







前言
select和epoll都可以用来实现高并发TCP服务器,但是它们的实现方式有一些不同。
在select模型中,我们需要将需要监控的文件描述符全部加入一个fd_set结构中,并对其进行轮询,查看其中是否有文件描述符的状态发生了变化。
而在epoll模型中,我们只需要将需要监听的文件描述符添加到epoll实例中,当文件描述符状态发生变化时,epoll_wait函数会返回相应的事件数据。
因此,与select模型相比,epoll模型更加高效。因为在select模型中,每次轮询需要遍历整个fd_set集合,而在epoll模型中,只需要对发生变化的文件描述符进行处理,节省了大量CPU时间和内存开销。
另外,select模型最多只能同时监听1024个文件描述符,而epoll没有这个限制,可以同时监听上百万个文件描述符,所以epoll更适合实现高并发的网络编程。
原理部分已经在之前的博客上详细说明了:
io多路复用原理
下面通过代码的方式实现这两个模型,以便更好的观察他们的不同
一、select/poll
1、函数底层原理
在调用select函数后,它会处于阻塞状态。当有文件描述符的状态发生变化时(比如有新的连接进来或者已连接的socket可读或可写),select将返回,并且返回值ret表示状态发生变化的文件描述符数量。
如果没有任何文件描述符发生变化,并且select等待超时(如果为NULL表示永远等待,否则表示等待一定时间),则ret返回0。
如果出错,ret返回-1,并且errno设置为对应的错误码。
2、详细步骤
1、创建一个套接字,并将其绑定到9999端口上所有网络接口。然后它调用listen()监听来自客户端的连接。
2、然后使用FD_ZERO()初始化一个文件描述符集fdset,并使用FD_SET()将监听套接字lfd添加到该集合中。它还跟踪最大文件描述符maxfd。
3、进入一个循环,通过调用select()等待任何文件描述符有数据准备好。如果select()指示某个文件描述符准备好:
4、是监听套接字lfd,这意味着有新的客户端连接。它使用accept()接受连接,并将新的客户端套接字cfd添加到文件描述符集fdset中。更新maxfd。
5、对于任何其他准备好的文件描述符i,它使用read()从客户端读取数据。如果读取0字节,则客户端已关闭连接,并从rdset中删除该文件描述符。否则,它使用write()将数据回显给客户端。
3、代码
// 创建socket 绑定地址 服务器端 绑定任何地址就是网卡中的ip 然后监听
int lfd = socket(PF_INET, SOCK_STREAM, 0);
ErrorP(lfd, "socket");
struct sockaddr_in saddr;
saddr.sin_family = AF_INET;
saddr.sin_port = htons(9999);
saddr.sin_addr.s_addr = INADDR_ANY;
int ret = bind(lfd, (struct sockaddr*)&saddr, sizeof(saddr));
ErrorP(ret, "bind");
ret = listen(lfd, 128);
ErrorP(ret, "listen");
//定义一个set集合 存放需要检测的文件描述符
// 创建一个fd_set的集合,存放的是需要检测的文件描述符
fd_set fdset, tmp;
FD_ZERO(&fdset);
// 置1
FD_SET(lfd, &fdset);
// 最大符号位置
cout<<"lfd:"<<lfd<<endl;
int maxfd = lfd;
while (1) {
// select
// 调用每次完成测试之后,内核都会修改描述符集合,通过修改完的描述符集合来和应用程序交互,
// 应用程序使用 FD_ISSET
// 来对每个描述符进行判断,从而知道什么样的事件发生。
tmp = fdset;
// 调用select系统函数,让内核帮检测哪些文件描述符有数据
// 第五个参数为null一直阻塞直到 有文件描述符准备好
int ret = select(maxfd + 1, &tmp, NULL, NULL, NULL);
