







消息中间件是为了应用间的解偶,削峰等,所以我们需要保证消息的可靠。那么如何保证消息的可靠性呢?
正常情况下的可靠性分析
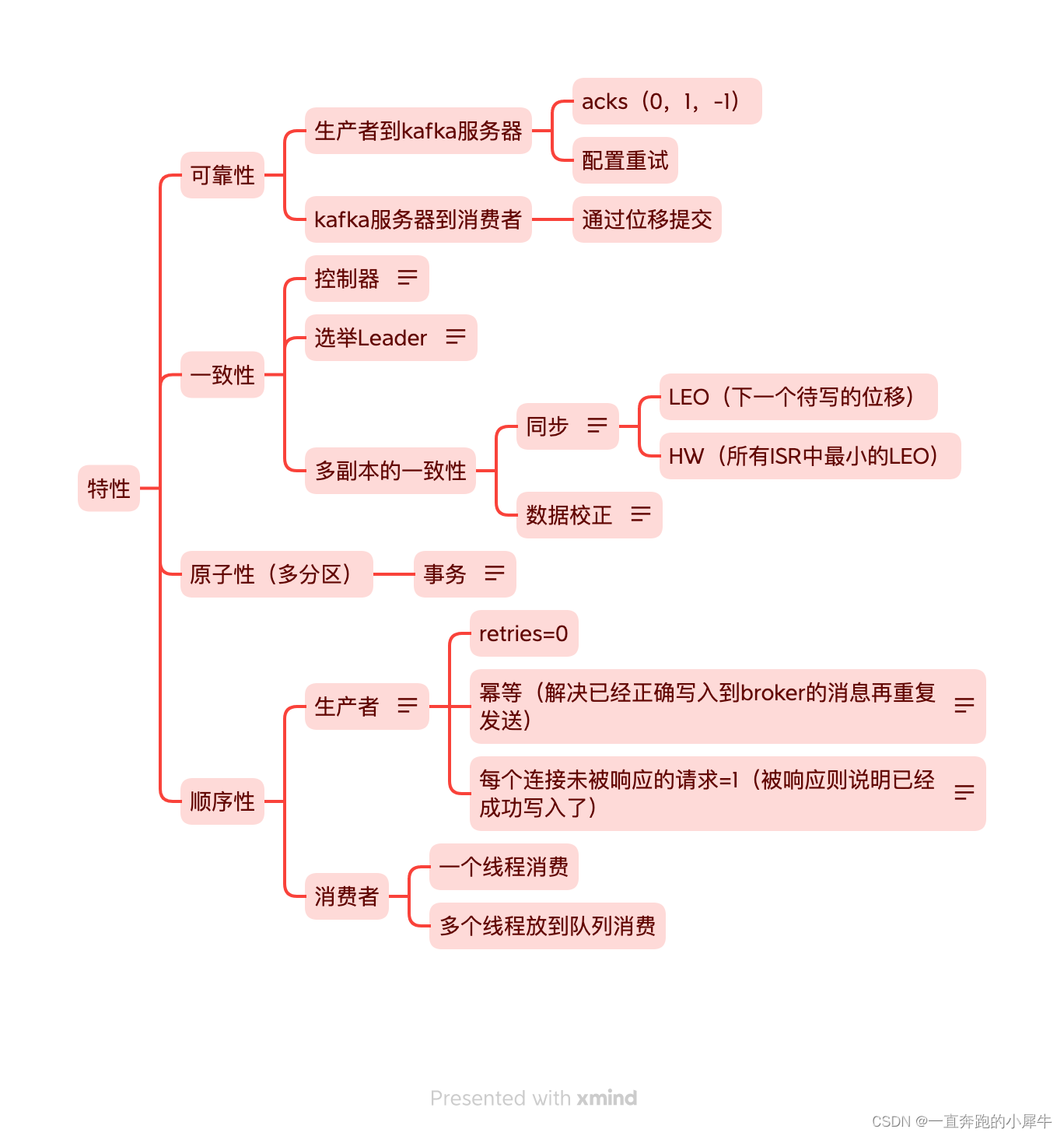
kafka的整体流程基本可以分为:1、生产者生产消息,2、消费者消费成功。消息只有成功经过这两个步骤,才能算作基本可靠。
生产者到Kafka服务器
Kafka的消息存储是多副本机制,Kafka通过acks参数保证副本写入数量。
- acks=0:无需保证任何副本接收到消息,写入失败生产者也无法感知。
- acks=1:Leader副本写入成功。
- acks=-1:所有副本均写入成功。
同时Kafka还可以配置重试次数,对未正常写入到Kafka服务器的消息进行自动重试。
当然我们也可以通过业务系统实现对异常的捕获。
消费者消费Kafka服务器数据
我们知道Kafka是通过位移来定位,保证消息的消费。Kafka的位移信息会保存在Kafka自身的主题中。上文也说到,由于自动位移的提交可能造成消息的消费丢失或者重复消费,所以我们可以通过手动提交位移的方式保证消费的可靠性。
顺序性分析
有些场景需要保证消息的顺序性,即先生产的消息需要先被消费。正常情况下,一个分区内的消息是顺序投递的,但当发生重试时,可能会造成消息的顺序被打乱。
生产者到kafka服务器顺序性
上述讲到消息的顺序可能会被重试打乱,当然我们可以通过设置不允许重试避免这种情况的发生,但是消息投递到服务器失败了会导致消息的丢失,产生业务上的异常。所以该方式一般不可取,所以我们需要通过其他方式维护消息的顺序性。
1、max.in.flight.requests.per.connection=1
该参数代表每个连接允许的未响应的请求。如果未响应的请求达到这个数值,则后续该连接投递消息均会被拒绝。
如果消息投递成功了,kafka服务器会响应成功。那么该值设置为1,此时有消息投递失败,说明这个批次的请求还没有响应。那么后续的消息都不能进行投递,直到该请求被响应或者重试成功。
2、开启幂等
通过enable.idempotence=true参数开启幂等,同时需要保证acks=-1,max.in.flight.requests.per.connection<=5。
幂等:顾名思义,就是保证消息不重复投递。开启幂等功能可以防止消息重试的重复投递。
那么有些人可能会疑惑了,为什么我都重试了,那不就说明server已经接收消息失败了吗,要这个幂等还有什么用?举个例子,server已经落盘了,但是此时server和生产者之间网络断开或者超时,导致生产者再次发送,这时候幂等是不是就显示出它的作用了。
那kafka中幂等是怎么实现的呢?
原理
broker 端会在内存中为每一对<PID ,分区>维护一个序列号。对于收到的每一条消息,只有当它的序列号的值( SN new )比broker 端中维护的对应的序列号的值( SN old )大1 ( 即SN new= SN old + 1 )时,broker 才会接收
- SN new>SN old + 1抛出异常
- SN new<SN old + 1则直接丢弃,说明该数据已经写入broker了
上面也说了,幂等开启的时候,max.in.flight.requests.per.connection参数需要设置<=5的任意数值,那么为什么必须<=5呢?
原因:Server 端的 ProducerStateManager 实例会缓存每个 PID 在每个 Topic-Partition 上发送的最近 5 个 batch 数据。
