






 本文概述了Elasticsearch作为分布式搜索引擎的基础,包括其基于Lucene的设计、核心概念如近实时、集群、文档、索引和shard-replica结构。讲解了数据写入、查询和搜索原理,以及如何通过分布式架构实现性能提升。还介绍了本地安装、使用实践和最佳实践,如性能优化、索引创建和数据同步方法。
本文概述了Elasticsearch作为分布式搜索引擎的基础,包括其基于Lucene的设计、核心概念如近实时、集群、文档、索引和shard-replica结构。讲解了数据写入、查询和搜索原理,以及如何通过分布式架构实现性能提升。还介绍了本地安装、使用实践和最佳实践,如性能优化、索引创建和数据同步方法。
Part1: ES介绍及核心概念
Elasticsearch是什么
Lucene 是最先进、功能最强大的搜索库。如果直接基于 Lucene 开发,非常复杂,即便写一些简单的功能,也要写大量的 Java 代码,需要深入理解原理。
ElasticSearch 基于 Lucene,隐藏了 lucene 的复杂性,提供了简单易用的 RESTful api / Java api 接口(另外还有其他语言的 api 接口)。
分布式的文档存储引擎
分布式的搜索引擎和分析引擎
分布式,支持 PB 级数据
ES可以用来干什么?
Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
应用程序搜索
网站搜索
企业搜索
日志处理和分析
基础设施指标和容器监测
应用程序性能监测
业务分析
ES 的核心概念
Near Realtime
近实时,有两层意思:
从写入数据到数据可以被搜索到有一个小延迟(大概是 1s)
基于 ES 执行搜索和分析可以达到秒级
Cluster 集群
集群包含多个节点,每个节点属于哪个集群都是通过一个配置来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常。
Node 节点
Node 是集群中的一个节点,节点也有一个名称,默认是随机分配的。默认节点会去加入一个名称为 elasticsearch 的集群。如果直接启动一堆节点,那么它们会自动组成一个 elasticsearch 集群,当然一个节点也可以组成 elasticsearch 集群。
Document & field
文档是 ES 中最小的数据单元,一个 document 可以是一条客户数据、一条商品分类数据、一条订单数据,通常用 json 数据结构来表示。每个 index 下的 type,都可以存储多条 document。一个 document 里面有多个 field,每个 field 就是一个数据字段。
{
“product_id”: “1”,
“product_name”: “iPhone X”,
“product_desc”: “苹果手机”,
“category_id”: “2”,
“category_name”: “电子产品”
}
Index
索引包含了一堆有相似结构的文档数据,比如商品索引。一个索引包含很多 document,一个索引就代表了一类相似或者相同的 ducument。
Type
注意, mapping types 这个概念在 ElasticSearch 7. X 已被完全移除,详细说明可以参考官方文档
类型,每个索引里可以有一个或者多个 type,type 是 index 的一个逻辑分类,比如商品 index 下有多个 type:日化商品 type、电器商品 type、生鲜商品 type。每个 type 下的 document 的 field 可能不太一样。
shard
单台机器无法存储大量数据,ES 可以将一个索引中的数据切分为多个 shard,分布在多台服务器上存储。有了 shard 就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个 shard 都是一个 lucene index。
replica
任何一个服务器随时可能故障或宕机,此时 shard 可能就会丢失,因此可以为每个 shard 创建多个 replica 副本。replica 可以在 shard 故障时提供备用服务,保证数据不丢失,多个 replica 还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认 5 个),replica shard(随时修改数量,默认 1 个),默认每个索引 10 个 shard,5 个 primary shard,5 个 replica shard,最小的高可用配置,是 2 台服务器。