cout<<"///"<<ret<<endl;
if (ret == -1) {
perror("select");
exit(-1);
} else if (ret == 0) {
continue;
} else if (ret > 0) {
// 说明检测到了有文件描述符的对应的缓冲区的数据发生了改变
if (FD_ISSET(lfd, &tmp)) {
// 判断fd对应的标志位是0还是1, 返回值 :
// fd对应的标志位的值,0,返回0, 1,返回1
// 是1表示有新的客户端连接进来了
cout << "new client connet.." << endl;
struct sockaddr_in cliaddr;
int len = sizeof(cliaddr);
int cfd =
accept(lfd, (struct sockaddr*)&cliaddr, (socklen_t*)&len);
cout<<".."<<cfd<<endl;
// 将新的文件描述符加入到集合中
FD_SET(cfd, &fdset);
// 更新最大的文件描述符
maxfd = maxfd > cfd ? maxfd : cfd;
}
cout<<"遍历 所有的文件描述"<<endl;
// 遍历 所有的文件描述符 是1 的时候 就是需要传输额的
for (int i = lfd + 1; i <= maxfd; i++) {
cout<<"."<<i<<endl;
if (FD_ISSET(i, &tmp)) {
// 说明这个文件描述符对应的客户端发来了数据
char buf[1024] = {0};
int len = read(i, buf, sizeof(buf));
if (len == -1) {
perror("read");
exit(-1);
} else if (len == 0) {
printf("client closed...\n");
close(i);
// 变成0
FD_CLR(i, &fdset);
} else if (len > 0) {
printf("read buf = %s\n", buf);
write(i, buf, strlen(buf) + 1);
}
}
}
}
}
close(lfd);
二、epoll
1、函数底层原理
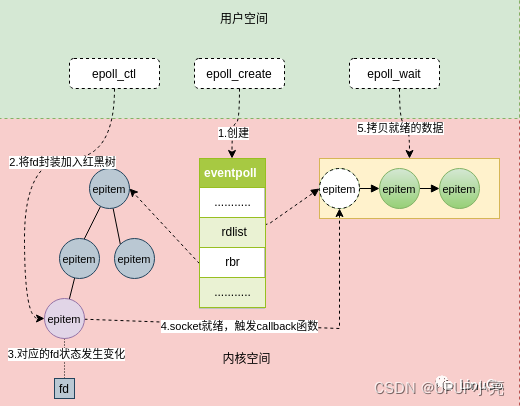
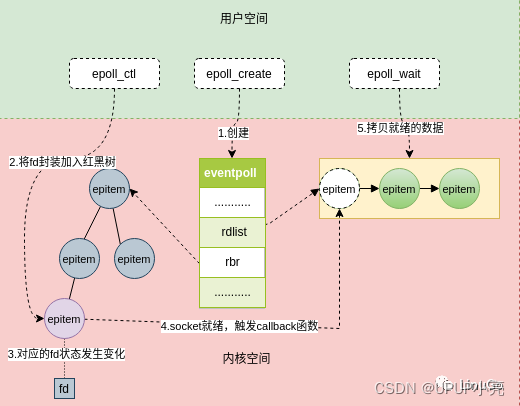
epoll_wait()函数使用epoll机制实现,epoll机制使用一个内核管理的事件表来存储关注的事件,每个文件描述符对应一个事件结构体。当文件描述符状态发生变化时,内核会将对应的事件结构体添加到一个就绪链表中。epoll_wait()函数会从就绪链表中取事件结构,并将其转换为用户空间的epoll_event结构体,返回给调用者。
2、详细步骤
1、创建一个套接字,并将其绑定到9999端口上所有网络接口。然后它调用listen()监听来自客户端的连接。
2、创建一个epoll实例epfd,并将lfd添加到epfd列表中进行监听。
3、进入无限循环,等待epfd列表中文件描述符状态改变。
4、调用epoll_wait函数等待文件描述符状态改变,当有文件描述符准备就绪时,返回准备就绪的文件描述符数目,并将这些文件描述符对应的epoll_event结构体存入epevs数组中。
5、遍历epevs数组,处理每一个准备就绪的文件描述符。如果是lfd,说明有新的客户端连接请求到来,需要调用accept函数接受连接请求,并将cfd加入epfd列表中进行监听。如果是已连接的客户端文件描述符,说明有数据到达,需要进行读、写或异常处理。
6、在读事件处理中,使用read函数读取数据,如果读取失败或读取到0字节,说明客户端已关闭连接,需要将cfd从epfd列表中移除,并关闭cfd文件描述符。如果读取成功,使用write函数将数据回传给客户端。
3、代码
// 创建socket 绑定地址 服务器端 绑定任何地址就是网卡中的ip 然后监听
