






来源于李沫的课,做一个笔记。
AlexNet赢得了2012年ImageNet竞赛。
本质上是一个更深更大的LeNet,与LeNet在架构上上没有太多本质的区别。
主要改进是:加入了丢弃法。它的激活函数从LeNet的sigmoid变成了ReLu。LeNet主要用的是平均池化,AlexNet用的最大池化。丢弃法是做模型的控制,因为模型更大了所以会用丢弃法做正则。Relu与sigmoid相比梯度更大,Relu在零点处的一阶导更加好,能支持更好的模型。最大池化取得是最大值,使得输出更大,梯度也就更大,训练更加容易。
AlexNet不仅仅是更大更深,带来了计算机视觉方法论的改变。
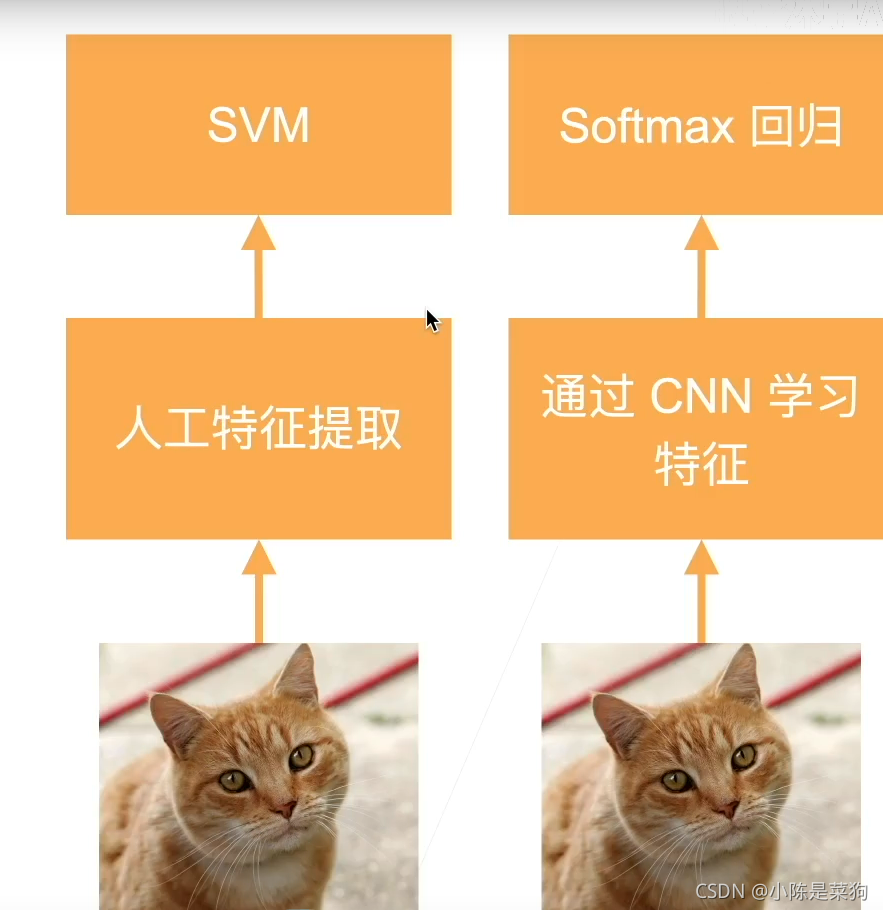
从过去人工抽取特征改变成为制造一个端到端的学习。从原始的数据到最后的分类直接通过深度神经网络一路过去。

















 2012
2012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









