







目录
2.1 ELMo的本质思想是:本身是个根据当前上下文对Word Embedding动态调整
2.2 ELMo采用了典型的两阶段过程:
- NER:命名体识别
- SQuAD:阅读理解
- SNLI:Stanford自然语言推理
- SRL:语义角色标注(Semantic Role Labelling)
- Coref:共指消解(Coreference Resolution):确定不同实体的等价描述,包括代词消解和名词消解
- SST-5:情感分析任务
一、word embedding
1.1 介绍
- word embedding是NLP里的早期预训练技术。
- word embedding把词映射到向量空间。语义相似的词在向量空间中位置越近。
- word2vec是谷歌提出一种word embedding的工具或者算法集合
- 2013年最火的用语言模型做Word Embedding的工具是Word2Vec
word2vec
- 简单化的神经网络;
- hidden layer没有激活函数,也就是线性的单元;
- output layer维度 = input layer维度,softmax回归;
- 训练后只需要隐层的权重矩阵;
- 分为CBOW和Skip-gram两种模型。
1.2 Word2Vec有两种训练方法:
- 一种叫CBOW,核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词;有点类似于小时候做的英语完形填空。
- 第二种叫做Skip-gram,和CBOW正好反过来,输入某个单词,要求网络预测它的上下文单词。
这里可以使用word2vec的例子图
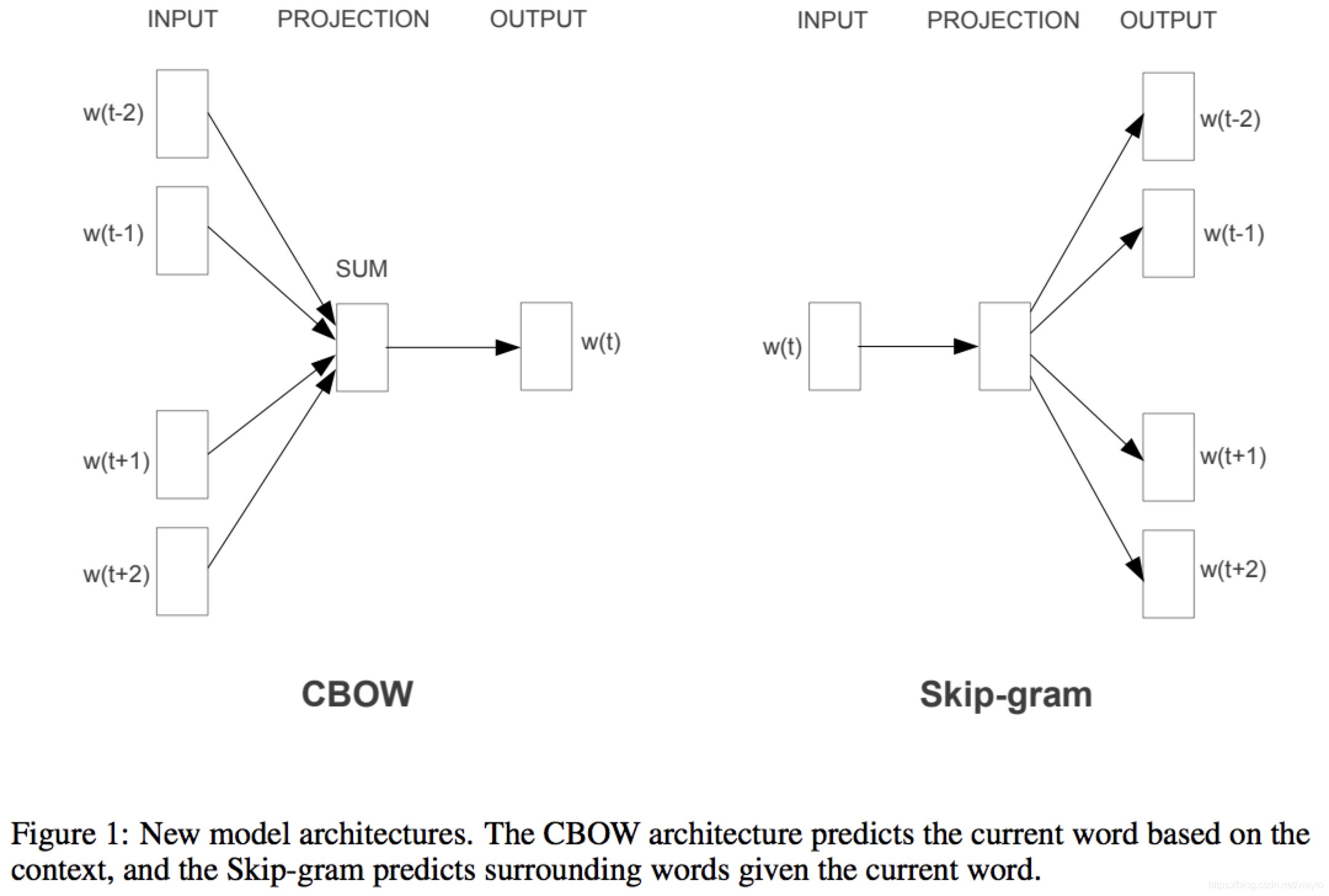

这里举一个例子。
18年之前NLP中经典的预训练方式。
第一层将词进行embedding之后获取词向量,句子中的每个词以one-hot形式输入,然后和学好的 word embedding矩阵Q相乘,得到该句子的word embedding了。所以word embedding等价于 one-hot层 到 embedding层 的网络。
矩阵Q包含V行,V代表词典大小,每一行内容代表对应单词的Word embedding值。只不过Q的内容也是网络参数,需要学习获得,训练刚开始用随机值初始化矩阵Q,当这个网络训练好之后,矩阵Q的内容被正确赋值,每一行代表一个单词对应的Word embedding值。
CBOW 与 skip-gram的区别:CBOW 与 skip-gram_"灼灼其华"的博客-CSDN博客_cbow和skipgram
1.3 Word Embedding的应用:
- 计算相似度,比如man和woman的相似度比man和apple的相似度高
- 在一组单词中找出与众不同的一个,例如在如下词汇列表中:[dog, cat, chicken, boy],利用词向量可以识别出boy和其他三个词不是一类。
- 直接进行词的运算,例如经典的:woman+king-man =queen
- 由于携带了语义信息,还可以计算一段文字出现的可能性,也就是说,这段文字是否通顺。
本质上来说,经过Word Embedding之后,各个word就组合成了一个相对低维空间上的一组向量,这些向量之间的远近关系则由他们之间的语义关系决定。
1.4 word embedding存在的问题:
无法解决多义词问题,没有语境信息,原因是word embedding是静态的。
二、从word embedding到ELMO
针对word embedding无法解决多义词的问题,ELMO( Embedding from Language Models )提出了一个简洁有效的解决方案。
2.1 ELMO的本质思想是:本身是个根据当前上下文对Word Embedding动态调整
我事先用语言模型学好一个单词的Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。
基于上下文的word embedding:ELMO
2.2 ELMO采用了典型的两阶段过程:
- 第一阶段是利用语言模型进行预训练。获取对应单词的word embedding
