






 本文探讨了利用图神经网络改进玉米作物品种与土地适宜性的评估,通过收集大量数据并构建模型,实现高精度的品种推荐,有助于提高粮食生产效率和育种决策。
本文探讨了利用图神经网络改进玉米作物品种与土地适宜性的评估,通过收集大量数据并构建模型,实现高精度的品种推荐,有助于提高粮食生产效率和育种决策。
论文:Suitability Evaluation of Crop Variety via Graph Neural Network
关键词:智慧农业、玉米作物适宜性、人工智能应用、图神经网络
 https://www.hindawi.com/journals/cin/2022/5614974/
https://www.hindawi.com/journals/cin/2022/5614974/核心思想:利用图神经网络来建模土地与作物品种之间的适宜性,实现较好的品种推荐结果。
三个贡献:
-
我们收集了大量与品种适应性相关的数据,缓解了当前领域数据集稀缺的困难。
-
将图神经网络模型引入品种适宜性评价中,取得了较好的评价结果。
-
试验结果可为今后的育种方案提供参考,提高育种效率。
摘要
随着全球人口的不断增长,粮食生产不足已成为大多数国家亟待解决的问题。目前,利用人工智能技术改善土地与作物品种之间的适宜性以提高作物产量已成为农业研究者的共识。然而,在现有的工作中仍然存在许多问题,如作物表型数据有限,人工智能模型性能不佳。为此,我们以玉米为例,在多个试验点收集了大量的环境气候和作物表型性状数据,构建了广泛的数据集。然后,引入图神经网络模型学习作物适宜性评价,最终获得较好的评价结果。该模型的评价结果不仅可以为专家评价提供参考,还可以根据当前试验点的数据判断该品种是否适合其他试验试验点,从而指导今后的育种试验。
Introduction
作物品种适宜性评价是指作物品种生长对相应种植用地的适宜性。各地土壤条件和气候环境差异较大,不同作物品种的适宜性差异较大。选择合适的品种进行种植,最大限度地利用有限的土地资源,生产更多的粮食。受新型冠状病毒肺炎疫情爆发、气候变化、自然灾害频发等诸多因素影响,近年来世界粮食安全形势更加严峻,可能导致全球饥饿人口进一步增加。在这方面,近年来世界粮食安全形势日趋严峻,导致全球饥饿人口进一步增加,因此,未来的作物品种可以准确地种植在合适的土地上,以提高粮食产量。
