







论文:《Deep Residual Learning for Image Recongnition》 kaiming he ,jian sun等人
ResNet 在2015年由微软实验室提出,斩获当年ImageNet竞赛中分类任务的第一名,目标检测第一名。获得coco数据集中目标检测,图像分割的第一名。就是一种非常牛掰的网络。我们可以叫它残差网络。

LeNet5、AlexNet、VGG-16、GoogLeNet、ResNet50原理及其结构 - 简书 (jianshu.com)这个链接里面做的图比较高清
(壹)网络当中的亮点:
(一)网络结构非常深(作者在原论文当中尝试搭建1000层的网络)
(二)提出Residual模块
(三)使用Batch Normalization加速训练(丢弃Dropout)
(一)网络结构加深就一定好吗?

加深层数产生的问题:
1 梯度消失或者梯度爆炸:如果我们的权重<1在反向传播中就会慢慢的变成0,如果>1,在一层层的反向传播中就会导致梯度爆炸。
如何处理(处理方法发有哪些):(1)对数据进行标准化处理(2)权重初始化(3)BN层
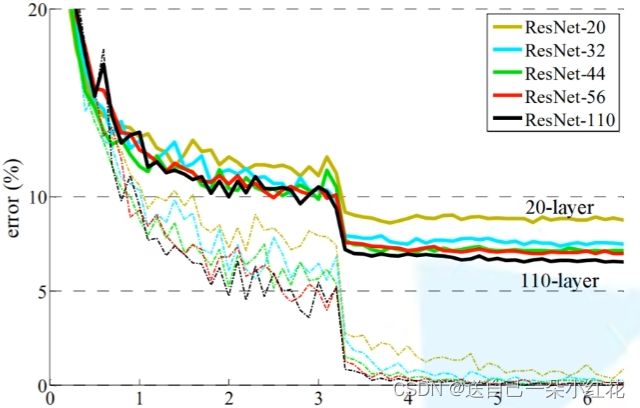
2 退化问题(degradation problem):随着网络加深,效果反而不好。但是残差网络很好的解决了这一问题,如下图,随着网络的加深,反而我们的错误率越低。
(二)Residual结构(残差结构)
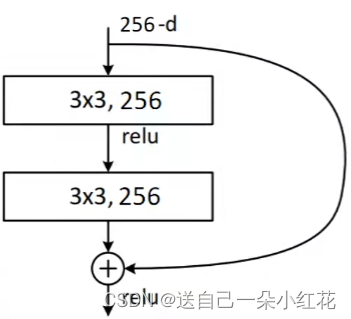
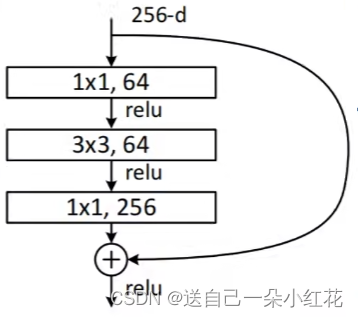
左边这副是针对网络深度较小的网络设置残差结构,右边是深层次的网络所搭建的残差结构,
34-layars , 50、101、152-layars。
我们提到过,神经网络的目标是减少参数。
我们经计算:右边大概是左边参数的一半。

