







 本文详细介绍了CUDA(ComputeUnifiedDeviceArchitecture)和GPU的基本概念,GPU的工作原理,编程模型(包括Grid、Block和Thread),CUDA核函数的配置,以及如何使用CUDA进行向量加法和矩阵乘法的示例。文章还涵盖了数据同步、运行时API的关键操作,如内存管理和数据复制。
本文详细介绍了CUDA(ComputeUnifiedDeviceArchitecture)和GPU的基本概念,GPU的工作原理,编程模型(包括Grid、Block和Thread),CUDA核函数的配置,以及如何使用CUDA进行向量加法和矩阵乘法的示例。文章还涵盖了数据同步、运行时API的关键操作,如内存管理和数据复制。
一、CUDA 和 GPU 简介
- CUDA 是显卡厂商 NVIDIA 推出的运算平台,是一种通用并行计算架构,使得 GPU 能够解决复杂的计算问题。
- 开发人员可以使用 C 语言来为 CUDA 架构编写程序,可以在支持 CUDA 的处理器上以超高性能运行,CUDA 3.0 已经开始支持 C++。
- GPU 是图形处理器,显卡的处理核心。
- 电脑显示器上显示的图像,在显示在显示器上之前,要经过一系列的图形计算,这个过程叫渲染,针对图形计算的这些操作设计了一种处理器,也就是 GPU。
二、GPU 工作原理与结构
- GPU 采用流式并行计算模式,可对每个数据行进行独立的并行计算。
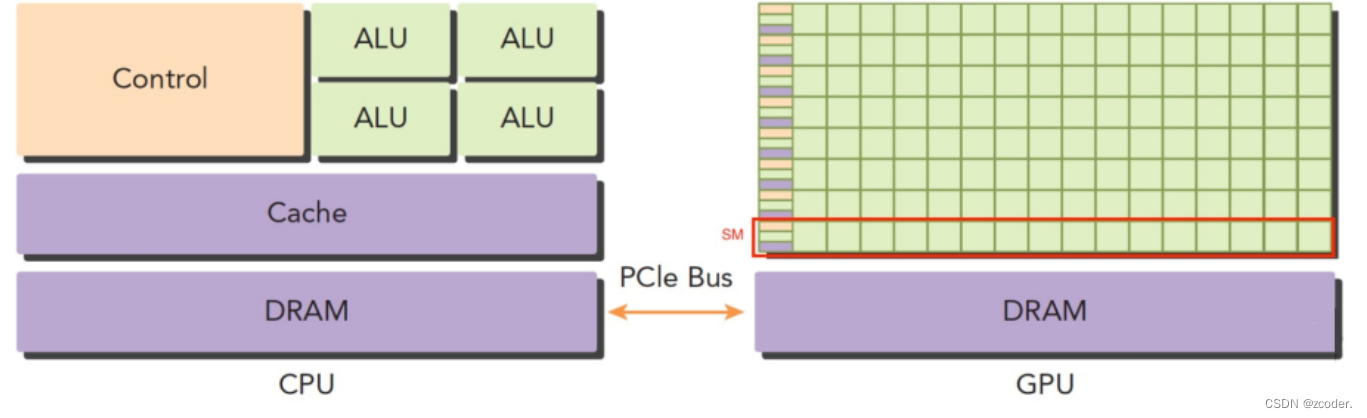
- GPU 和 CPU 的区别:
- CPU 基于低延时设计,由运算器(ALU:算数逻辑单元)和控制器(CU),以及若干个寄存器和高速缓冲存储器组成,功能模块较多,擅长逻辑控制,串行运算。
- GPU 基于大吞吐量设计,拥有更多的 ALU 用于数据处理,适合对密集数据进行并行处理,擅长大规模并行计算。
- GPU 为图形图像专门设计,在矩阵运算,数值计算方面具有独特优势,特别是浮点和并行计算上远远优于 CPU,GPU 的优势在于快。
三、GPU 编程模型
- 异构计算 = CPU + GPU。
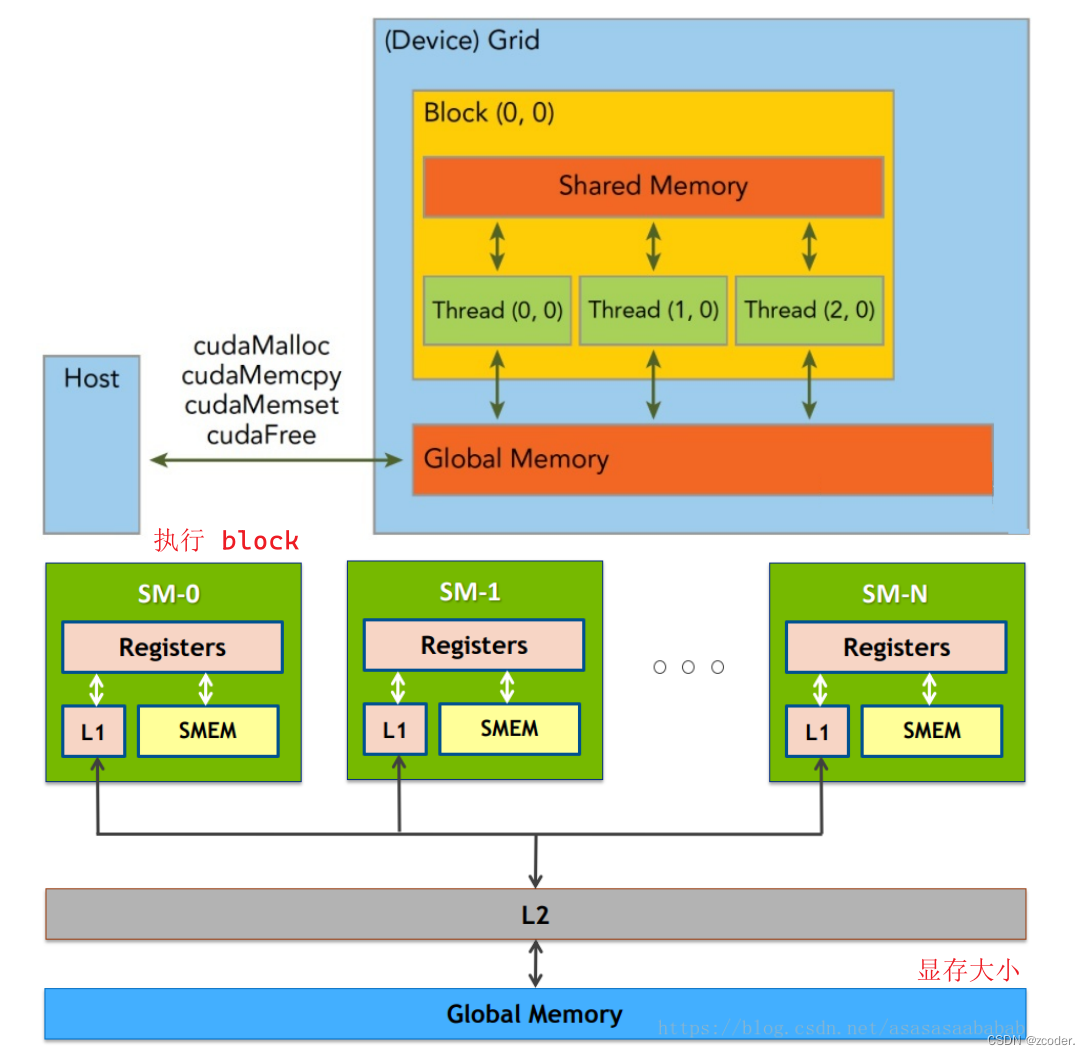
- 一个 GPU 包含多个 SM(Streaming Multiprocessor),而每个 SM 又包含多个 core。
