





文章目录
论文地址
ABSTRACT
本教程的目标是在研究和实践中向观众介绍云数据系统ML的最新技术。本教程分为两部分:进展和前进道路。
第一部分介绍了最近在为云数据系统部署机器学习解决方案方面取得的成功。我们将讨论考虑到的实际因素以及在各个层面取得的进展。目的是将ML对系统的承诺与工业实际覆盖的领域进行比较和对比。
最后,第二部分讨论了机器学习在企业中的实际问题,包括解释的生成、模型调试、模型部署、模型管理、对数据使用和匿名的限制,以及通过机器学习和企业中的模型而产生的技术债务。
1 INTRODUCTION
现代云已使对复杂和可扩展数据处理系统的访问民主化。与长时间的硬件和软件采购周期不同,在进行任何数据处理之前,现代云已经将数据处理能力转变为即时满足的商品——最先进的数据处理堆栈只需点击几下就可供使用。除了快速资源调配外,云还提供托管数据服务,其中许多操作任务由云提供商负责。这些可能包括安全性、更新、备份、放大或缩小、可靠性、跟踪和对各种系统的支持等,从而使系统用户的生活更加轻松。最后,无服务器数据处理基础设施出现了一种新的趋势,它进一步免除了用户决定和支付固定资源配置集的费用。相反,云提供商负责为每个用户任务分配资源,他们只为实际发生的处理付费。所有这些都使得云成为数据处理规模和复杂性的目标。
不幸的是,向现代云的转变也带来了新的痛苦。如今,即使是非专家用户也可以快速将各种云数据服务组合到高度复杂的应用程序工作流中,但他们很快意识到在拼接、配置、调优、调试、分析或充分利用其数据服务方面的挑战。这是因为云用户通常不具备专业知识或领域知识,也不具备访问传统上由本地雇用的数据库管理员(DBA)的权限,甚至不具备对托管服务中低级系统组件的控制。这不仅对最终用户来说是痛苦的,而且对云提供商来说也是痛苦的,因为他们现在有责任提供良好的用户体验。此外,云数据系统最终也会有太多的移动部分,具有更多的虚拟化和抽象层,这使得它们更难管理和调整,让用户和/或云提供商处理不可行的决策空间,解决次优性能问题,但最终会带来更高的运营成本。所有这些都成为云覆盖的关键领域,因为它将迎接下一波数字转型,使企业保持相关性和竞争力,以及下一级别的客户期望,包括更高的服务质量(QoS)和更低的总体拥有成本(TCO)。
