






批量获取淘宝商品详情数据的方法有多种,以下列举几种常见的方式12:
- 使用淘宝开放平台PI接口,通过编程的方式获取淘宝商品数据,需要一定的技术基础和开发能力。
- 使用淘宝数据抓取工具,如八爪鱼等,可以自动化采集淘宝商品数据,并将其转换成CSV、Excel等格式,方便后续处理和分析。
- 寻找第三方服务,如果不想使用数据抓取工具,那么可以寻找一些第三方服务。这些服务提供了批量采集淘宝商品数据的功能,只需要提供相关的参数和条件,就可以获得需要的数据。但使用第三方服务需要谨慎选择,要选择正规、可信的服务商。
淘宝商品详情数据采集的步骤如下:
- 确定采集目标:明确要采集的商品信息,如商品标题、价格、销量、评论、图片等。
- 选择采集工具:可以选择Scrapy框架、Java的WebMagic框架等。
- 编写爬虫程序:在选择好采集工具后,需要编写爬虫程序,定义爬虫的起始URL、解析规则、数据存储等内容。
- 解析HTML页面:在爬虫文件中,需要使用XPath或BeautifulSoup等工具,解析淘宝商品详情页面的HTML代码,提取出需要的商品信息。
- 存储数据:将采集到的数据存储到数据库、CSV等形式中,以备后续数据分析使用。
同时,在采集淘宝商品详情信息时,需要注意反爬虫策略,如使用代理IP、设置延时等,以避免被封禁。
taobao.item_list_weight-批量获取淘宝天猫商品信息 API 返回值说明
1.公共参数
| 称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中,演示demo示例) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本(复制薇:Taobaoapi2014 获取API SDK文件) |
2.请求示例
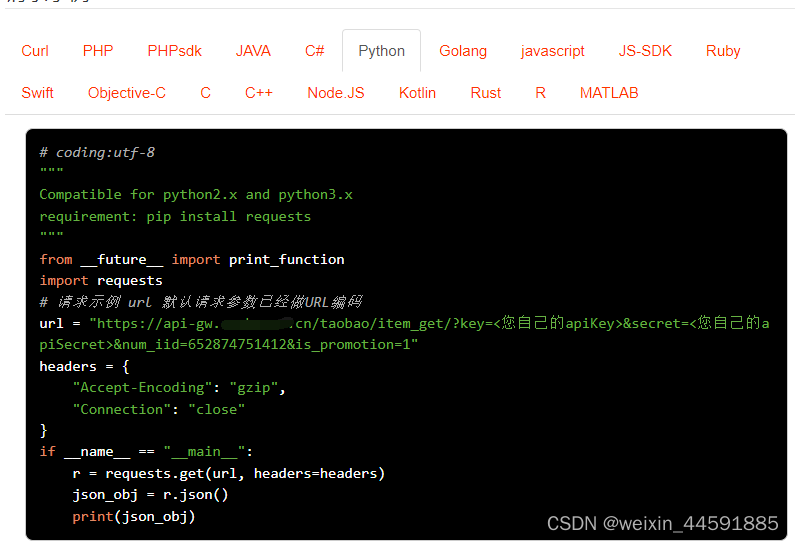
3.响应示例
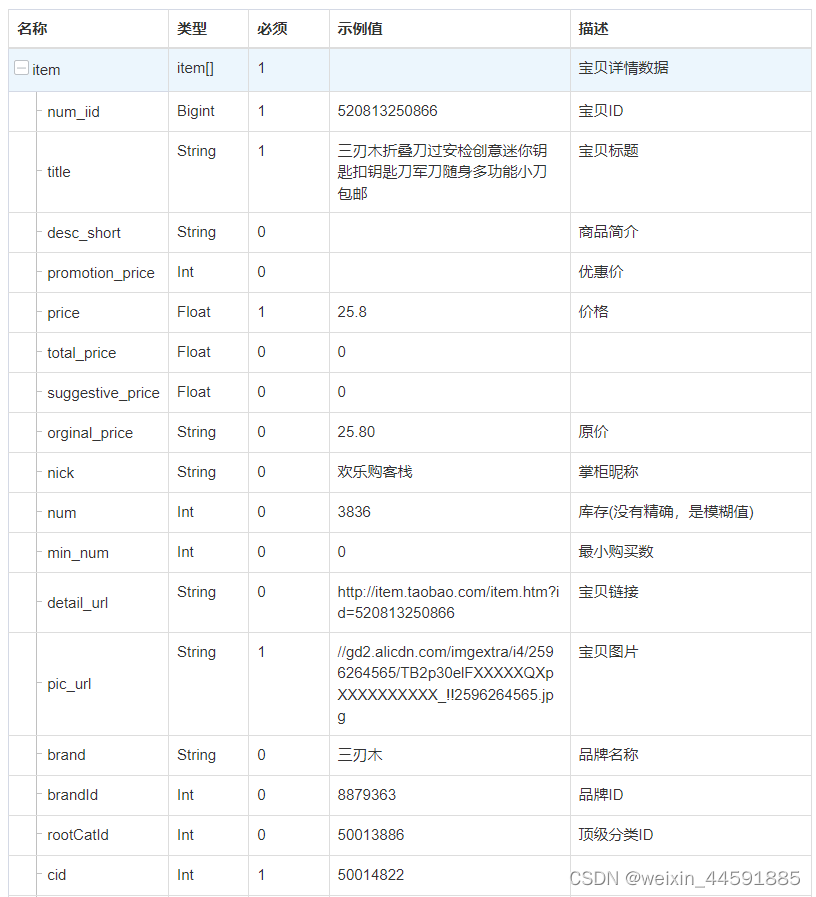
批量获取淘宝商品详情数据有很多用途,以下列举几个常见用途:
- 商业用途:通过采集淘宝上的商品信息,可以进行商品比价、价格监控、市场调研等商业用途。
- 数据分析:采集淘宝上的商品信息,可以进行数据分析,比如热销商品排行、价格波动分析等。
- 竞品分析:通过采集竞品的商品信息,可以进行竞品分析,了解竞争对手的产品特点,制定更好的产品策略。
- 营销推广:采集淘宝上的商品信息,可以进行商品推广,比如通过社交媒体分享、SEO等方式,提高商品的曝光度和销售量。

















 2379
2379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









