









 本文详细介绍了使用Python的arcpy库处理MODIS遥感数据的四个步骤:1) HDF转TIFF,2) 统计TIFF年内天数,3) 拼接TIFF,4) 使用矢量文件裁剪TIFF,并展示了每个步骤的代码实现。通过这些步骤,可以有效地管理和处理大规模遥感数据,为后续分析提供基础。
本文详细介绍了使用Python的arcpy库处理MODIS遥感数据的四个步骤:1) HDF转TIFF,2) 统计TIFF年内天数,3) 拼接TIFF,4) 使用矢量文件裁剪TIFF,并展示了每个步骤的代码实现。通过这些步骤,可以有效地管理和处理大规模遥感数据,为后续分析提供基础。
话不多说,直接上干货!
参考帖子:① python_MODIS HDF数据转为tif并拼接图像
② ArcMap
准备工作:① Python2.7 -- Arcpy库
1.hdf转tif
MOD10A2产品为hdf文件,需要转成gis可识别的tif栅格文件,参考帖子①,具体代码如下:
# -*- coding:utf-8 -*-
import arcpy
import os
def hdf2tif():
# 需要修改以下路径
sourceDir = u'F:\******' # 输入路径
targetDir = u'F:\******' # 输出路径
arcpy.CheckOutExtension("Spatial")
env.workspace = sourceDir
arcpy.env.scratchWorkspace = sourceDir
hdfList = arcpy.ListRasters('*', 'hdf')
for hdf in hdfList:
print(hdf)
eviName = os.path.basename(hdf).replace('hdf', 'tif')
outname = targetDir + '\\' + eviName
print(outname)
data1 = arcpy.ExtractSubDataset_management(hdf, outname, "Eight_Day_Snow_Cover") # Eight_Day_Snow_Cover是子数据集名称
print('all done')
hdf2tif()转换前hdf文件:
转换后tif文件:
2.统计tif文件年内天数
统计tif文件年内天数,便于后续处理,参考帖子①,具体代码如下:
# -*- coding:utf-8 -*-
import glob
import os
import pandas as pd
def day():
path = u'F:\******' # tif文件输入路径
outws = u'F:\******' # CSV文件输出路径
rasters = glob.glob(os.path.join(path, "*.tif"))
# range中的年份要修改成与数据集年份一致,否则报错
for year in range(2003, 2022): # 这里对应数据集的年份是2003-2021年
days_list = []
for ras in rasters:
info = os.path.basename(ras).split('.')[1]
info = info.replace('A', '')
if str(info[:4]) == str(year):
days = info[4:7] # 截取天数
days_list.append(days)
outname = outws + '\\' + str(year) + '.csv' # 输入文件名
days_list_f = list(set(days_list))
days_list_f.sort(reverse=False)
days_list_df = pd.DataFrame(days_list_f)
days_list_df.columns = ['days'] # df设置列名
days_list_df.to_csv(outname, header=True, encoding='gbk') # 写入文件CSV
day()实现后为: 
3.拼接tif
参考帖子①,主要用到的arcpy库中的MosaicToNewRaster_management功能(点击链接或在帖子②中找到对应功能理解学习)。该过程需要对tif进行投影,注意坐标系要与自己的shp保持一致,具体代码如下:
# -*- coding:gbk-*-
import arcpy
import glob
import os
from arcpy import env
import pandas as pd
#判断日期函数,由于MODIS数据文件是以年内天数命名,为了将其转为日期,并给镶嵌后的文件重新命名,如2001001变为2001_01_01
def out_date(year,day):
fir_day = datetime.datetime(year,1,1)
zone = datetime.timedelta(days=day-1)
return datetime.datetime.strftime(fir_day + zone, "%Y_%m_%d")
def mosaic():
arcpy.CheckOutExtension("Spatial")