幸运的是,云数据系统还有一个不公平的优势:它们可以看到大量工作负载,这些负载捕获了许多不同用户和应用程序之间的异构性,以及随时间的变化。这种全球可视性加上机器学习(ML)工具和库、端到端系统控制和更快的发布周期的进步,具有多方面的意义。首先,推动云数据系统由数据驱动,即从直觉和猜测转向可量化的见解。其次,有机会在云数据系统中引入自调整反馈循环,即从过去的情况中学习,并将其应用于未来的工作负载。第三,随着时间的推移,需要将云数据系统发展到更新的用户需求、工作负载类型、硬件设计和其他方面,即适应新的趋势和现实。事实上,利用云的可观察性来不断学习和改进系统行为正迅速成为现代云数据系统的设计原则,并为重建承诺的云(即更简单、更快和更便宜的云)提供了巨大潜力。
在本提案的其余部分中,我们概述了教程的两个部分,即进展和前进道路。
2 THE PROGRESS
ML对系统的新发现的兴奋始于学习索引的情况。此后,学术界和研究界就如何将ML集成到几乎任何系统层上提出了大量想法。然而,在工业领域,随着这些想法在产品中的强化,节奏会更加规范。在本教程中,我们简要介绍了在云数据系统中使系统ML更接近实践方面所取得的进展。为了实现这一点,我们将把云数据系统表示为四个不同的层次(图1),一个层次一个层次。
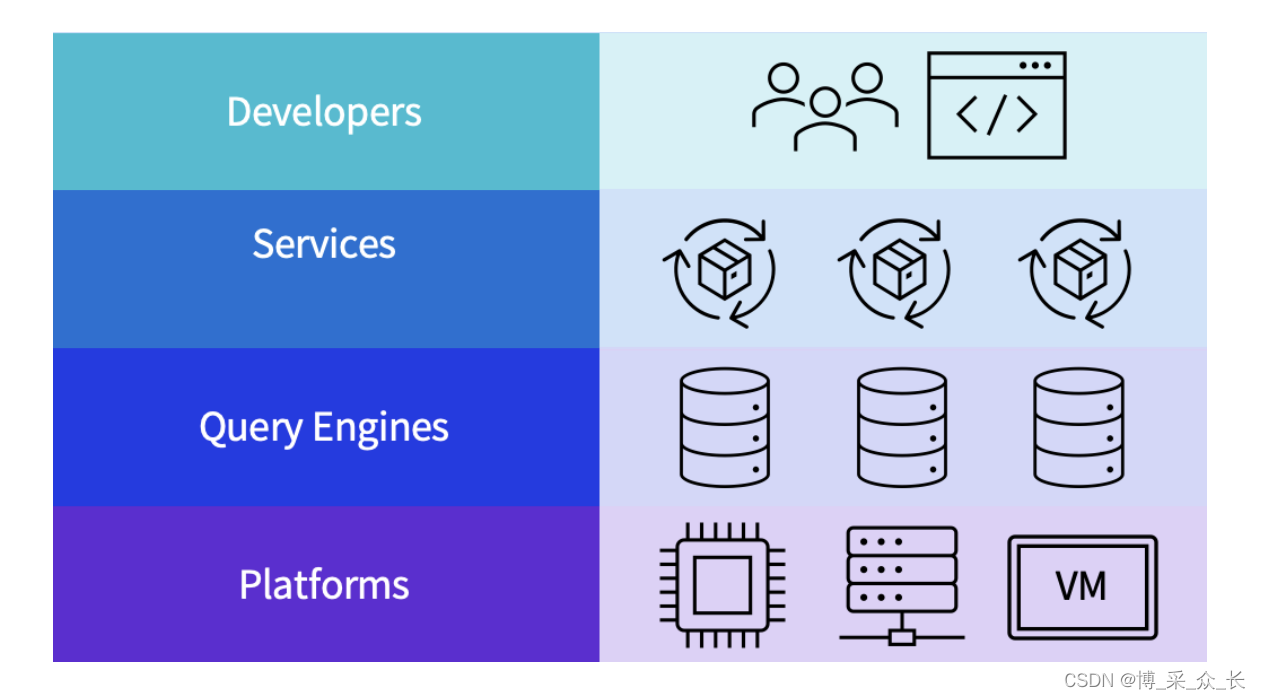
- 在底层,我们有云平台(第2.1节)。这一级别的ML解决方案试图解决以下问题:什么是适合我工作负载的机器SKU?在当前负载下,我们如何满足VM配置SLA?
- 查询引擎(第2.2节)在云平台上运行。在这个级别上,有几个有趣的组件可以使用ML进行调优。一般来说,在这个级别上,我们想知道我们可以从过去的查询工作负载中学到什么?未来我们如何改进查询计划?
- 查询引擎上可以使用更高级别的云服务(第2.3节)。在这个层次上,云客户对一些问题的解决方案感兴趣,例如高峰和低负荷间隔是什么?我们什么时候备份?考虑到当前的工作负载,最佳的扩展策略是什么?
- 最后,开发人员(第2.4节)是上述所有级别的最终用户。在这个层次上,我们将探索一些工作,回答一些问题,例如如何在我的项目中注入数据科学?当ML是我的软件的一部分时,端到端的体验是什么?如何利用ML提高效率?