这么说吧,shard 分为 primary shard 和 replica shard。而 primary shard 一般简称为 shard,而 replica shard 一般简称为 replica。
ES 核心概念 vs. DB 核心概念
ES DB
index 数据库
type 数据表
document 一行数据
以上是一个简单的类比。
查询阶段包含以下三个步骤:
客户端发送一个 search 请求到 Node 3 , Node 3 会创建一个大小为 from + size 的空优先队列。
Node 3 将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为 from + size 的本地有序优先队列中。
每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是 Node 3 ,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
当一个搜索请求被发送到某个节点时,这个节点就变成了协调节点。 这个节点的任务是广播查询请求到所有相关分片并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
第一步是广播请求到索引中每一个节点的分片拷贝。 查询请求可以被某个主分片或某个副本分片处理, 这就是为什么更多的副本(当结合更多的硬件)能够增加搜索吞吐率。 协调节点将在之后的请求中轮询所有的分片拷贝来分摊负载。
Part2: ES原理
分布式架构原理
ElasticSearch 设计的理念就是分布式搜索引擎,底层其实还是基于 lucene 的。核心思想就是在多台机器上启动多个 ES 进程实例,组成了一个 ES 集群。
ES 中存储数据的基本单位是索引,比如说你现在要在 ES 中存储一些订单数据,你就应该在 ES 中创建一个索引 order_idx ,所有的订单数据就都写到这个索引里面去,一个索引差不多就是相当于是 mysql 里的一张表。
index -> type -> mapping -> document -> field。
你搞一个索引,这个索引可以拆分成多个 shard ,每个 shard 存储部分数据。拆分多个 shard 是有好处的,一是支持横向扩展,比如你数据量是 3T,3 个 shard,每个 shard 就 1T 的数据,若现在数据量增加到 4T,怎么扩展,很简单,重新建一个有 4 个 shard 的索引,将数据导进去;二是提高性能,数据分布在多个 shard,即多台服务器上,所有的操作,都会在多台机器上并行分布式执行,提高了吞吐量和性能。
接着就是这个 shard 的数据实际是有多个备份,就是说每个 shard 都有一个 primary shard ,负责写入数据,但是还有几个 replica shard 。 primary shard 写入数据之后,会将数据同步到其他几个 replica shard 上去。
通过这个 replica 的方案,每个 shard 的数据都有多个备份,保证高可用。
为了协调管理,ES 集群多个节点,会自动选举一个节点为** master 节点**,这个 master 节点其实就是干一些管理的工作的,比如维护索引元数据、负责切换 primary shard 和 replica shard 身份等。要是 master 节点宕机了,那么会重新选举一个节点为 master 节点。
如果是非 master 节点宕机了,那么会由 master 节点,让那个宕机节点上的 primary shard 的身份转移到其他机器上的 replica shard。接着你要是修复了那个宕机机器,重启了之后,master 节点会控制将缺失的 replica shard 分配过去,同步后续修改的数据之类的,让集群恢复正常。
其实上述就是 ElasticSearch 作为分布式搜索引擎最基本的一个架构设计。
写入/查询数据原理及倒排索引
es 写数据过程
客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node (协调节点)。
coordinating node 对 document 进行路由,将请求转发给对应的 node(有 primary shard)。
实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica node 。
coordinating node 如果发现 primary node 和所有 replica node 都搞定之后,就返回响应结果给客户端。
es 读数据过程