int lfd = socket(PF_INET, SOCK_STREAM, 0);
ErrorP(lfd, "socket");
struct sockaddr_in saddr;
saddr.sin_family = AF_INET;
saddr.sin_port = htons(9999);
saddr.sin_addr.s_addr = INADDR_ANY;
int ret = bind(lfd, (struct sockaddr*)&saddr, sizeof(saddr));
ErrorP(ret, "bind");
ret = listen(lfd, 128);
ErrorP(ret, "listen");
// 首先创建一个epoll实例
int epfd = epoll_create(100);
// 将需要监听的文件描述符加入实例中
// 把这里创建的文件描述符 加入EPOLL_CTL_ADD 然后 监听读事件
// epoll_event 结构体 事件是读取
struct epoll_event epev;
epev.events = EPOLLIN;
epev.data.fd = lfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, lfd, &epev);
// 定义检测到文件描述符改变的存储数组 后面直接遍历这个就行了
struct epoll_event epevs[1024];
while (1) {
// 调用wait 检测哪些 文件描述符进行变化了ret 返回的是
// epfd列表中改变的数目 改变的就放进epevs 需要遍历
int ret = epoll_wait(epfd, epevs, 1024, -1);
if (ret == -1) {
perror("epoll_wait");
exit(-1);
}
cout << "nums:" << ret << endl;
// 开始遍历 所有改变的文件描述符
for (int i = 0; i < ret; i++) {
// 这是第i个改变的文件描述符
int curfd = epevs[i].data.fd;
if (curfd == lfd) {
// 关键****改变的如果是 服务器的文件描述符
// 检测到lfd 改变 就是检测到需要监听的文件描述符改变了
// 就说明有客户端连接
// 需要把客户端传过来的文件描述符传进去epfd列表***
cout << "new client!!!!!!!" << endl;
struct sockaddr_in cliaddr;
int len = sizeof(cliaddr);
int cfd =
accept(lfd, (struct sockaddr*)&cliaddr, (socklen_t*)&len);
// 把cfd 客户端文件描述符加入epfd 进行检测
epev.events = EPOLLIN;
epev.data.fd = cfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, cfd, &epev);
} else {
if (epevs[i].events & EPOLLOUT) {
// 这个是写事件的时候 忽视
continue;
}
// 有数据到达,需要通信
char buf[1024] = {0};
int len = read(curfd, buf, sizeof(buf));
if (len == -1) {
perror("read");
exit(-1);
} else if (len == 0) {
printf("client closed...\n");
// 关闭就删除
epoll_ctl(epfd, EPOLL_CTL_DEL, curfd, NULL);
close(curfd);
} else if (len > 0) {
printf("read buf = %s\n", buf);
write(curfd, buf, strlen(buf) + 1);
}
}
}
}
// 最后关闭服务器的文件描述符和 epfd epoll实例
close(lfd);