接下来,我们将双击从云平台自下而上开始的每个级别。
2.1 Platforms
云平台通常很大,而且通常很笨重。因此,专门为优化硬件(SKU设计、功率封顶)和软件(每台机器的容器和其他软件配置)而设计的框架开始出现。例如,可以使用各种虚拟机级特征(如存储类型、网络、CPU等)来建模性能,选择最佳的云配置,或选择闪存。下一步是研究云跟踪,并根据以前的工作负载提供建议。事实上,云工作负载通常是反复出现的,因此过去的跟踪很好地近似于未来的负载。在这一点上,应用ML是自然的下一步。事实上,ML在云平台和资源管理中的应用仍处于初级阶段,但前提条件很吸引人,而且趋势是存在的。群集级调整已成为Cosmos的一部分,在Azure中通过机器学习改进了资源管理,在将SQL Server从本地迁移到云时,可以使用SKU建议,AWS和GCP中也提供类似的调整和迁移服务。
2.2 Query Engines
在查询引擎领域,在过去几年里,特别是在学术界,人们有着极大的兴奋和兴趣。通常,查询引擎上系统方法的ML最常见的目标是索引和布局、基数、成本建模、查询规划器和优化器、查询资源和自调优。
然而,在将查询引擎的ML引入行业中所涉及的挑战有一个共同的认识。例如,将学习到的索引引入BigTable需要一种全新的方法。类似地,最近关于学习基数的实际含义的讨论得出结论,最好将重点缩小到改善真正重要的基数。这带来了Cosmos中第一次行业部署学习基数。有趣的是,用于学习基数的相同基础结构可以用于成本建模,以及视图、自动缩放和使用学习的查询提示引导查询优化器。这使我们认识到,在云级别将ML注入查询引擎真正需要的是更广泛的基础设施,在适当的时候可以插入学习的组件。在这方面,Cosmos目前采用微学习架构,并遵循[27]的工作负载优化模式。为了证明该方法的通用性,目前正在开发基于Spark stack的类似基础设施。
最后,优化资源在云上至关重要。自动资源管理越来越实用。例如资源优化,如SQL Server中的内存授予反馈或大数据工作负载中的并行度。尽管商业数据库已经提供了这样的功能,但云级查询引擎的自动调优似乎是一个遥远的梦想。
2.3 Services
云数据平台通常伴随着许多低级任务和服务,以保持其功能。之前的几项工作研究了如何在没有人为干预的情况下大规模管理云服务。示例包括自动扩展、缓解慢实例、自动切分、负载预测和备份等。即使在这个领域,最近我们也看到了一组新的ML驱动的方法,可以根据观察到的工作负载主动调整服务。例如,许多云数据服务(如HDInsight和EC2)现在都提供了预测自动缩放功能。同样,现在也可以进行预测性备份,以及ML驱动的检查点决策。
2.4 Developers
最后,开发人员是数据系统的核心,因此改善开发人员体验至关重要。例如,更高级的ML驱动开发人员体验现在可以在Visual Studio、VSCode和Github中获得(例如,copilot)。虽然已经为应用程序开发人员开发了大量工具,但也有人推动通过引入新的方法来构建注入ML的软件来改善系统开发人员的生活,该软件易于跟踪、调试、进化,并随着时间的推移进行性能设计。这也与软件2.0趋势有关。
3 THE PATH FORWARD
随着机器学习系统在行业和实践中变得更加主流,我们现在列出了许多我们认为将要解决的问题。
Experimentation
在训练/测试/验证数据集上获得良好的准确性只是系统ML的开始。工作流中的主要步骤包括在大型生产工作负载或金丝雀设置上测试模型。这需要一个实验框架(例如Diametrics,范围飞行工具),用于广泛的A/B测试、对不同指标的性能监控、历史运行的存储和检索以及匿名。一个好的实验框架可以让产品支持团队建立信任,相信机器学习组件不会随着时间的推移产生问题。
Model Serving
