






作者:坚定的守猴
撰写时间:2019年6月5日
开发软件和关键技术:VS;Word文件转化Html文件及正则提取数据
在项目当中导入数据的方式有很多种,今天我们就来看一下批量导入的方法和思路。
批量导入,它和之前的Excel表格一样,都是得下载原先做好的模板文件。与Excel表格不一样的是,它导入的过程对数据的处理是较复杂一点,因为我们对每份数据的导入都是有格式的,在这个方面如何通过代码让计算机严格按照这种格式顺利地导入数据并且能够保存到数据库里面呢。针对这种情况,我们就得对导入进来的文件进行“翻译”,将我们看的懂Word文件格式“翻译”为计算机能够看的懂的Html文件格式。这就是批量导入的方法的核心。
简单的了解这思路之后,我们就通过一个导入试题的例子实现一下这效果。
每次导入数据它都有对应的注意事项,我们先到页面上了解一下这次导入需要注意哪些内容,找到和上传文件相关的。

看到注意的第一第二条,上传符合的模板文件,对于试题的题型、难度之类的格式与数据库要一致。接下来我们就针对这两条事项进行“翻译”。
第一步:把相对应的模板下载到指定的文件夹

第二步:上传这份文件。把下载好的文件先进行判断,如果是Word文档类型的,则保存到指定的文件夹,然后就把下载好的Word文件转化为Html文件类型。然后通过正则表达式进行读取Html文件。
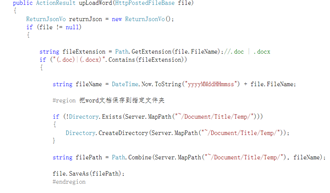
首先采用if的语句判断下载进来的文件是否为Word文档类型的,然后就自定义文件的名字,(为了方便的同时,容易区分多次导入进来的文件,名字就给了它对应的时间。)
通过创建并拼接好路径之后,就将文件保存到对应的文件夹。
接下来就是将Word文档格式转化为Html的文件格式
在此之前,得先引用一个Spire.Doc for.NET的类库。通过它将Word文档类型转化Html文件类型。

首先设置一下将文件转化为Html文件之后对应的文件后缀替换为.html。同样的做法,拼接好存放文件的路径之后,读取文件到指定的文件夹中,然后就将转化为Html的格式文件保存。
文件转化完毕之后,就对这些内容进行读取。
从引用一个IO的类里面调用一个ReadAllText的方法对Html文件里面所有字段进行读取出来。
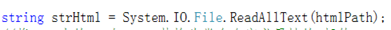
首先就把Html里面的
与
替换为带有自定义属性的p标签。

我们先来看一下Word文档已经转化为Html的文件

第一个为Word文档,第二第三个分别为Html和Css样式文件。我们接下来就是通过正则表达式把Html里面的文本信息给提取出来。
上传的文件里面不但有文字,而且还有图片。所以我们要根据实际情况把存在于文字和图片的p标签和span标签通过正则表达式给匹配出来,获取这些题目的信息。(由于一边讲解Html的p标签和span标签的文件,一边讲解正则较麻烦且会出现语言重复啰嗦,所以就通过图片代码简单讲解一下)
这一步提取所有的P标签,\w\W基本选择所有的字符,\r\n组合使用编辑里面的内容

把提取之后的结果通过声明一个键值对的集合的列表进行保存
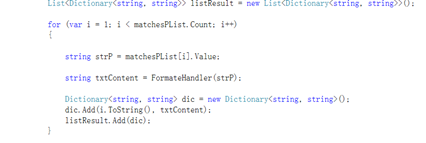
最后就声明一下存放输出数据的变量

然后就获取p标签里面所有的内容
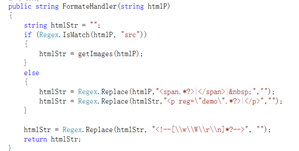
再处理一下带图片的p标签
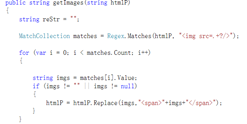
到这里就对需要上传的资料匹配处理完毕。
第三步:将所上传的资料保存到数据库里面
一般我们在上传资料的同时,都会对这些资料进行一个编码加密,这样能够保证这些资料的完整性。不过我们在上传成功之后,把资料保存到数据库里面之前,就得先对这些资料解码。
首先我们看一下在页面对试题进行编码的代码。从图片我们可以知道,实际上编码加密就在上传的后面加一句代码就行了。并不会是很复杂的那种处理。

在上传成功之后,我们就对这些数据进行处理
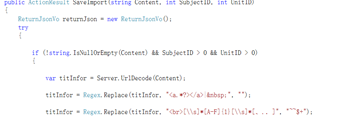
对试题解码之后,就去掉题目中用不上的a标签和空格,之后用正则表达式匹配好的题目答案结果通过替换的方式用$表示出来。
在导入数据的过程,避免匹配的过程中出现多条重复的数据,保证数据的唯一性。我们就对数据进行声明类型列表进行处理。
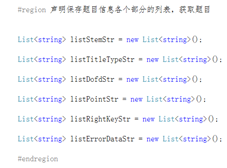
我们就把这些题目就按类型分好对应的列表(依次是题目信息,题目类型列表,难度列表,知识点列表,正确答案列表,错误数据列表),把我们需要匹配的题目就拿出来进行匹配,出现匹配错误的就把它们放到一个列表里面。这样保证匹配数据的有序性和准确性。
我们现在看一下转成Html文件的试题状态(截取一部分内容)

