列划分成数值型特征, 离散型特征和历史行为特征列三部分, 对于每一部分, DIN模型的处理会有不同
- 对于离散型特征, 在我们的数据集中就是那些类别型的特征, 比如user_id这种, 这种类别型特征, 我们首先要经过embedding处理得到每个特征的低维稠密型表示, 既然要经过embedding, 那么我们就需要为每一列的类别特征的取值建立一个字典,并指明embedding维度, 所以在使用deepctr的DIN模型准备数据的时候, 我们需要通过SparseFeat函数指明这些类别型特征, 这个函数的传入参数就是列名, 列的唯一取值(建立字典用)和embedding维度。
- 对于用户历史行为特征列, 比如文章id, 文章的类别等这种, 同样的我们需要先经过embedding处理, 只不过和上面不一样的地方是,对于这种特征, 我们在得到每个特征的embedding表示之后, 还需要通过一个Attention_layer计算用户的历史行为和当前候选文章的相关性以此得到当前用户的embedding向量, 这个向量就可以基于当前的候选文章与用户过去点击过得历史文章的相似性的程度来反应用户的兴趣, 并且随着用户的不同的历史点击来变化,去动态的模拟用户兴趣的变化过程。这类特征对于每个用户都是一个历史行为序列, 对于每个用户, 历史行为序列长度会不一样, 可能有的用户点击的历史文章多,有的点击的历史文章少, 所以我们还需要把这个长度统一起来, 在为DIN模型准备数据的时候, 我们首先要通过SparseFeat函数指明这些类别型特征, 然后还需要通过VarLenSparseFeat函数再进行序列填充, 使得每个用户的历史序列一样长, 所以这个函数参数中会有个maxlen,来指明序列的最大长度是多少。
- 对于连续型特征列, 我们只需要用DenseFeat函数来指明列名和维度即可。
- 处理完特征列之后, 我们把相应的数据与列进行对应,就得到了最后的数据。
下面根据具体的代码感受一下, 逻辑是这样, 首先我们需要写一个数据准备函数, 在这里面就是根据上面的具体步骤准备数据, 得到数据和特征列, 然后就是建立DIN模型并训练, 最后基于模型进行测试。















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