注意:残差结构中主分支与shortcut的输出特征矩阵shape必须相同。进行相同维度以及位置的加法运算而不是像GoodLeNet深度方向拼接。
可以把残差结构理解为一层层的给提取到的重要特征 * 1.x,不重要的特征 * 0.x。
(贰)(三)使用Batch Normalization加速训练(丢弃Dropout)
Batch Normalization是为了使我们的一批(Batch)feature map满足均值为0,方差为1的分布规律。
可以把它理解为加强每一个batch里面的相同channel维度上的元素之间的关联性(为什么这里要这么讲,因为后面还会接触到Layer-norm,nlp领域的应用,注意理解并区分)
BN的形状以及计算(RepVGG会用到):
(叁)常见的迁移学习方式:
1.载入权重后训练所有参数
2.载入权重后只训练最后几层参数
3.载入权重后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------分割线,以下是原版笔记-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ResNext网络,亮点就是更新了一下block的结构。
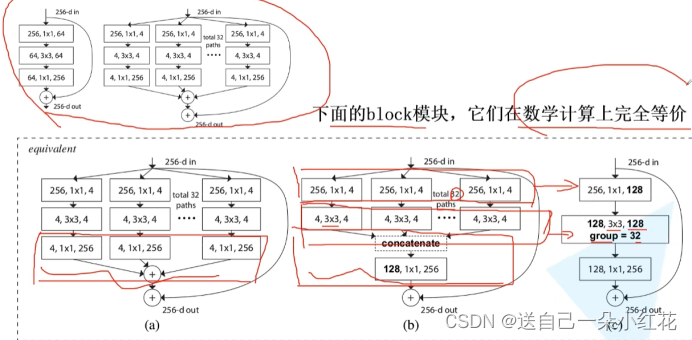
等价?原因是由于引入了组卷积(group convolution)概念。
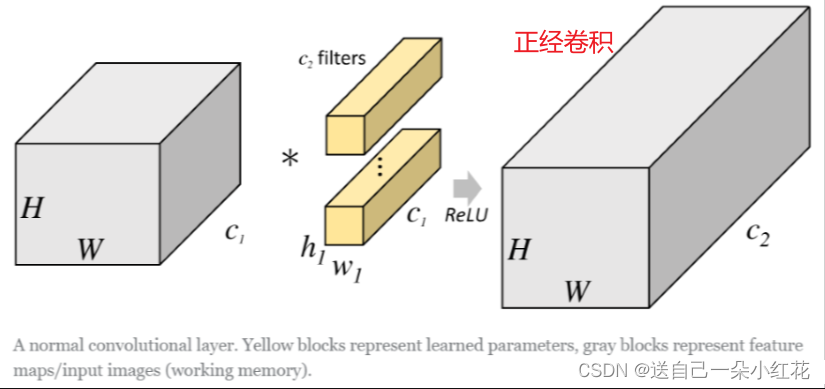
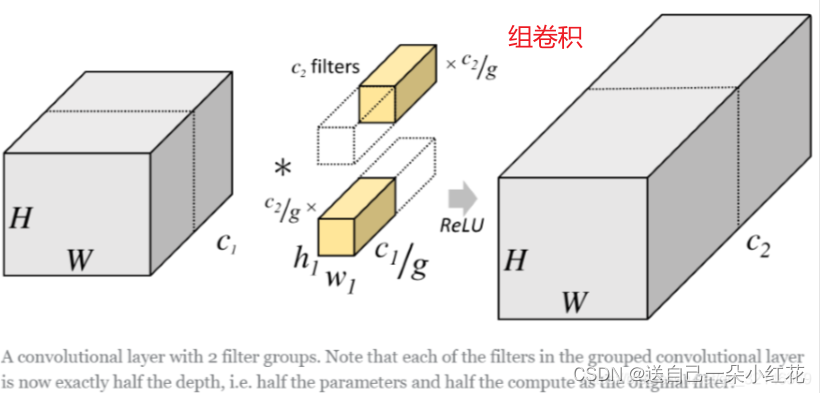
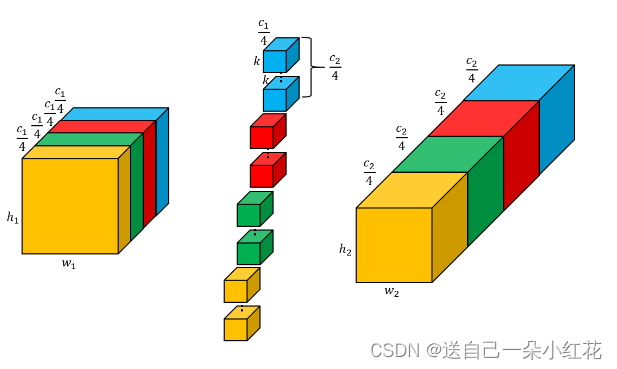
可以计算一下组卷积参数就知道为啥使用组卷积了。所需参数明显小了g倍。
concatenate拼接操作和(+)操作