- 一个 block 只能调度到一个 SM 上运行,直到 block 运行完毕。
- 一个 SM 可以同时运行多个 block,因为有多个 core。
- 每个 block 以 warp(一般为 32 个线程或 64 个线程)作为一次执行的单位(真正的同时执行)。
- 在具体的硬件执行中,一个 core 会同时执行 warp,一个 block 会被绑定到一个 core 上,即使这个 block 内部可能有 1024 个线程,这些线程组会被相应的调度器来进行调度,在逻辑层面上可以认为 1024 个线程同时执行,但在硬件上是 warp 同时执行,这一点其实和操作系统的线程调度是一样的
- 假如一个 core 同时能执行 64 个线程,但一个 block 有 1024 个线程,那这 1024 个线程会分 16 次执行。
- 显存层面:一个 block 内的 thread 共享一块 share memory(一般是 SM 的一级缓存)。GPU 和 CPU 一样有着多级 cache 、寄存器的架构,把全局显存的数据加载到共享显存上再处理可以有效地加速。
四、Grid、Block、Thread 的关系
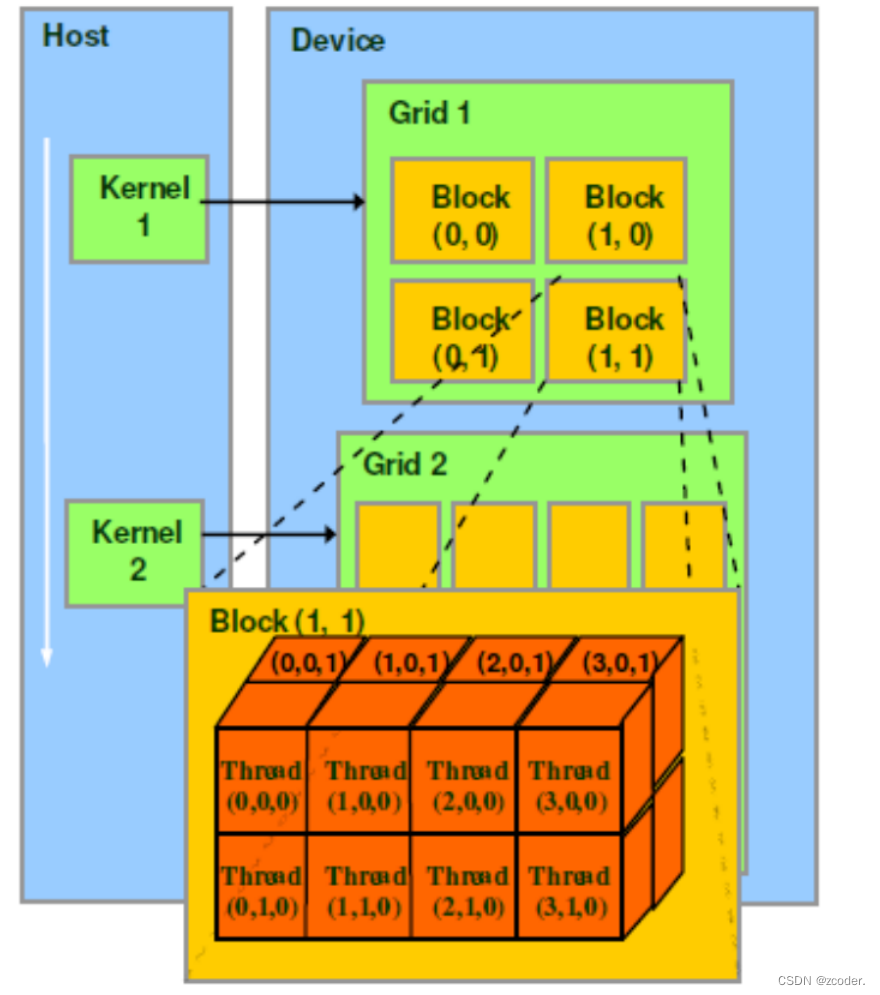
- CUDA 中线程分成三个层次:线程、线程块、线程网格。
- 线程:CUDA 中的基本执行单元,由硬件支持、开销很小,每个线程执行相同的代码。
- 线程块(Block):若干线程的分组,Block 内的一个块至多 512 个线程,或 1024 个线程(根据不同的 GPU 规格),线程块可以是一维、二维或者三维的,同一个 block 中的 threads 可以同步,也可以通过 share memory 通信。
- 线程网格(Grid):若干线程块的网格。
- CUDA 中每一个线程都有一个唯一的标识 ID —
ThreadIdx。threadIdx是一个 uint3 类型,表示一个线程的索引。blockIdx是一个 uint3 类型,表示一个线程块的索引,一个线程块中通常有多个线程。blockDim是一个 dim3 类型,表示线程块的大小。gridDim是一个 dim3 类型,表示网格的大小,一个网格中通常有多个线程块。
- grid 划分成 1 维,block 划分为 1 维:
int threadId = blockIdx.x * blockDim.x + threadIdx.x; - grid 划分成 1 维,block 划分为 2 维:
int threadId = blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x; - grid 划分成 1 维,block 划分为 3 维:
int threadId = blockIdx.x * blockDim.x * blockDim.y * blockDim.z + threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x; - grid 划分成 2 维,block 划分为 1 维:
int blockId = blockIdx.y * gridDim.x + blockIdx.x; int threadId = blockId * blockDim.x + threadIdx.x; - grid 划分成 2 维,block 划分为 2 维:
int blockId = blockIdx.x + blockIdx.y * gridDim.x; int threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x; - grid 划分成 2 维,block 划分为 3 维:
int blockId = blockIdx.x + blockIdx.y * gridDim.x; int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x; - grid 划分成 3 维,block 划分为 1 维:
int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * blockDim.x + threadIdx.x; - grid 划分成 3 维,block 划分为 2 维:
int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x; - grid 划分成 3 维,block 划分为 3 维
int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