可以通过 doc id 来查询,会根据 doc id 进行 hash,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个 shard 去查询。
客户端发送请求到任意一个 node,成为 coordinate node 。
coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
接收请求的 node 返回 document 给 coordinate node 。
coordinate node 返回 document 给客户端。
es 搜索数据过程
es 最强大的是做全文检索,就是比如你有三条数据:
golang真好玩儿啊
golang不好玩
你根据 golang关键词来搜索,将包含 golang 的 document 给搜索出来。es 就会给你返回:golang 真好玩儿啊,golang不好玩。
客户端发送请求到一个 coordinate node 。
协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard ,都可以。
query phase:每个 shard 将自己的搜索结果(其实就是一些 doc id )返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。
写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。
写数据底层原理
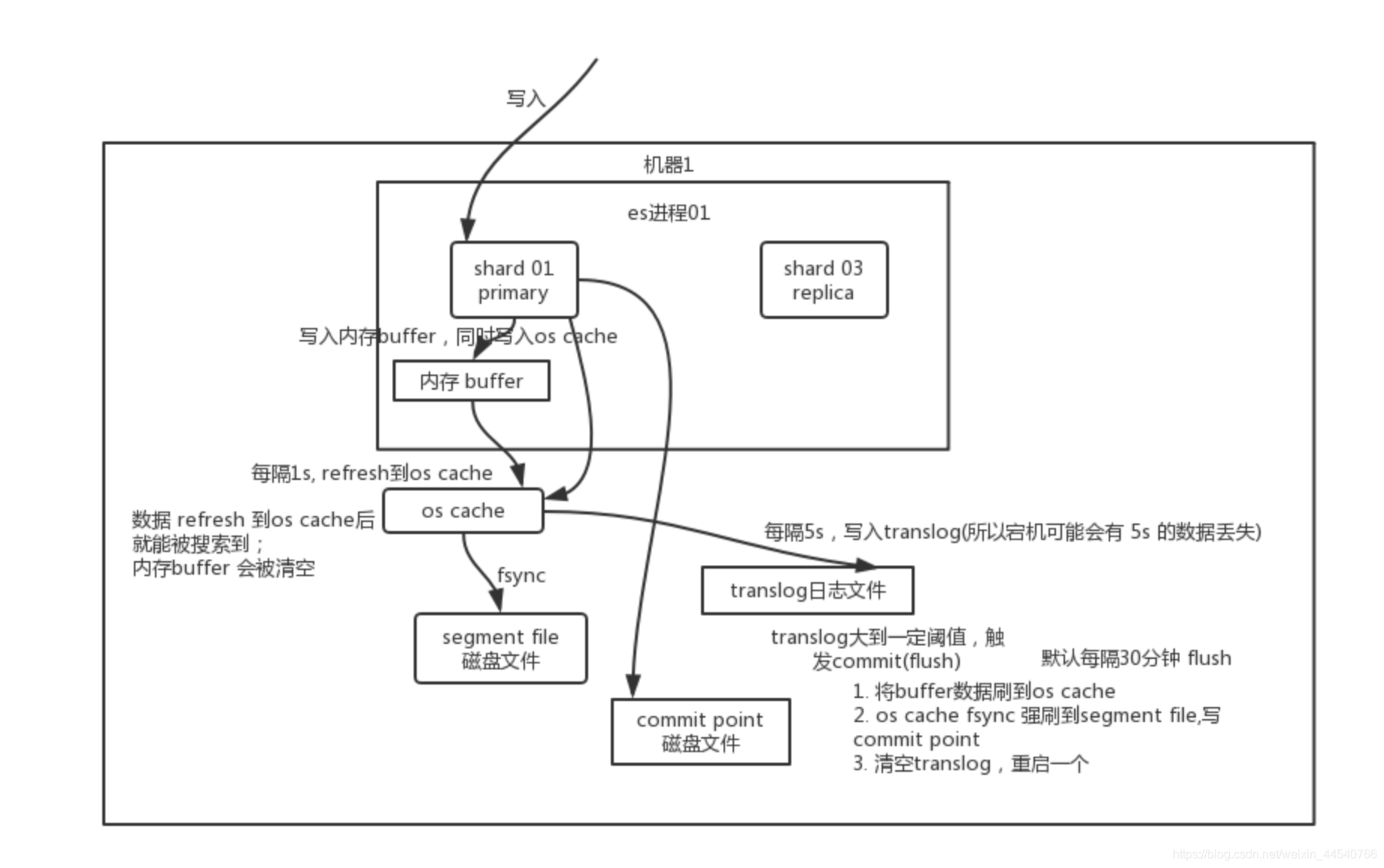
**总结: **数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache,到了 os cache 数据就能被搜索到(所以我们才说 es 从写入到能被搜索到,中间有 1s 的延迟)。每隔 5s,将数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失),translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中。数据写入 segment file 之后,同时就建立好了倒排索引。
倒排索引
在搜索引擎中,每个文档都有一个对应的文档 ID,文档内容被表示为一系列关键词的集合。例如,文档 1 经过分词,提取了 20 个关键词,每个关键词都会记录它在文档中出现的次数和出现位置。
那么,倒排索引就是关键词到文档 ID 的映射,每个关键词都对应着一系列的文件,这些文件中都出现了关键词。
举个栗子。
有以下文档:
DocId Doc
1 谷歌地图之父跳槽 Facebook
2 谷歌地图之父加盟 Facebook
3 谷歌地图创始人拉斯离开谷歌加盟 Facebook
4 谷歌地图之父跳槽 Facebook 与 Wave 项目取消有关
5 谷歌地图之父拉斯加盟社交网站 Facebook
对文档进行分词之后,得到以下倒排索引。
WordId Word DocIds
1 谷歌 1, 2, 3, 4, 5
2 地图 1, 2, 3, 4, 5
3 之父 1, 2, 4, 5
4 跳槽 1, 4
5 Facebook 1, 2, 3, 4, 5
6 加盟 2, 3, 5
7 创始人 3
8 拉斯 3, 5
9 离开 3
10 与 4
… … …
另外,实用的倒排索引还可以记录更多的信息,比如文档频率信息,表示在文档集合中有多少个文档包含某个单词。
那么,有了倒排索引,搜索引擎可以很方便地响应用户的查询。比如用户输入查询 Facebook ,搜索系统查找倒排索引,从中读出包含这个单词的文档,这些文档就是提供给用户的搜索结果。
要注意倒排索引的两个重要细节:
倒排索引中的所有词项对应一个或多个文档;
倒排索引中的词项根据字典顺序升序排列
底层 lucene
简单来说,lucene 就是一个 jar 包,里面包含了封装好的各种建立倒排索引的算法代码。我们用 Java 开发的时候,引入 lucene jar,然后基于 lucene 的 api 去开发就可以了。
通过 lucene,我们可以将已有的数据建立索引,lucene 会在本地磁盘上面,给我们组织索引的数据结构。
一些可以思考的问题:
lucence为什么快?
lucence怎么做的联合查询?比如age=18 and gender=女
以 doc 为最小单位存储,无主键和更新逻辑,有了 Lucene,为何还需要 Elasticsearch?
单机搜索库 ==> 海量分布式?
无更新,仅能 append 新文档 ==> 如何更新?