幂等开启,会查看在ProducerStateManager中是否存在,如果不存在,则会判断seq_no是否连续,这时候就会异常。又会重试。(即直接在校验的时候认为投递失败了)
比如:
我们发送1到6的报文,其中1发送失败,2-5发送成功,Broker缓存下来,当1重试进入服务端,服务端发现没有这个request的这条数据,判断SN是否为SN old+1,不等则异常。
消费者的顺序性
可以通过单线程消费或者多线程放到一个队列中消费。
一致性分析
上述的可靠性都是针对正常情况下,机器不宕机等为前提的。
kafka的broker是多副本的,如果Leader副本宕机,我们如何进行副本的切换?新增机器如何同步数据,机器宕机重启如何保证数据和新的leader一致。
选控制器
上文提到,kafka集群中会有个统一的控制器,该机器负责副本的选举、分区重分配、ISR信息更改的通知等。通过zk选举出kafka的控制器,同时创建另外节点维护控制器的纪元。总体来说,Leader副本的选举和控制器息息相关。
副本选举
kafka采用的是优先副本选举的策略。通过获取分区的AR列表,找到AR列表中最靠前的一台机器,同时该节点需要存活且在ISR列表上。
副本均衡
那么此时会引申出另外一个问题,由于重新选举了Leader副本(该机器新增了作为某些分区的Leader副本的功能),此时副本不是均衡的了。此时可以通过kafka-perferred-replica-election.sh脚本进行副本的重新平衡(可理解为手动换Leader)。
分区重分配
- 当broker上线,只有新的主题的分区会分配到这个broker
- 当broker下线,也会造成数据的倾斜
可以通过kafka-reassign-partitions.sh脚本进行分区的重分配(其实就是数据迁移)或者副本因子的修改。(重分配会导致整体集群的性能,引入了复制限流,限制副本中复制的流量。)
日志同步
分区的副本由多个节点维护。所有节点组成的集合为AR,同步到一定位移的节点为ISR。如果同步信息跟不上生产信息,很可能造成ISR慢慢变少,直至变为0,这时候只有Leader副本是有效数据。节点同步Leader日志,修改自己的LEO(下一个写入的位移),ISR中最小的LEO被称为HW。
日志修正
集群运行过程中,可能会有机器宕机重启。如果Leader副本的机器A写入了数据2,此时宕机,该数据还未同步到其他机器。B又重启,晋升为新的Leader。写入了数据3。当A重启后,怎么将m2数据移除呢??kafka引入了<epoch,startOffset>机制。
每个节点都会维护<epoch,startOffset>,其中epoch为当前Leader节点的纪元,每次选举都会+1;startOffset为当前epoch对应的第一条数据的偏移。
- epoch相等:返回自身的LEO
- epoch不想等:返回自身epoch对应的第一条位移
这里着重讲讲epoch不想等的情况。A节点重启后,会发送带有epoch的请求到新的LeaderB,此时B的epoch和A发送的epoch不想等。则会发送B的epoch对应的首个位移(也就是m3的位置),这时候A根据该位移进行截断。具体过程如下图所示:

大家如果有什么问题,可以公众号交流:程序员猩球















 2953
2953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











