




首先说明为什么用pytorch实现该算法:因为暑假里尝试过在cpu里运行的简陋版本,运行速度过于缓慢;pytorch中有现成的embedding方法可以使用并且做梯度下降比较容易。
下面先说核心算法部分:
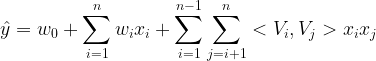
这里的时间复杂度仍为o(kn^2),下面是化简到o(kn)

具体实现:
class FactorizationMachine(nn.Module):
def __init__(self, field_dims, embed_dim=4):
super(FactorizationMachine, self).__init__()
self.embed1 = FeaturesEmbedding(field_dims, 1)
self.embed2 = FeaturesEmbedding(field_dims, embed_dim)
self.bias = nn.Parameter(torch.zeros((1,)))
def forward(self, x):
# x shape: (batch_size, num_fields)
# embed(x) shape: (batch_size, num_fields, embed_dim)
square_sum = self.embed2(x).sum(dim=1).pow(2).sum(dim=1)
sum_square = self.embed2(x).pow(2).sum(dim=1).sum(dim=1)
output = self.embed1(x).squeeze(-1).sum(dim=1) + self.bias + (square_sum - sum_square) / 2
output = torch.sigmoid(output).unsqueeze(-1)
return output最后附上全部代码:
FM.py
from utils import create_dataset, Trainer
from layer import Embedding, FeaturesEmbedding, EmbeddingsInteraction, MultiLayerPerceptron
import torch
import torch.nn as nn
import torch.optim as optim
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('Training on [{}].'.format(device))
dataset = create_dataset(sample_num=100000, device=device)
field_dims, (train_X, train_y), (test_X, test_y) = dataset.train_valid_test_split()
class FactorizationMachine(nn.Module):
def __init__(self, field_dims, embed_dim=4):
super(FactorizationMachine, self).__init__()
self.embed1 = FeaturesEmbedding(field_dims, 1)
self.embed2 = FeaturesEmbedding(field_dims, embed_dim)
self.bias = nn.Parameter(torch.zeros((1,)))
def forward(self, x):
# x shape: (batch_size, num_fields)
# embed(x) shape: (batch_size, num_fields, embed_dim)
square_sum = self.embed2(x).sum(dim=1).pow(2).sum(dim=1)
sum_square = self.embed2(x).pow(2).sum(dim=1).sum(dim=1)
output = self.embed1(x).s 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