- 第二阶段是做下游任务时将预训练获得word embedding作为新特征补充到下游任务中。
2.3 网络采用双层双向LSTM特征抽取器
- 长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,
- 主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。
比如我们目前的任务上面讲的CBOW完形填空任务,根据上下文取预测单词Wi。这个Wi之前的是上文,之后的是下文。
图中左端的前向双层LSTM代表正向编码器,输入的是从左到右的单词Wi的上文;右端的逆向双层LSTM代表反向编码器,输入的是从右到左的逆序的单词Wi的下文。每个编码器的深度都是两层LSTM叠加。
使用大量语料训练好这个网络后,输入一个新句子,句子中的每个词对应三个embedding:
(1)最底层的是单词的word embedding;
(2)往上一层是第一层双向LSTM中单词位置对应的embedding,句法信息更多;
(3)再往上走一层是第二层双向LSTM中对应单词位置的embedding,语义信息更多。通过将这三个embedding整合成一个,更能区分多义词的效果。
2.4 结果:
ELMo预训练过程不仅学会了单词的word embedding,还学会了一个双层双向的LSTM网络结构。
2.5 ELMo优点:
- 给出了语境问题的解决方案。它用了两层双向的LSTM。不仅能输出一个单词embedding,还能输出单词在句子中的句法特征,和语义特征。
- 在6个NLP任务中,有较大幅度的提升;
- 适用范围是非常广的,普适性强
2.6 ELMo的缺点:
- ELMo使用了LSTM作为特征提取器,LSTM抽取特征能力远弱于 Transformer
- 拼接方式双向融合,特征融合能力偏弱
三、从word embedding到GPT
3.1 基于"Fine-tuning的模式"
- GPT就是这一模式的典型开创者。
- GPT是"Generative Pre-Training"的简称,从名字看指生成式的预训练
- GPT也采用两阶段过程,第一个阶段是利用语言模型进行预训练,第二阶段通过Fine-tuning的模式解决下游任务。
- GPT的预训练过程和ELMO是类似,区别在于:
- 特征抽取器使用的Transformer,ELMO采用的是LSTM;
- GPT的预训练采用的是单向的语言模型,只使用了单词的上文来预测单词Wi
3.2 GPT优点:
- 效果是非常令人惊艳的,在12个任务里,9个达到了最好的效果,有些任务性能提升非常明显
- 适用范围广
3.3 GPT的缺点:
- 使用单向语言模型(没有用双向【正向、反向】抽取),不能很好的理解下文。
3.4 Transformer:
- Transformer是谷歌在17年做机器翻译任务的"Attention is all you need"的论文中提出的。
- Transformer是个叠加的“自注意力机制(Self Attention)”构成的深度网络,是目前NLP里最强的特征提取器
- Transformer在未来会逐渐替代掉RNN成为主流的NLP工具
- Transformer同时具备并行性好,又适合捕获长距离特征
- CNN的最大优点是易于做并行计算,所以速度快,但是在捕获NLP的序列关系尤其是长距离特征方面天然有缺陷
- RNN一直受困于其并行计算能力,这是因为它本身结构的序列性依赖导致的
- ELMO是基于特征融合的预训练方法
Transformer Encoder在Multi-head Self-Attention之上又添加了三种关键操作:
- 残差连接(ResidualConnection):将模块的输入与输出直接相加,作为最后的输出。这种操作背后的一个基本考虑是:修改输入比重构整个输出更容易(“锦上添花”比“雪中送炭”容易多了!)。这样一来,可以使网络更容易训练。
- Layer Normalization:对某一层神经网络节点作0均值1方差的标准化。
- 线性转换:对每个字的增强语义向量再做两次线性变换,以增强整个模型的表达能力。这里,变换后的向量与原向量保持长度相同。