气候变化将持续影响作物的整个生长期,对作物品种的适宜性评价有很大影响。长期的气候变化导致淡水资源的大规模重新分配,从而导致作物育种的变化[1,2]。文献b[3]指出,未来几年由于气候变化,农作物的总产量将会下降,这与全球人口不断增长的粮食需求是巨大的矛盾。为缓解这一矛盾,需要积极探索气候变化与作物品种适应性的关系,优化土地资源利用。
作物表型性状是作物生长与当前土地适宜性的直观表达,是土壤、气候等环境因子与作物品种相互作用的结果。早在DNA和分子标记等技术出现之前,基于作物表型的作物品种选择就已经较为系统。即使是相同的作物和基因,在不同的环境中也会产生不同的表型。最终,作物收成是表型数据,而不是基因组数据。因此,直接研究和分析作物表型是最自然、最有效的方法。然而,最大的问题是表型数据不足以支持广泛的数据分析。
作物适宜性评价一直是农业生产中的一大难题,但目前采用的评价分析方法较为陈旧,评价精度较低。现有的大多数方法都是基于传统的机器学习方法。该方法将每条数据视为一个独立的样本,缺乏对数据之间关系的探索。后来深度学习的引入使模型在非线性拟合方面更加强大,但仍然无法模拟数据之间的高阶相关性。
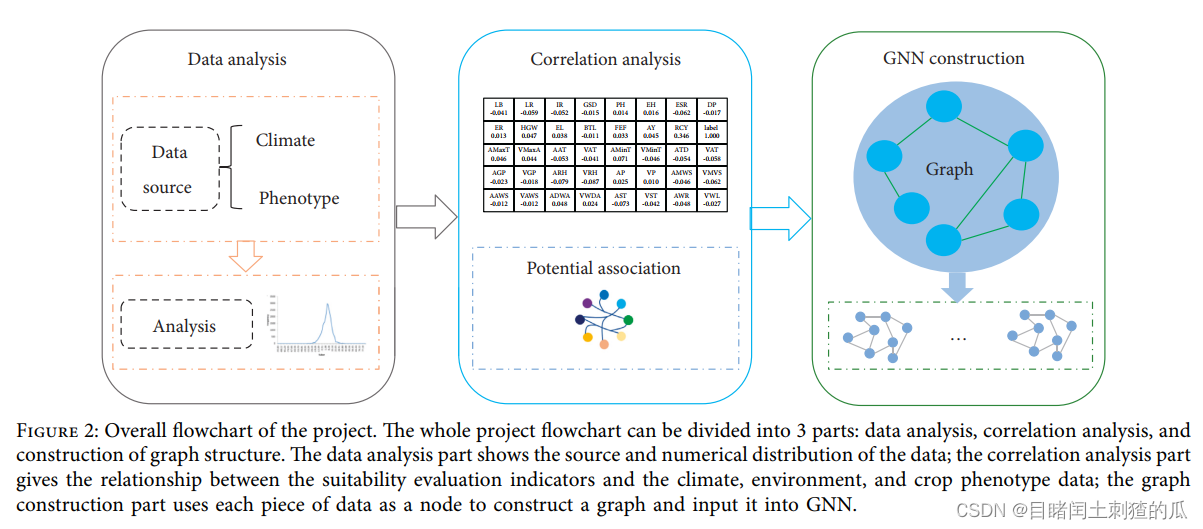
由于缺乏品种适宜性评价数据集,我们收集了近5年(2017-2021年)多个育种点的作物品种性状数据和环境气候数据,共10000条记录。每条记录包括15条性状数据和24条气候数据,请专家进行相应的适宜性评价,请专家进行相应的适宜性评价。考虑到作物表型性状与气候数据之间的高阶复杂相关性[4-6],我们将气候数据纳入学习适宜性评估中。我们使用图神经网络来学习数据之间的关联表示,最终达到更好的评价精度。总体而言,本文主要包括以下三个贡献:
-
我们收集了大量与品种适应性相关的数据,缓解了当前领域数据集稀缺的困难。
-
将图神经网络模型引入品种适宜性评价中,取得了较好的评价结果。
-
试验结果可为今后的育种方案提供参考,提高育种效率。
Method
Data Collection
根据国家统计局和中国工商研究院的数据,玉米是中国重要的粮食作物之一,其产量超过了水稻和小麦。2021年,全国粮食种植面积6327.5万吨,比上年增加160万吨,增长2.6%。其中,水稻产量2128.5万吨,比上年增长10万吨,增长0.5%;小麦产量1369.5万吨,比上年增长27万吨,增长2.0%;玉米产量2725.5万吨,比上年增加164万吨,增长4.6%。