






已安装tesseract-ocr-w32-setup-v4.0.0.20181030.exe(tesseract下载地址),已配置系统环境,python已下载pytesseract模块,
运行程序时仍报错:pytesseract.pytesseract.TesseractError: (1, 'Error opening data file C:\\Program Files (x86)\\Tesseract-OCR/chi_sim.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'chi_sim\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
有可能是你没有安装中文包‘chi_sim’
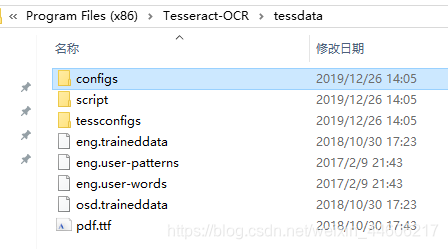
可以通过tessdata目录查看是否安装中文包,如下图则为未安装
各版本语言包下载路径:
https://github.com/tesseract-ocr/tesseract/wiki/Data-Files
由于我安装的tesseract-ocr是4.0版本的,所以这里下载的中文包是4.0的
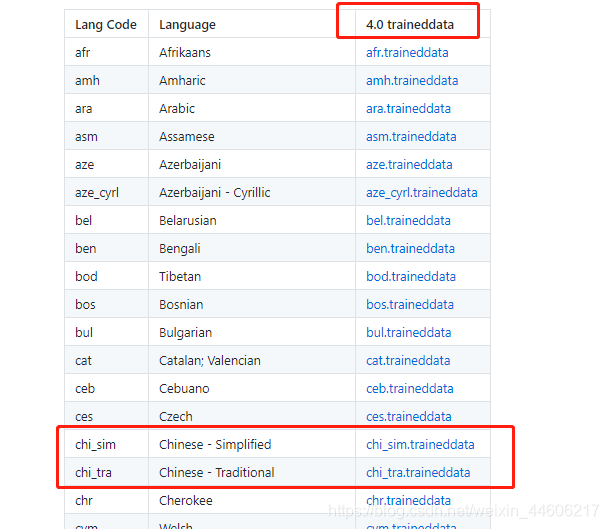
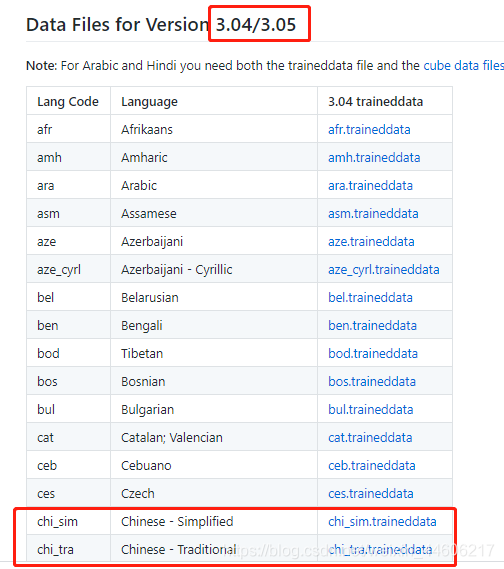
继续往下翻还有别的版本对应的语言包,按需所取
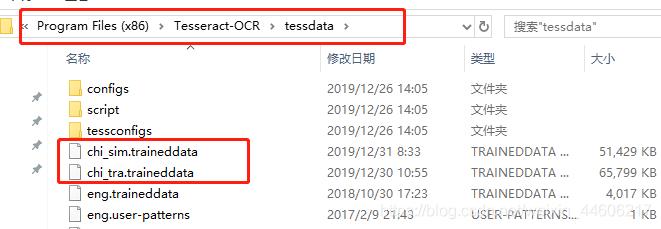
下载好以后,把中文包放置在tessdata目录下即可。

















 1664
1664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