close(epfd);
三、测试
epoll测试
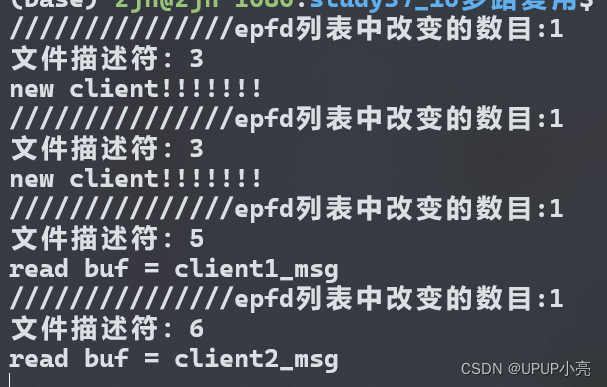
输出准备就绪的文件描述符数目,以及实哪些文件描述符就绪。

分别然客户端1连接然后然客户端2连接,然后连个客户端分别传输数据给服务器。可以看到每当有新文件事件发生的时候就会把发生**改变的epoll_event放入到数组中。**然后再遍历这个数组拿到对应的文件描述符。
select测试
一样的首先打印需要输出的,然后分别然客户端1连接然后然客户端2连接,然后连个客户端分别传输数据给服务器。结果显示,每次都要遍历所有的文件描述符,不管他有没有发生变化。

总结
epoll_wait函数和select函数是Linux系统中实现I/O多路复用的两种常用方法,它们的底层原理和实现有所不同。
epoll_wait函数的底层原理和实现:
-
内核中的数据结构:在Linux内核中,使用了一个叫做红黑树的数据结构,用于存储需要监听的文件描述符以及相关的事件信息。同时,还用一个叫做就绪链表的数据结构,用于存储准备就绪的文件描述符以及对应的事件信息。
-
系统调用:当应用程序调用epoll_wait函数时,系统会将该进程的控制权交给内核,并将该进程的epoll实例中红黑树中的文件描述符和事件信息复制到内核空间中的一个数据结构中。然后,内核会检查每一个文件描述符的状态,如果有文件描述符准备就绪,就将其加入到就绪链表中。
-
用户空间和内核空间之间的数据传输:当内核检查完所有的文件描述符后,就会将就绪链表中的文件描述符和对应的事件信息复制回用户空间,存储在epoll_event结构体数组中,并返回准备就绪的文件描述符数目。
-
应用程序的处理:当应用程序收到epoll_wait函数的返回值后,就可以遍历epoll_event结构体数组,处理每一个准备就绪的文件描述符,进行读、写或异常处理。
select函数的底层原理和实现:
-
文件描述符集合:在Linux内核中,使用了一个叫做fd_set的数据结构,用于存储需要监听的文件描述符。这个数据结构的大小由FD_SETSIZE宏定义决定。
-
系统调用:当应用程序调用select函数时,系统会将该进程的控制权交给内核,并将该进程的文件描述符集合和超时时间复制到内核空间中的一个数据结构中。然后,内核会检查每一个文件描述符的状态,如果有文件描述符准备就绪,就将其加入到另一个文件描述符集合中。
-
用户空间和内核空间之间的数据传输:当内核检查完所有的文件描述符后,就会将准备就绪的文件描述符集合复制回用户空间,存储在原来的文件描述符集合中,并返回准备就绪的文件描述符数目。
-
应用程序的处理:当应用程序收到select函数的返回值后,就可以遍历文件描述符集合,处理每一个准备就绪的文件描述符,进行读、写或异常处理。
区别:
文件描述符数量限制:在Linux系统中,select函数的文件描述符数量是有限制的,通常为1024或更小,而epoll没有这个限制,可以支持更多的文件描述符。
检测效率:在文件描述符数量比较大的情况下,epoll的检测效率要比select更高,因为epoll是基于事件驱动的机制,只有当文件描述符状态发生变化时才会通知应用程序,而select则需要轮询所有的文件描述符,检查是否有可读、可写或异常事件发生。
内核空间和用户空间的数据拷贝:在使用select函数时,每次调用select都需要将文件描述符集合从用户空间拷贝到内核空间进行检测,而在epoll中,只需要将需要监视的文件描述符添加到epoll实例中,不需要每次都进行数据拷贝,因此epoll的效率更高。
内存占用:在文件描述符数量比较大的情况下,使用select会占用比较大的内存空间,因为需要创建一个文件描述符集合,而epoll则只需要创建一个epoll实例,占用的内存空间较小。
综上所述,epoll在处理大量文件描述符的情况下,具有更高的效率和更低的内存占用,因此在实际应用中,epoll更常用。但是在文件描述符数量比较小的情况下,select的性能表现比较接近于epoll,选择哪种机制可以根据具体的应用场景来决定。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