截至2021年12月,中国粮食产量为5805公斤/公顷,与上年持平。在粮食作物中,水稻产量最高,为7113.4公斤/公顷,玉米和小麦产量分别为6291公斤/公顷和5863公斤/公顷。我们的表型数据和气候数据来自中国大陆14个试验点,包括京津冀、东北、华北、黄淮海、西北和西南。评估目标品种和种植地点的适宜性需要大量的实验数据,相应的成本往往是巨大的。
数据介绍
通过近5年作物试验数据的收集整理,我们有10000个表格数据集,每个表格数据集详细描述了某一玉米品种在某一试验点的多个性状,包括叶枯病、倒伏率、倒挂率、灰斑病、株高、穗高、空秆率、持续时间、穗腐病、百粒重、穗长、秃尖长、鲜穗田、亩产量、产量相对变化。接下来,我们将详细介绍每个性状数据集的含义及其对作物的可能影响。
数据预处理
我们进一步处理上述数据,以便将其用于模型训练。数据处理可以简单地分为两个步骤:异常值处理和数据标准化。由于不同试验试验点的环境差异,一些性状没有被正确收集或记录,导致数据中出现一些异常值或缺失值。我们首先手动从数据中过滤出可能的异常值,然后填充这些特征数据的平均值。数据标准化主要是为了解决当前数据索引维度不同的问题。不同的评价指标往往具有不同的维度和维度单位,直接相加不能正确反映不同指标的综合结果。为了消除指标之间的维度影响,需要对数据进行标准化,实现数据集之间的可比性。标准化前后的数据分布可视化如图1所示。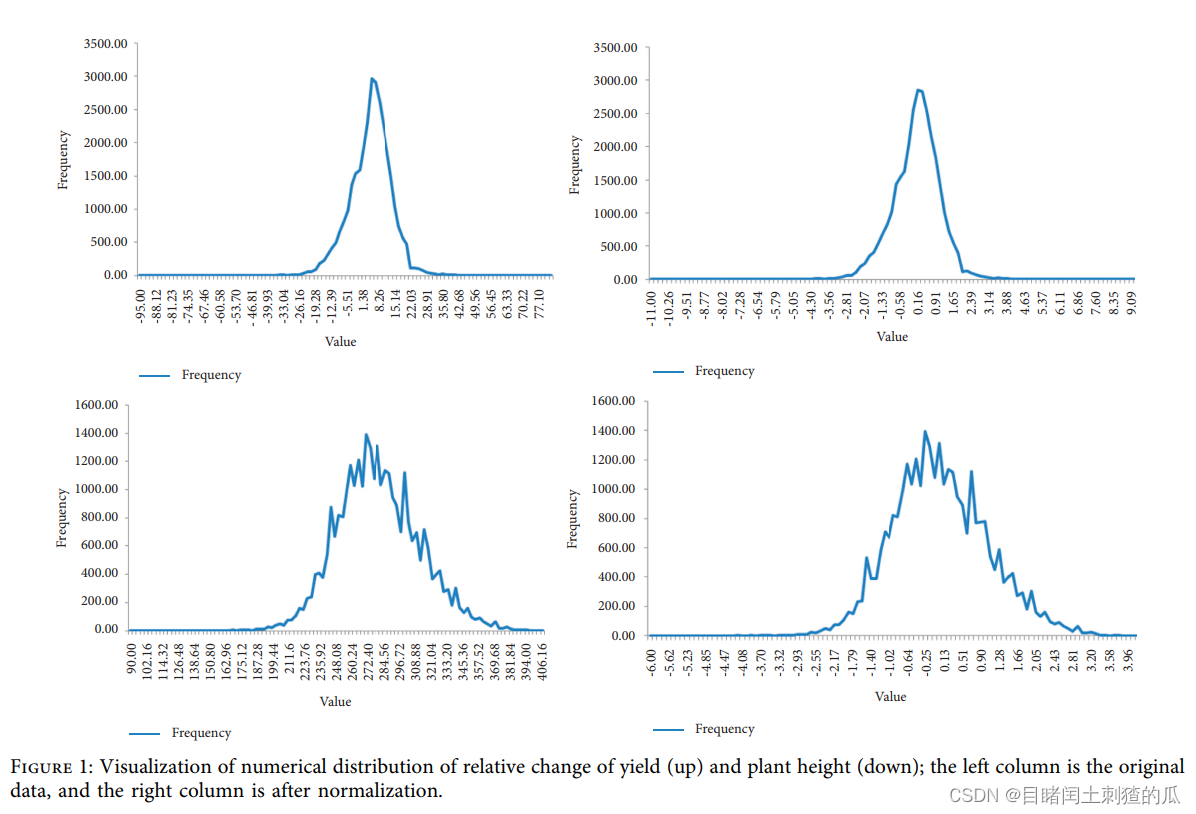
数据相关分析
主要探讨品种适宜性与作物性状与试验场环境气候数据之间的关系。为了进一步了解数据集之间的复杂相关性,我们使用Pearson相关系数来分析数据集之间的相关性。实验数据共有39种,其中气候数据24种,作物性状数据15种。我们首先分析数据集之间的相关性,即39类数据与建议标签之间的关系。推荐品种标签分为终止试验和继续试验两大类。前者表示该作物不适合试验场地,应予以放弃。+e后者表示该品种在试试现场表现良好,可进一步试验或大面积种植。Pearson相关系数用于衡量推荐标签与气候和性状数据之间的相关性,定义为两变量间协方差和标准差的商,如式(1)所示。最后得出的相关结论如表3所示。为了便于查看,我们将更相关的数据进行了简化。

Graph Neural Network Model for Suitability Evaluation