# 指定影像所在目录
env.workspace = u'F:\******' # 工作空间
inws = u'F:\******' # tif文件 输入路径
##inws=inws.encode('utf-8')
outws = u'F:\******' # 输出路径
mask = u"F:\\MOD11A2\\WGS 1984.prj" # 投影文件
days_inws = u'******' # 上述2章节中day()结果文件的路径
# 利用glob包,将inws下的所有tif文件读存放到rasters中
rasters = glob.glob(os.path.join(inws, "*.tif"))
csv_file = glob.glob(os.path.join(days_inws, "*.csv"))
for year in csv_file:
year_csv = os.path.basename(year).split('.')[0]
data = pd.read_csv(year, encoding='gbk')
days = list(data['days'])
for d in days:
raster_list = []
day = int(str(d))
print(day, year_csv)
for ras in arcpy.ListFiles("*.tif"):
# 循环rasters中的所有影像,进行按掩模提取操作
info = os.path.basename(ras).split('.')[1]
info = info.replace('A', '')
day_info = int(info[4:7])
if str(info[:4]) == str(year_csv) and day == day_info:
raster_list.append(ras)
print(info)
year_info_shift = info[:4]
days_info_shift = info[4:7]
# 生成文件名日期
finame_1 = out_date(int(year_info_shift), int(days_info_shift))
print(finame_1)
## #完整文件名
outname = finame_1 + '_MOD10A2.tif'
print(outname)
try:
##Mosaic several TIFF images to a new TIFF image
arcpy.MosaicToNewRaster_management(raster_list, outws, outname, mask, \
"32_BIT_UNSIGNED", "", "1", "LAST", "FIRST")
except:
print("Mosaic To New Raster example failed.")
print(arcpy.GetMessages())
print('mosaic finish')
mosaic()拼接后为:
4.裁剪tif
这里用到的功能是Arcpy库中的ExtractByMask,参考帖子③,具体代码如下:
# -*- coding: UTF-8 -*-
import arcpy
import os
import glob
import arcpy
from arcpy.sa import *
def clip():
arcpy.CheckOutExtension("ImageAnalyst") # 检查许可
arcpy.CheckOutExtension("spatial")
# 定义工作空间及数据路径,路径下有不同区域矢量文件和被裁剪的全部TIFF文件
arcpy.env.workspace = u"F:\******" # 工作空间,这里设置为拼接后的文件路径
rasters = arcpy.ListRasters("*", "tif") # 遍历工作空间中的tif格式数据
inMasks = arcpy.ListFeatureClasses() # 遍历工作空间中的shp格式数据
for inMask in inMasks:
for raster in rasters:
outpath = u"F:\******" # 输出文件路径
if not os.path.exists(outpath + os.sep + str(inMask).replace('.', '_')): # 如果储存路径下没有以矢量文件命名的文件夹
os.mkdir(outpath + os.sep + str(inMask).replace('.', '_')) # 生成以矢量文件命名的文件夹(注意.shp中的点要替换)
outCJ = ExtractByMask(raster, inMask) # 批量裁剪文件
print (outpath + os.sep + str(inMask).replace('.', '_') + os.sep + str(raster))
outCJ.save(outpath + os.sep + str(inMask).replace('.', '_') + os.sep + str(raster)) # 输出存储裁剪的栅格数据,存储到新建文件夹里
print(str(raster)) # 输出读取并裁剪的栅格数据名称
print("over!!!!!!!!")
