






1.背景由来
1.1:现实中大量数据无标签
1.2 Semi-supervised分为两大类:U远大于R
- 直推学习:Transductive learning ,无标签数据是testing data
- 归纳学习:Inductive Learning,无标签数据不是testing data
2.Why Semi-supervised Learning?
- 收集数据往往是很容易的,但是收集有标签的数据却是很难的,
- 现实中的数据就是半监督的,每次我们都只是被告诉某类物品的部分样品的标签,但是我们自己对后面看到的物品进行学习

先让我们看看监督学习和半监督学习的生成模型的对比,(Supervised Generative Model VS Semi-supervised Generative Model)
根据高斯估测𝜇, Σ,然后就可以估测出一个新的data属于哪类


从上图可以看出,无标注数据有助于重新估计生成模型假设中的参数,从而影响决策边界
求解模型采用的方法:
求解该模型采用的是EM算法,EM算法也是机器学习十大算法之一,求解步骤如下图所示:
2.1 假设
半监督学习方法一般都具有某些假设,半监督学习方法有没有作用,取决于这些假设的正确程度。
猫狗边界:

2.2 生成过程:Semi-supervised Learning for Generative Model
半监督学习的生成模型,一般可以分为三步:
- Initialization 随机初始化模型参数
- compute the posterior probability of unlabeled data 计算无标签数据的分类概率;
3.update model 根据无标签数据的分类概率更新所有参数,重复步骤以上
算𝑃 �和𝜇1
这个是无标签数据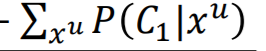

把这个地方的参数都更新一下,然后i几率就不一样了,就upde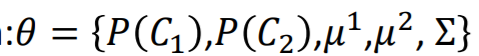
理论上,这个方法会收敛,初始化很重要。
那这个方法为什么会表现成这样?
有label data时最大化likelihood,有 没标签数据后狮子区别看一下,一笔无标签数据=属于c1+c2的几率

2.3:使用.Semi-supervised Learning的原因:
最大化该样本出现的原因,监督学习是可以得到最优解的,但是由于半监督方法中的优化函数不是凸函数,即不能得到最优解,所以只能迭代求解。
3.两个重要假设:
半监督学习基于两个重要的假设
- Low-density Separation Assumption:非黑即白
即两个不同种类之间的界限明晰,即在交界处的样品密度较低——Low-density Separation。基于该假设的一种典型实现就是self-training。但是这种方式对regression是没有作用的,因为新得到的y^u不会改变模型参数

1.1该假设的应用过程如下:
- 给你一堆初始数据,该数据包括有标记和无标记的
- 从有标记的数据中训练出一个模型f*.
- 从数据中选出一些无标记的数据,将这些数据扔入模型f*中,将得到的结果赋予这些无标记的数据的标签,然后将这些数据从无标记数据集中删除并加入有标记的数据集中,重复此过程。
Regression?是output一个数字

1.2Self-training结果优化:
如果神经网络的输出是一个分布,我们希望这个分布要集中
self-training与Generative model的差别是,前者使用的是hard label,后者使用的是soft label。如果使用neural network的话,应该使用hard label,这样它才会工作。因为这是一个非黑即白的世界,有点像,也是,0.3不work

外一种实现方式:Entropy-based regularization,保证最终学到的无标签数据界限清晰,样本属于某一类的可能性最大。
因为非黑即白太绝对,通过不断缩小Entropy来更新模型

- Smoothness Assumption近朱者赤,近墨者黑
相似的样本之间具有相同的label,且样本之间有个“high density region高密度区”,也就是说下图中x_1和x_2虽然距离较远,但是它们中间有个高密度的路径相连。核心思想:假设特征的部分是不均匀的(在某些地方集中,某些地方分散),如果两个特征在高密度区域是相近的,那么二者的标签是相同的。
x1和想x2之间有很多集中分布的状态,那他们两就很像

实现方式:
最简单:
就是cluster then label,但是这种方法很依赖于cluster,因为在图像上做cluster是一件比较难的事情。

这种方法有明显的缺点:它只适用于每个class的分类较为清晰。所以引入另外一种办法
Graph-based approach:基于图的方法,是将样本之间的联系看成是两点之间具有相连的路径,有些两点之间连接的路径是很自然的,比如论文中的引用等待。
每一笔data都建立graph,相联就 相似,
自然的graph

先定义两个data想办法算相似度,然会建graph,算出各自相似度,把形似都大于1的连起来。
确定路径的方式:KNN,e-neighbor等方式来确定是否有路径连接(有点类似于hard label);或者用两者之间的 相似程度(soft label)来确定路径的权重,确定方式可以用Gaussian Radial Basis Function(径向基函数),可以让距离稍近的两个点比距离稍远点两个点的权重大很多,保证差异性。

假设有两把data属于class1,那相邻邻居也可能是class1,所以会像传染病一样传递下去,

以上是定性的例子,
下面看定量:可以看到11比较平稳,下面就一个东西定量的去描述
只有1-0的后面才不是0,

在graph-based 方法上定义smoothness of the label,对于所有的data,两样本之间的label之差的平方乘以权重求和,这个值越小表明越smoothness。
可以用拉普拉斯矩阵来表示这个function
最终在训练时,可以将监督学习的误差和smoothness of label的值结合起来表示,后者作为regularization term来调节,可以放在每一层中进行smooth,具体可由情景而定。
- Looking for better representation:找到表面观察背后的隐含特征,更好地表示这个物体。
.














 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