样式和文字都混在一起,每一道题目转换成Html就是按照现在杂乱无章的拼接在一起。所以呢,为了提取我们需要的题目信息,我们就对这些题目进行分割处理。
我们在分割之前,先从Html文件里面把每一道题目匹配出来,然后if语句判断是否匹配成功之后,获取对应的题目信息。

匹配一道完整的题目之后,我们就对它们进行分割。

声明匹配汉字的方法。把所有非汉字的符号去掉。

匹配成功之后就对获取到这些题目的数据保存到对应的列表当中。等上面的数据都处理完毕之后就保存到listData这字符串变量里面。
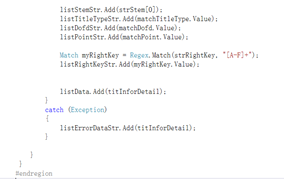
保存好处理的数据,那就根据题目表在数据库里面的格式导进去了

因为题目表里面有难度系数等这些表的外键,所以保存试题的里面有关于这些数据可以集合到题目表里面进行保存。

实例化一个保存试题表的列表

这就有点类似导入Excel表格那样,先把表头的属性创建好,然后就把对应属性的数据导入进去之后,就把表格对象放入创建好的试题表的列表里面。
接下来对于这些数据进行两个判断。第一就是对导入的试题重复的判断;
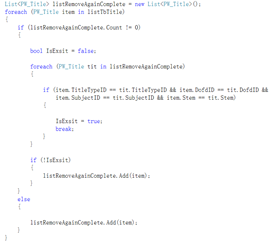
遍历查询listTbTitle导进来的试题列表和刚创建的listRemoveAginComplete里面的试题列表进行比较(除了第一条数据,因为刚创建的表里面没有比较值,所以判断不了),判断与已经导进创建列表的试题比较是否重复。下面有两个if语句的判断,第一个就是比较之后有相同的数据那就终止循环(break);第二则是在第一个if情况相反而执行,没有相同的数据就新增进去(Add)。
第二判断就是去掉与数据库重复的试题
思路和代码与第一个大同小异。

首先也是遍历查询数据库里面所有试题信息,声明一个存放与数据库试题不重复的列表。不同的是,这次要把试题里面的图片给去掉,不能进行判断。因为所有图片一般都不可能来自于同一个路径,所以在这里面就没有可比较性。所以采用一个if语句判断,把试题出现的图片文件用正则表达式给替换掉。之后那两个if语句判断和上面第一个基本一样的。
完成试题文本导入的判断。就是处理图片路径的存放了。在刚开始的时候,我们在下载模板的时候就是创建一个临时文件夹存放图片。现在就是把存放在临时文件夹的图片移动专属于图片的文件夹。

从上面处理完试题列表的试题信息获取到原来地址的图片文件名的对象,然后就进行图片的判断,通过正则把原来的图片路径匹配出来,同时把新图片的路径也给匹配出来,然后就进行路径之间的替换。路径替换完毕,采用try catch语句捕获图片文件从旧路径移动到新路径的异常。
经过上面一系列的操作,把这些处理好的试题信息进行保存
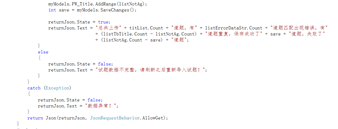
因为这次导入的数据是多条,与之前单条导入不同。所以添加那里采用AddRange的语法(Add是单条数据的添加)。在保存成功那里的文本提示,计算出保存数据的具体情况。这里面都有记录题目对应的列表,titleList是在上面分割题目获取题目的总条数。
在进行题目分类的时候,创建了一个listErrorDataStr题目匹配错误的列表,在这一系列的操作,负责收集并存放这些不符合要求的数据,到保存这里反馈一下这些不符合要求题目的数量。ListTbTitle是把试题分割处理完之后,是去重复之前的数据,而listNotAg是去完两次重复判断的数据,所以就通过重复前的数据减去重复后的数据,就得出重复数据的条数。成功的条数sava返回保存好的数据。而失败的条数就是去重复之后的数据减去成功的条数得出。
思路和代码介绍完了,我们看一下这效果如何。
按照上面代码的思路来进行,下载模板→导入试题→保存试题,就这样就进行测试一下。
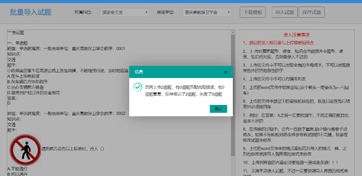
经过上面的思路操作之后,从模板那里导入两道题目,对这些题目进行处理之后,最后保存成功就反馈想要的信息。然后再到页面的试题库检查一下

对应题目类型,选中这两条题目,确认是成功导入了刚才那两道题目(在“详情那里可以看到题目详细信息,确认导入成功之后在这里就不统一截图了)”。
以上就是批量导入的所有内容了,当中可能有部分操作介绍不够详细,所以如有其它疑问,欢迎询问。















 985
985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