clip()裁剪后为: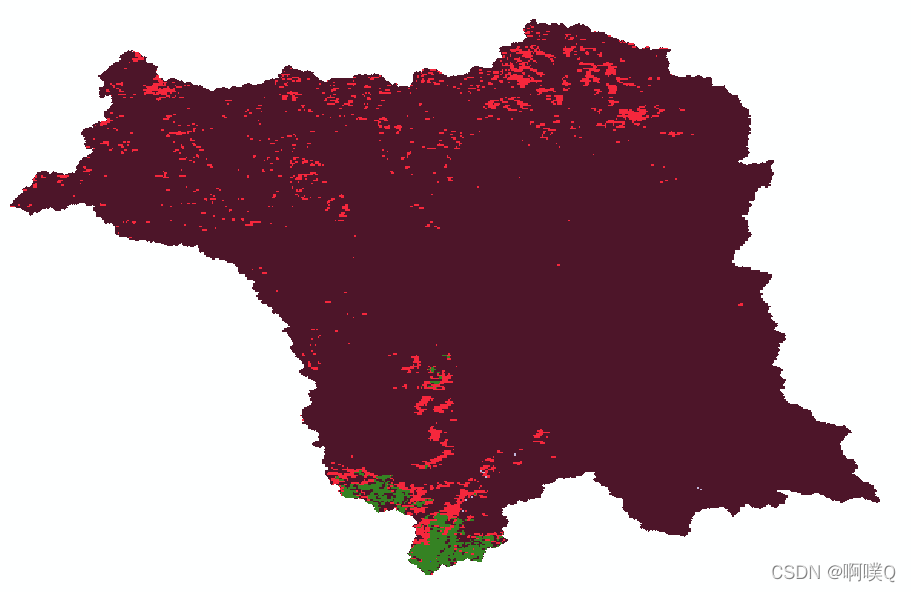
5.提取tif栅格中积雪的栅格个数和栅格总数
主要功能为Arcpy中的SearchCursor,主要参考帖子④。栅格各像元值含义见下图:
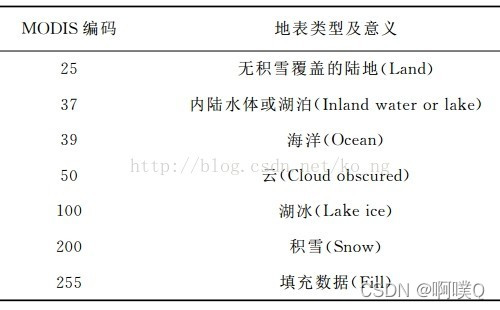
具体代码如下:
# -*- coding:utf-8 -*-
import arcpy
from arcpy import env
import pandas as pd
from arcpy.sa import *
import numpy as np
def tiqu():
# 定义工作空间及数据路径,路径下有全部TIFF文件
arcpy.env.workspace = u"F:\******" # 裁剪后的tif文件路径
rasters = arcpy.ListRasters("*", "tif") # 遍历工作空间中的tif格式数据
# 提取tif文件中的'OID', 'VALUE', 'COUNT'字段
shpfields = ['OID', 'VALUE', 'COUNT']
SUM = []
SNOW = []
result = []
data = []
for raster in rasters:
print str(raster)
shp_OID = []
shp_V = []
shp_C = []
snow = 0
sum = 0
shprows = arcpy.SearchCursor(raster, shpfields)
while True:
shprow = shprows.next()
if not shprow:
break
shp_OID.append(shprow.OID)
shp_V.append(shprow.VALUE)
shp_C.append(shprow.COUNT)
for i in range(0, len(shp_OID)):
sum += shp_C[i] # 统计栅格总数
if shp_V[i] == 200: # 像元值200代表有积雪
snow += shp_C[i]
# print shp_OID[i], shp_V[i], shp_C[i]
data.append(str(raster)[0:10]) # 提取tif文件名中的年月日
SUM.append(sum)
SNOW.append(snow)
print (str(raster), 'is down')
# 将提取的数据保存至CSV文件
path_sim = 'F:\\******\\' # CSV文件输出路径(注意一定要有最后的两个双斜线)
file_name_sim = path_sim + 'SNOW.csv'
result = np.c_[data, SUM, SNOW]
df = pd.DataFrame(result)
df.columns = [u'DATA', u'SUM', u'SNOW'] # 定义CSV首行
df.to_csv(file_name_sim)
tiqu()提取后为: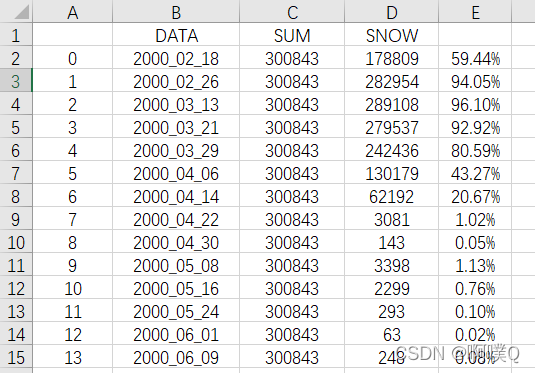
注:若想获得其余地表类型栅格数,在代码中修改即可。 由于MOD10A2的时间步长为8天,若要获取逐日数据,还需进行插值计算。
收工!下一贴为MOD11A2地温产品处理方法。

















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