无主键索引如何更新 ==> 同一个 doc 多次写入?
生成完整 segment 后,不再更改,实时搜索?
Part3: ES使用及实践
本地安装及使用
公司bytees平台提供了boe的kibana,所以可以直接使用boe的kibana.
Boe kibana:http://10.225.89.14:34450/app/kibana#/dev_tools/console?_g=()
Bytees boe说明: https://doc.bytedance.net/docs/366/548/17867/
推荐直接docker安装,避免环境问题。参考「单元测试demo」里的启动本地docker里es脚本,便可以直接使用es了,这里的es是公司镜像平台与日常使用es版本一致的7.0版本
https://code.byted.org/mafulong/testDemo
DSL学习
官方query dsl教程: https://www.elastic.co/guide/en/elasticsearch/reference/current/query-filter-context.html
举几个例子
创建索引
PUT eh_course_online
{
“mappings”: {
“dynamic”: true,
“properties”: {}
}
}
增加记录
PUT eh_course_v1/_doc/1667018228926472
{
“course_id” : 1667018228926472,
“course_type” : 0,
“create_time” : 1589792470000,
“status” : 2,
“title” : “测试标题”,
“category_id” : 1666463972088845,
“category_ids”: [1666463972088845,1666463972160520, 1666463972088870]
}
获取某个docId的内容
GET eh_course_v1/_doc/1667018228926472
查询全部数据
GET eh_course_online/_search
{
}
查询courseId=xx的数据
GET eh_course_v1/_search
{
“query”: {
“bool”: {
“must”: [
{
“term”: {
“course_id”: 1676157294371854
}
}
]
}
}
}
查询 create_time倒序
GET eh_course_v1/_search
{
“sort”: [
{
“create_time”: {
“order”: “desc”
}
}
]
}
删除记录
POST eh_course_online/_delete_by_query
{
“query”: {
“match_all”: {
}
}
}
最佳实践
如何提升性能
https://site.bytedance.net/docs/366/548/30284/
存储容量评估
集群规模评估
分片数量评估
索引创建最佳实践
读性能提升
写性能提升
数据同步(常见的如mysql->es)
Apis(之后不会再维护, 公司推出dsyncer替换): Mysql+elasticsearch异构 --Apis接入ByteES Apis使用手册 Apis-数据实时异构同步系统
DSyncer:DSyncer用户手册,建设中,平台将于之后上线。
举个栗子
最初,需要CMS运营后台需要对course进行标题搜索、状态搜索,有这样一个需求
因此建设数据库->es的同步通道,首先建设es index以及apix同步规则,「同步h_basic->es
Apis同步规则的链接参考」:https://cloud.bytedance.net/sync/bizline/hsync/event/6852228424543502606/mappings/6852231037527802119/rules
同步到es里就可以kinaba上查询数据了http://10.225.89.14:34450/app/kibana#/dev_tools/console?_g=()
GET eh_course_v1/_search
{
“sort”: [
{
“create_time”: {
“order”: “desc”
}
}
]
}
验证es数据正常写入后,golang代码里创建long live的Es client并从es里查询数据, golang sdk: https://site.bytedance.net/docs/366/548/30106/
https://code.byted.org/-/ide/project/h_cloud/knowledge_svr/blob/master/-/libs/es/dal.go
https://code.byted.org/-/ide/project/h_cloud/knowledge_svr/blob/master/-/dal/course_dal.go
这里由于boe的es共用一个集群导致boe的es经常不可用,增加了降级策略通过开关控制查询走mysql,丧失标题全文索引的能力。实际上,目前bytees的boe也可以单独申请集群了。
之后又有一个需求了,根据类目搜索course,类目是什么呢,类目是记录在另一个mysql表的,field有courseId以及tagId等,这个tagId就代表了一个类目,比如说这个course关联了类目“语文"。 因此在course搜索的基础上,将这个类目关联关系表的数据也同步到course搜索的es中,当类目变更时,更新es index。
由于一个course可以关联多个类目id:tagId,筛选时根据多个类目搜索相关联的course列表,因此在一个course的document里对应类目存的是tagId的列表,这样才可以满足需求, 因此需要建设mysql类目关联关系表同步到course es同步规则,这样又有一个新问题,表更新时apis根据binlog触发规则是针对单记录的, 这个问题可以通过rpc调用获取这个courseId所有的tagId列表写入到es中解决。
同步规则: https://cloud.bytedance.net/sync/bizline/hsync/event/6852228750914879758/mappings/6852232298041966861/rules
以上就是所举的一个栗子了,这个例子中通过apis监听两个mysql表的binlog以及通过rpc调用merge成一个“宽表”,同步mysql数据到es中,并使用bytees提供的golang sdk查询es的数据。

















 307
307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