我们把品种适宜性评价作为一项分类任务。与之前基于机器学习和多层感知网络的方法不同,图神经网络可以利用图数据集之间的相关性来进行适用性评估。品种适宜性评价的任务是通过作物的表型数据和试验点的气候环境数据来判断作物和试验点的适宜性。+e输入模型为表格数据,输出最终分类结果。机器学习或多层感知器方法通常不适用于表格数据,由于缺乏适当的归纳偏差,它们无法找到表格决策流形的最优解。其次,由于列之间缺乏强烈的语义关联,基于nlp的方法难以应用。相反,图神经网络可以对数据集之间的相关性进行建模,使用关联对表格数据进行分类。此外,考虑到我们的试验点之间气候和土壤条件分布的巨大差异,引入图神经网络也可以有效地利用试验点之间的地理关系。模型在预测某一试验试验点时,可以结合相邻试验试验点的特征与自身特征相结合,提高预测能力。其次,简要介绍了图神经网络的发展历程,然后描述了图的构造方法,最后对模型的实验结果进行了比较分析。
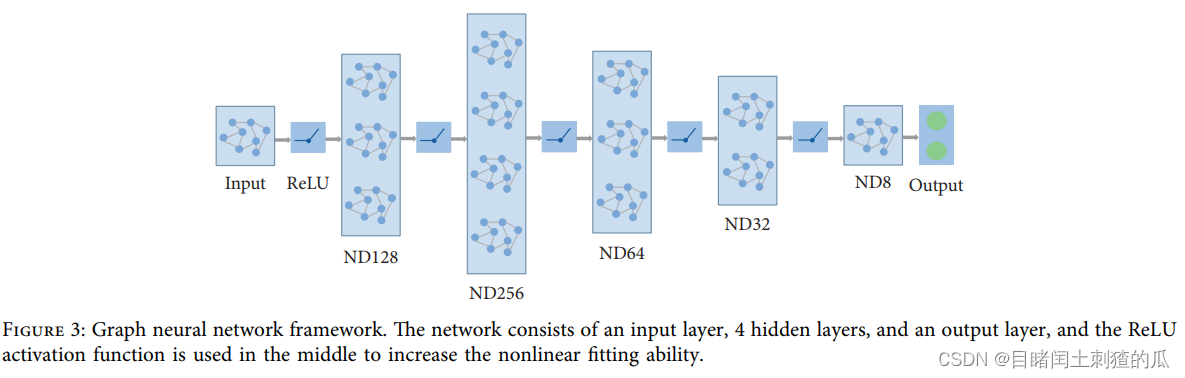
Experiments
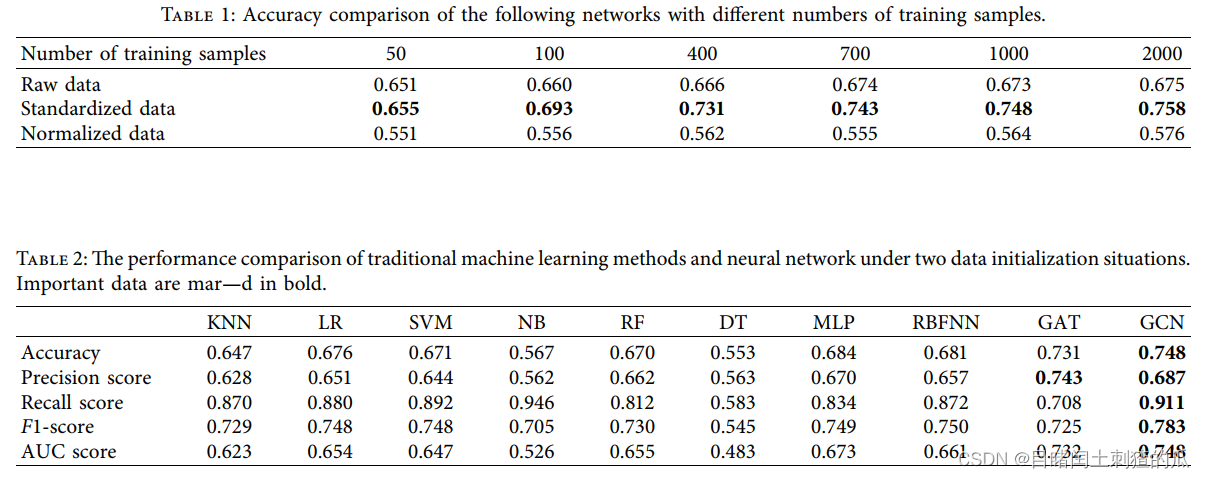
实验结果与分析。与传统神经网络不同的是,图网络需要一次将整个数据集输入到图中,然后指定一个节点作为损失来更新网络参数。因此,对于总共10000个节点,我们分别选择50、100、400、700、1000、2000个节点作为损失来更新网络,结果如表1所示。

Conclusion
随着世界人口的不断增长和政治、商业形势的恶化,粮食生产成为人们关注的焦点。利用人工智能技术提高土地适宜性和品种适应性,从而提高粮食作物产量,已成为农业研究者的共识。利用人工智能技术,收集多个试验点10000个玉米品系的性状和当地气候数据,学习和探索玉米品种与试验点之间的适宜性。在所有人工智能方法中,图神经网络普遍取得了较好的适用性评价结果,仅使用1/10的训练样本就能达到75%的准确率
未来,我们将引入更多与适宜性评价相关的因素,如品种基因序列、土壤成分等,完善现有的智能技术,使人工智能从本质上取代专家评价。此外,在掌握了某一品种在某一试验点的数据后,可以根据该品种的性状数据和当前环境数据,判断该品种是否适合其他试验点。+is可以消除大量被人工智能认为不适合的方案,从而大大降低品种与试验试验点之间的试错成本,加速识别最适合当前试验试验点的品种,最终提高粮食作物的产量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