Transformer Encoder的输入和输出在形式上还是完全相同,因此,Transformer Encoder同样可以表示为将输入文本中各个字的语义向量转换为相同长度的增强语义向量的一个黑盒。
四、BERT诞生
把Transformer Encoder模块一层一层的堆叠起来就是大名鼎鼎的bert
4.1 Bert的输入部分
它的输入部分是个线性序列,两个句子通过分隔符分割,最前面和最后增加两个标识符号。每个单词有三个embedding:
1. 位置信息embedding,这是因为NLP中单词顺序是很重要的特征,需要在这里对位置信息进行编码;
2. 单词embedding,这个就是我们之前一直提到的单词embedding;
3. 三个是句子embedding,因为前面提到训练数据都是由两个句子构成的,那么每个句子有个句子整体的embedding项对应给每个单词。把单词对应的三个embedding叠加,就形成了Bert的输入。
4.2 Bert采用和GPT完全相同的两阶段模型:
- 首先是语言模型预训练;
- 其次是使用Fine-Tuning模式解决下游任务
Bert本身在模型和方法角度有什么创新呢?
- Masked 语言模型(本质思想其实是CBOW)
- Next Sentence Prediction
Masked双向语言模型:
随机选择语料中15%的单词,把它抠掉,也就是用[Mask]掩码代替原始单词,然后要求模型去正确预测被抠掉的单词。但是这里有个问题:训练过程大量看到[mask]标记,但是真正后面用的时候是不会有这个标记的,这会引导模型认为输出是针对[mask]这个标记的,但是实际使用又见不到这个标记,这自然会有问题。
为了避免这个问题,Bert改造了一下,15%的被上天选中要执行[mask]替身这项光荣任务的单词中,只有80%真正被替换成[mask]标记,10%被狸猫换太子随机替换成另外一个单词,10%情况这个单词还待在原地不做改动。这就是Masked双向语言模型的具体做法。
4.3 Bert和GPT的最主要不同在于:
- 在预训练阶段采用了类似ELMO的双向语言模型,
- 采用Transformer作为特征抽取器(Transformer很可能在未来取代RNN与CNN成为信息抽取的利器。)
- 另外一点是语言模型的数据规模要比GPT大。
NLP四大类任务:
- 序列标注:分词、POS Tag、NERT、语义标注...
- 分类任务:文本分类、情感计算..
- 句子关系判断:Entailment/QA/自然语言推理..
- 生成式任务:机器翻译、文本摘要
1、一类是序列标注,这是最典型的NLP任务,比如中文分词,词性标注,命名实体识别,语义角色标注等都可以归入这一类问题,它的特点是句子中每个单词要求模型根据上下文都要给出一个分类类别。
2、第二类是分类任务,比如我们常见的文本分类,情感计算等都可以归入这一类。
它的特点是不管文章有多长,总体给出一个分类类别即可。
3、第三类任务是句子关系判断,比如Entailment,QA,语义改写,自然语言推理等任务都是这个模式,
它的特点是给定两个句子,模型判断出两个句子是否具备某种语义关系;
4、第四类是生成式任务,比如机器翻译,文本摘要,写诗造句,看图说话等都属于这一类。
它的特点是输入文本内容后,需要自主生成另外一段文字。
NLP四大类任务都可以比较方便地改造成Bert能够接受的方式。这其实是Bert的非常大的优点,这意味着它几乎可以做任何NLP的下游任务,具备普适性,这是很强的。(强调Bert的普适性有多强。)
4.4 总结:
- Bert作者说是受到完形填空任务的启发
- Bert本身的效果好和普适性强才是最大的亮点。
- Bert本身在模型和方法角度的创新指Masked语言模型和Next Sentence Prediction。
- Masked语言模型上面讲了,本质思想其实是CBOW,但是细节方面有改进。
Bert最关键两点:
- 一点是特征抽取器采用Transformer;
- 第二点是预训练的时候采用双向语言模型。















 4396
4396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