一旦产品团队信任ML模型,就可以以多种方式部署它:可以使用容器(例如在Clipper中)或进程外执行;另一种方法是使用进程内执行,方法是将模型作为库导入(例如,在ML.NET或Scikit Learn中),或将模型转换为可在运行时调用的目标格式(例如,通过使用ONNX或Hummingbird实现)。此外,可以在线(例如,一次一个)或批量提供预测。当预测在关键路径上时,前者是首选方法(例如,查询优化器使用基数估计,因此只允许几毫秒来呈现预测),而后一种方法通常用于实现更好的吞吐量和利用现代硬件加速器。
Model Management
通常,必须在同一个支持ML的功能中部署多个ML模型,例如,一个模型用于操作员,或者因为模型会随着时间的推移(例如,每天、每周、每月)更新,以避免过时并跟踪工作负载趋势。在系统中同时具有多个模型,不仅需要适当的模型管理基础设施,允许快速的模型检索、版本控制和更新,但也有一个统一的API,因为不同的模型可以使用不同的框架来实现(例如,Scikit Learn和PyTorch模型可以在同一部署中共存,因为前者提供了大量“传统”ML模型,例如树集成模型,而后者允许部署最先进的DNN)。MLFlow是任何主要云供应商通常采用的用于模型推断的标准API的一个示例。
Performance Regressions
在云数据系统中部署ML模型时,最重要的要求是最小化性能回归:鉴于云产品的大规模,任何性能回归都可能产生一个问题,必须由支持团队手动解决。生成的问题数量的任何增加都可能是一个障碍。为了解决这个问题,需要设置适当的防护装置,以确保模型的行为符合要求。
Debugging and Root Cause Analysis
当ML增强型云数据系统产生一些性能回归或错误时,基础设施应提供广泛的日志记录,以及调试预测的方法。直接使用Azure ML、SageMaker或Google cloud AI等云ML产品可以利用其日志记录和调试工具,而不必构建另一个特定于应用程序的系统。
Privacy and GDPR
由于模型可能是在客户工作负载生成的数据集上训练的,因此任何合理的信息都必须适当匿名。此外,系统产品的ML必须考虑GDPR(或CCPA)要求,以避免监管和性能影响。最后,客户可能会要求删除一些数据,因此可更新模型是一种新的有趣技术。
Common Platforms
以上所有方面都与我们希望通过ML增强的每一个云数据系统相关。主要的云产品,如亚马逊、谷歌和微软,都有几种托管数据系统产品,每次为系统基础设施构建一个新的ML成本高昂且冗余。因此,首选通过统一的服务和基础架构整合数据产品,从而一次性构建通用ML组件,并在不同的产品中重用。Azure Synapse是朝着这个方向迈出的一步。
4 PRESENTERS
Alekh Jindal 是微软Gray Systems Lab(GSL)的首席科学家,负责管理该实验室的Redmond站点。他的研究重点是提高大规模数据密集型系统的性能。早些时候,他是麻省理工学院CSAIL数据库组的博士后助理。Alekh在萨尔大学获得博士学位,致力于传统数据库和MapReduce的灵活和可扩展数据存储。在过去10年中,Alekh曾担任SIGMOD、VLDB、ICDE和SOCC等领域顶级会议的主席、PC成员和评审员。他在2014年VLDB和2011年CIDR上获得最佳论文奖,并在2021 SIGMOD上获得荣誉奖。
Matteo Interlandi 是微软Gray Systems Lab(GSL)的高级科学家,致力于可扩展的机器学习系统。在微软之前,他是洛杉矶加利福尼亚大学的博士后学者。在加入加州大学洛杉矶分校之前,他是卡塔尔计算研究所和人机认知研究所的研究助理。Matteo的作品在2021的SIGMOD大会上获得了荣誉奖,并被评为“VLDB之最”。















 3479
3479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









