







一、什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
- 弹性:
① 存储的弹性:内存与磁盘的自动切换;
② 容错的弹性:数据丢失可以自动恢复;
③ 计算的弹性:计算出错重试机制;
④ 分片的弹性:可根据需要重新分片。 - 分布式:数据存储在大数据集群不同节点上
- 数据集:RDD 封装了计算逻辑,并不保存数据
- 数据抽象:RDD 是一个抽象类,需要子类具体实现
- 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
- 可分区、并行计算
二、RDD和IO之间的关系
- RDD的数据处理方式类似于IO流,也有装饰者设计模式
- RDD的数据只有在调用collect方法时,才会真正执行业务逻辑操作。前面所做处理的封装都是功能的扩展
- RDD是不保存数据的,而IO可以临时保存一部分数据
三、RDD的五个主要属性
源码注释
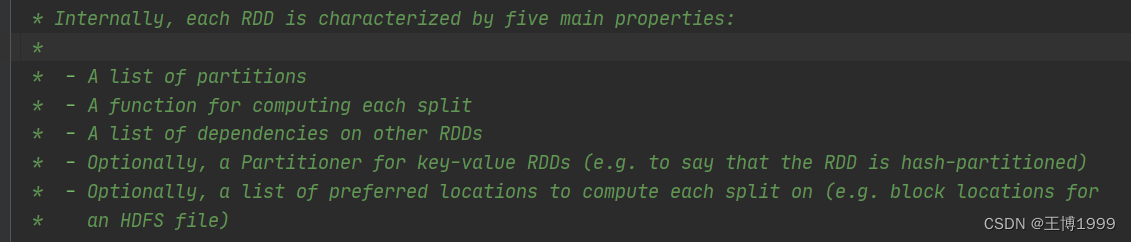
1.分区列表:RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性
protected def getPartitions: Array[Partition]
2.分区计算函数:Spark 在计算时,是使用分区函数对每一个分区进行计算
def compute(split: Partition, context: TaskContext): Iterator[T]
3.RDD 之间的依赖关系:RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系
protected def getDependencies: Seq[Dependency[_]] = deps
4.分区器(可选):当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区
@transient val partitioner: Option[Partitioner] = None
5.首选位置(可选):计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
四、读取文件的方式
第一种:sc.textFile(路径)
参数:以行为单位,可以是文件的相对路径,也可以是绝对路径,也可以是文件目录(如果是目录,会对目录中所有的文件进行统计)
第二种:sc.wholeTextFiles(路径)
参数:以文件为单位读取数据,读取的结果表示为元组,元组中第一个元素为文件的路径,第二个元素为文件的内容
五、RDD的并行度和分区
在资源充足的情况下,如分配5个分区,那么这个五个分区就可以并行计算执行
情况一:在创建RDD时,使用makeRDD的方法,spark分区是怎么分的(其中可以传递第二个参数指定分区数量,也可以不传,会分配默认分区。)
默认分区会怎么分呢?
源码中会调用这样一段代码:
scheduler.conf.getInt("spark.default.parallelism",totalCores)
spark在默认情况下,会从SparkConf配置对象中获取配置参数:spark.default.parallelism
如果不配置,就获取不到,那么使用totalCores属性,这个属性取值为当前运行环境的最大可用核数(比如说本地运行环境,电脑为四核,那么默认就会分4个分区)
如果配置spark.default.parallelism参数
代码如下:
val sparkConf = new SparkConf().setMaster("local").setAppName("RDD")
sparkConf.set("spark.default.parallelism","5")
spark.default.parallelism的值就为5,那么就会分为5个分区
数据又是如何存储在分区中的呢?
情况二:在读取文件时,数据的分区是多少,以及数据是如何分配的不同分区当中的。(其中可以传递第二个参数指定分区数量,也可以不传,会分配默认分区。)
默认分区会怎么分呢?
源码中默认会有一个最小分区数量:minPartitons,如果在本地运行环境下电脑核数小于2,那么默认分区就算该电脑的核数,如果核数大于2,那么分区数量就是2
指定分区数量和makeRDD不同,他有自己的计算方式
他会读取该文件的字节数,然后除以你传的第二个参数取整,得到一个数值,该数值就是一个分区所放的字节数,最后就会按照总的字节数 分若干个分区
如:文件内容为7个字节,设置两个分区,那么最终的分区数就是3
7/2=3 ,一个分区放三个字节,那么就算三个分区数
数据又是如何存储在分区中的呢?
六、RDD分区间数据的执行顺序
rdd的计算一个分区的数据时一个一个的执行逻辑,只有前面一个数据全部的逻辑执行完毕后,才会执行下一个数据,所以说分区内数据的执行时有序的,而不同分区之间数据的计算是无序的
















 793
793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











