







word2vec、glove、fasttext是静态词向量,无法解决一词多义问题,elmo、GPT、Bert词向量是基于语言模型的动态词向量。
elmo、GPT、bert三者之间有什么区别?
- 特征提取器:
elmo采用LSTM进行提取,GPT和bert则采用Transformer进行提取。很多任务表明Transformer特征提取能力强于LSTM,elmo采用1层静态向量+2层LSTM,多层提取能力有限,而GPT和bert中的Transformer可采用多层,并行计算能力强。- 单/双向语言模型:
GPT采用单向语言模型,elmo和bert采用双向语言模型。但是elmo实际上是两个单向语言模型(方向相反)的拼接,这种融合特征的能力比bert一体化融合特征方式弱。
GPT和bert都采用Transformer,Transformer是encoder-decoder结构,GPT的单向语言模型采用decoder部分,decoder的部分见到的都是不完整的句子;bert的双向语言模型则采用encoder部分,采用了完整句子。
资料传送:
- 娄杰(2019):nlp中的词向量对比word2vec/glove/fastText/elmo/GPT/bert
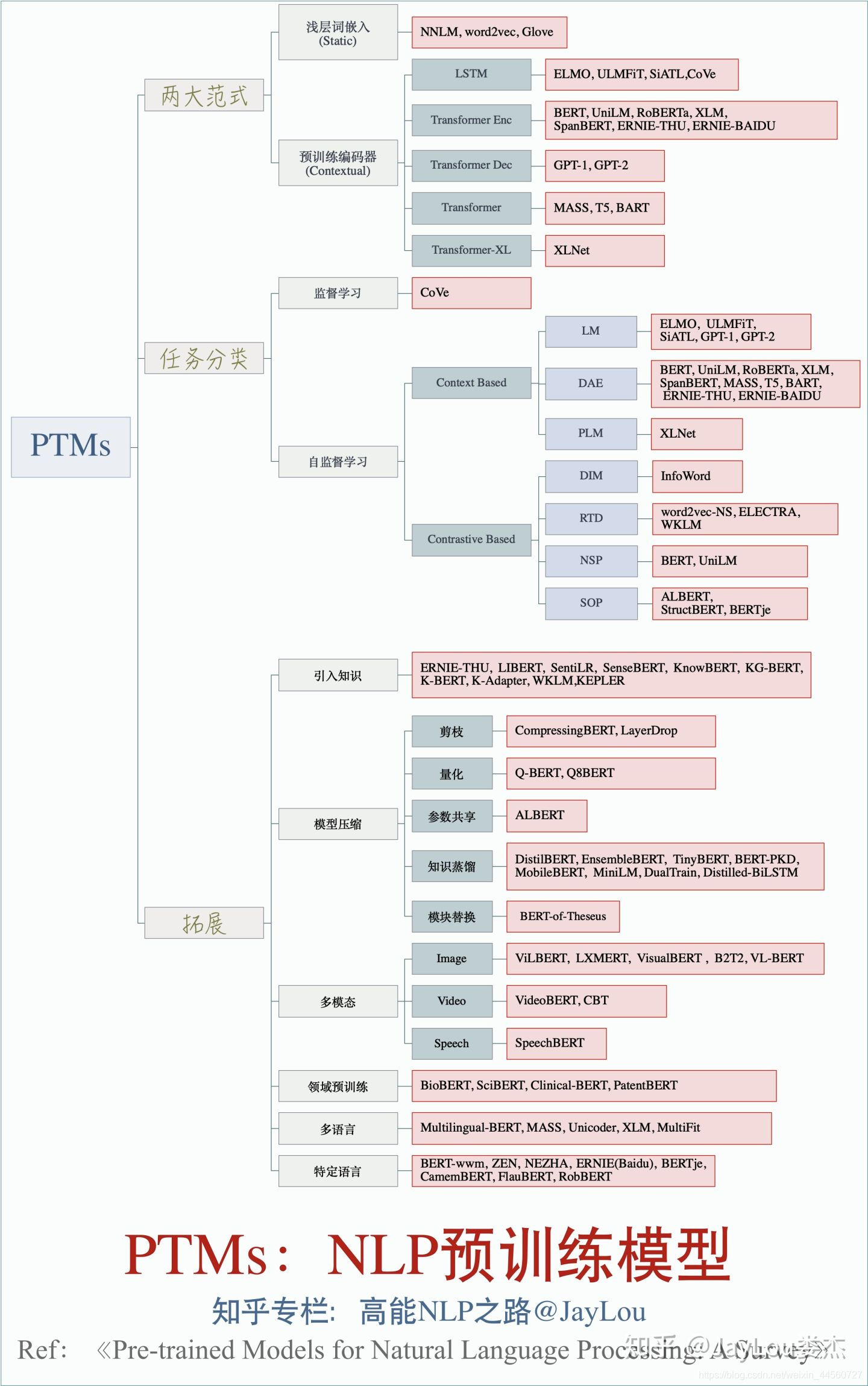
注:对word2vec和glove的数学推导、技术细节讲得比较细 - 娄杰(2020):PTMs: NLP预训练模型的全面总结
注:全面总结对比各类模型,但具体模型需自行研究
– 娄杰github:各具体PTM解读 - 复旦邱锡鹏超全NLP预训练模型综述论文:两张图带你梳理完整脉络
注:建议看paper (2020.03) - 张俊林老师:从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
注:深入浅出,知其所以然 (2018.11, bert 刚出世) - 张俊林老师:乘风破浪的PTM:两年来预训练模型的技术进展
注:老师出手,必属精品!!!(2020.09) - 词向量全解
注:从 tf-idf 到bert,适合新手















 5140
5140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