上面那个是每个feature map先叠加再与size为1 的filter卷积
下面那个是每个feature先与size为1的filter卷积然后(+)
效果是一样的,但是还是说参数不一样。
Resne---------------------------------------------------------------------->ResNeXt
不同:resnext网络的每一层的out_channel都是rexnet网络的2倍
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ResNext网络梳理:
无论是多少层的网络,它第一层共有的conv卷积完都是64channel的(大小也从224变成了112size),接下来共有的maxpooling让图片剪裁成56size,所以第一层的layer的downsample都不需要缩小长宽了,只需要深度与输出一致(18、32不变,50、101、152深度x4(早就block定义了expention))
当网络为18,32层的时候:
Layer1=self._make_layer(block, 64, blocks_num[0]) 此处block在进入model函数时候,就根据18、32层,传入进了两层结构的class BasicBlock(nn.Module)。
这里也没有定义步长,为默认参数(stride=1),进入make_layer函数之后stride!=1条件不满足。所以不进行downsample,然后进行layer_1的参数压入(就是执行block_num=0),由于(不进行生维操作)所以没什么意义,然后一个循环写入剩下的block_num,循环进行完后在进行layer2的block生成:
(Layer2的生成就有讲究了),由于第一层maxpooling帮第一层提前缩小了size,而layer2没有这么好的资源,他需要自己做这件事,首先在medel中就写了:self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2),定义了stride=2,进入make layer函数之后,满足stride!=1,所以进入里面的卷积(stride=2)size减少一半(channel不做什么操作,区别50、101、152层结构),然后继续后面第二层layer的block后续写入。
在BasicBlock里面,第一层layer的第一个block的第一个残差结构不进行downsample(不满足stride!=1),再forward,forward中short cut实线虚线都在后面与直线的输出进行相加,不同之处:先把x(网络的输入)赋值给identity,downward如果进行了这句话( downsample = nn.Sequential())说明downward非None,则重新赋值identity =self.downsample(x),继续forward,向后执行到:out += identity(处理过)。如果没有进行下采样(downward=None),说明不需要resize,channel前后也相同,out+=identity(输入)。
第一层layer不进行resize,前后channel都一样(18、32里面的前后channel都是一样的),out直接和输入(identity=x)相加。
在layer_x(x>1)的第一个block(block_0)进行resize(/2)操作,block_0的downward非None,identity = self.downsample(x),out和处理过的identity相加。
在block_x(x>0)::for _ in range(1, block_num)处理实线残差和实线short cut部分::layers.append(block(self.in_channel,channel,)这里没有定义stride,你可能会问,这里的stride是self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)传入的2呢还是1呢,其实想想就应该发现为1不为2,原因在于代码,蓝色部分代码定义的stride是作用在layer上的,但在append加入的时候stride是作用在block上的 layers.append(block(self.in_channel,channel,stride=stride),
只有当指定了block函数“里面的stride”=通过layer传入的stride时,定义在self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)里面的stirde才作用于
stride = stride,否则当block函数不定义stride时,block里面的stride等于声明函数时里面的默认stride值。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
6.3 tensorflow实现resnet
Read_ckpt.py用来转换官方权重为我所需要的
在它权重当中有一些我不需要的层结构:
except_list = ['global_step', 'resnet_v1_50/mean_rgb', 'resnet_v1_50/logits/biases', 'resnet_v1_50/logits/weights']
for var_name, shape in var_list:
print(var_name)
if var_name in except_list:
continue#如果在排除列表中,跳过
var = tf.train.load_variable(ckpt_path, var_name)#不在排除列表里就加载
new_var_name = var_name.replace('resnet_v1_50/', "")
new_var_name = new_var_name.replace("bottleneck_v1/", "")
new_var_name = new_var_name.replace("shortcut/weights", "shortcut/conv1/kernel")
new_var_name = new_var_name.replace("weights", "kernel")
new_var_name = new_var_name.replace("biases", "bias")
re_var = tf.Variable(var, name=new_var_name)
new_var_list.append(re_var)














 470
470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









